







 超级会员免费看
超级会员免费看
 本文介绍了如何使用MapReduce的MapJoin技术处理大数据问题,避免因数据倾斜导致的性能瓶颈。MapJoin将小表加载到内存,通过Map阶段完成数据合并,减少Reduce阶段的压力,确保任务正常运行。文中详细阐述了MapJoin的工作原理,并提供了实现步骤,包括在Map阶段加载小文件到内存、设置Job的reduce任务数量为0,以及在Mapper的setup和map方法中如何操作。
本文介绍了如何使用MapReduce的MapJoin技术处理大数据问题,避免因数据倾斜导致的性能瓶颈。MapJoin将小表加载到内存,通过Map阶段完成数据合并,减少Reduce阶段的压力,确保任务正常运行。文中详细阐述了MapJoin的工作原理,并提供了实现步骤,包括在Map阶段加载小文件到内存、设置Job的reduce任务数量为0,以及在Mapper的setup和map方法中如何操作。

然后我们再来看一下mapJoin,可以看到我们还是来实现我们用reduceJoin实现的功能,但是
我们这次不在reduce阶段去处理合并结果,为什么呢?
比如如果我们的这个order.txt文件有2亿条,那么这个时候,我们的maptask可以很多,一个默认
处理128m的数据对吧,但是我们的reduce只有一个对吧,如果我们不做自定义分区的话,那么就一个
reducetask,那么这个时候可能这个reducetask就因为数据量太大,两亿条,都集中在一个reducetask中处理,这个reducetask就卡死了.
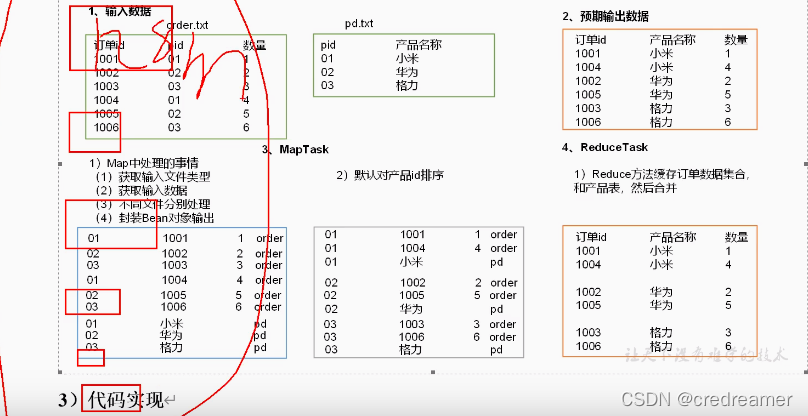
那么我们这个时候怎么解决,我们可以这样,把数据处理阶段,放到maptask中去处理就可以了对吧,
因为我们reducetask,虽然默认只有一个,但是我们的maptask可以有很多对吧,而且每个只默认处理
128m的数据,数据量大也不至于卡死.

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











