







 超级会员免费看
超级会员免费看
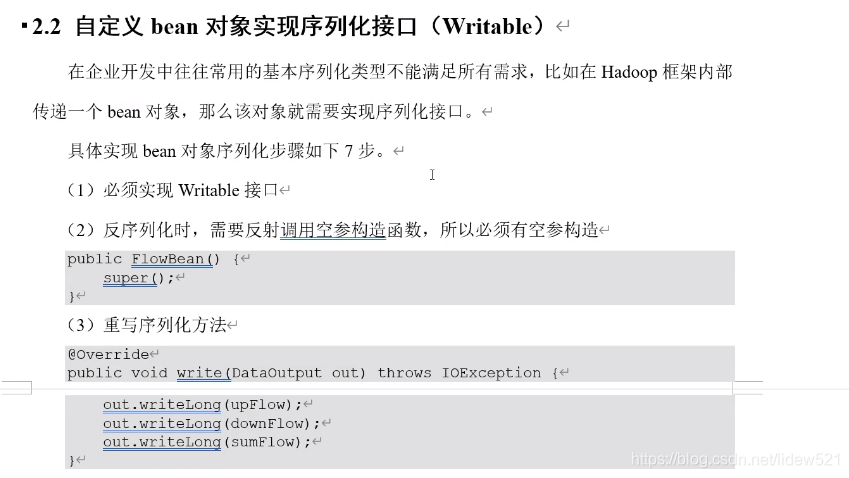
 本文介绍了如何使自定义类在Hadoop MapReduce中实现序列化和反序列化,需要实现Writable接口并确保序列化顺序一致。同时,如果自定义类型作为Key使用,还需要实现Comparable接口以支持Hadoop的默认排序功能。通过Text类型的例子,展示了Hadoop内置类型如何同时实现Writable和Comparable接口。
本文介绍了如何使自定义类在Hadoop MapReduce中实现序列化和反序列化,需要实现Writable接口并确保序列化顺序一致。同时,如果自定义类型作为Key使用,还需要实现Comparable接口以支持Hadoop的默认排序功能。通过Text类型的例子,展示了Hadoop内置类型如何同时实现Writable和Comparable接口。
前面我们说了java的序列化和hadoop的序列化的区别,现在我们再来看,
我们如果让我们自己写的一个类,我们自己的数据,通过网络传输到hadoop集群的
不同的机器上,这样我们自己写的类就需要,实现hadoop的序列化才行,那么
怎么实现呢
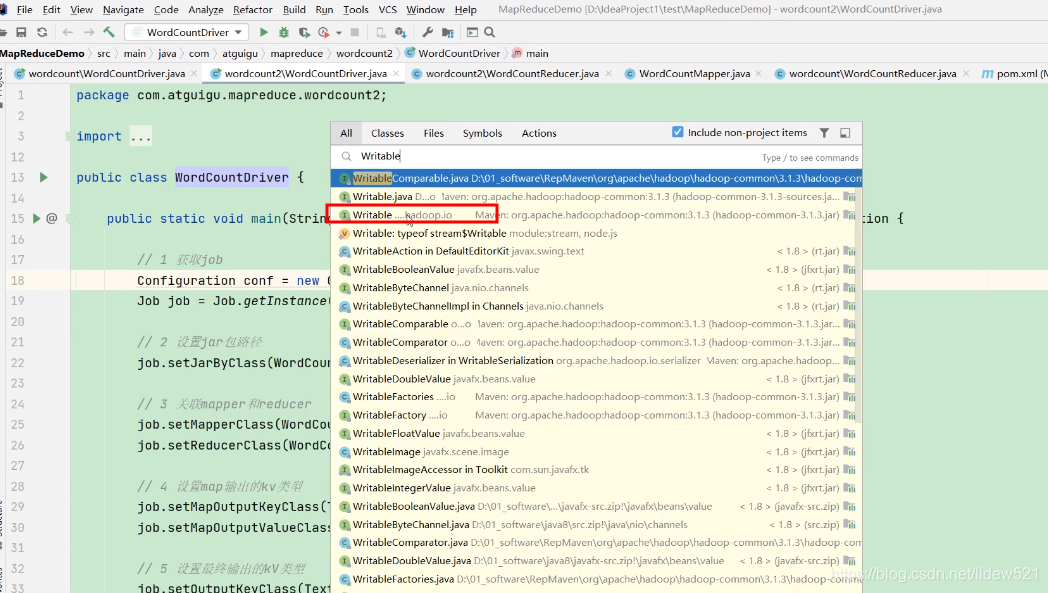
我们去看看,我们去找到IntWritable这个类的祖宗类,可以看到有个
Writable这个接口,我们打开看看
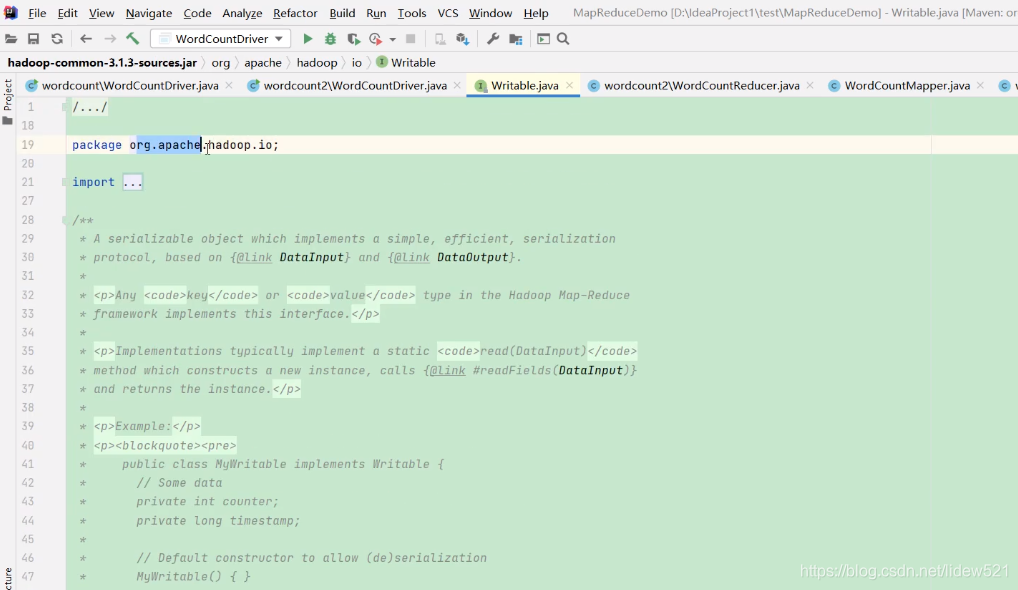
可以看到这个类是在org.apache.hadoop.io这个包下面的对吧。
前面我们说了java的序列化和hadoop的序列化的区别,现在我们再来看,
我们如果让我们自己写的一个类,我们自己的数据,通过网络传输到hadoop集群的
不同的机器上,这样我们自己写的类就需要,实现hadoop的序列化才行,那么
怎么实现呢
我们去看看,我们去找到IntWritable这个类的祖宗类,可以看到有个
Writable这个接口,我们打开看看
可以看到这个类是在org.apache.hadoop.io这个包下面的对吧。

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























