







 超级会员免费看
超级会员免费看
 本文通过一个案例详细解析了如何在Hadoop3.x中实现MapReduce进行手机号流量统计,包括数据输入、Mapper和Reducer的处理逻辑,以及为什么需要实现序列化接口。Mapper将原始数据转换为手机号与Bean对象,Reducer进行聚合统计,输出最终结果。整个流程中,序列化接口用于数据在集群间传输时的字节码转换。
本文通过一个案例详细解析了如何在Hadoop3.x中实现MapReduce进行手机号流量统计,包括数据输入、Mapper和Reducer的处理逻辑,以及为什么需要实现序列化接口。Mapper将原始数据转换为手机号与Bean对象,Reducer进行聚合统计,输出最终结果。整个流程中,序列化接口用于数据在集群间传输时的字节码转换。
然后我们来通过一个案例,来写下实现hadoop序列化的业务实体类
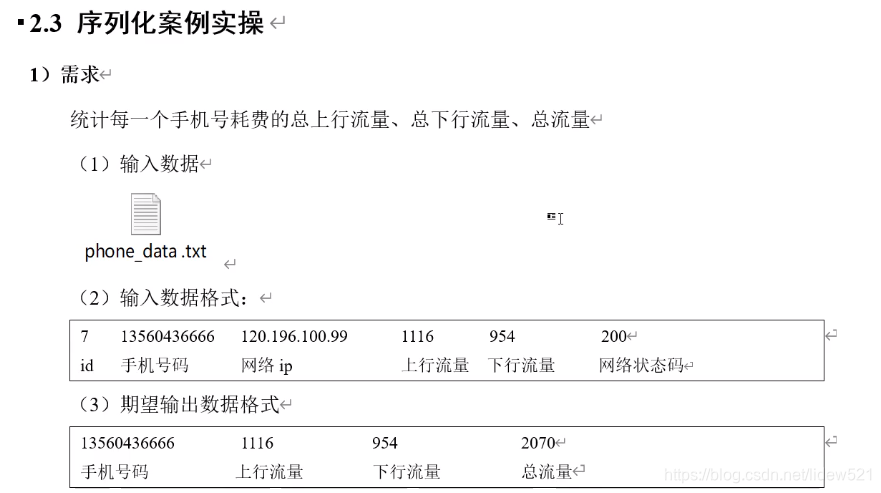
可以看到我们要统计每个手机号的耗费的总上行流量,总下行流量,以及总流量
可以看到我们有输入数据的文件
有输入数据的格式,以及期望输出的数据结果的格式
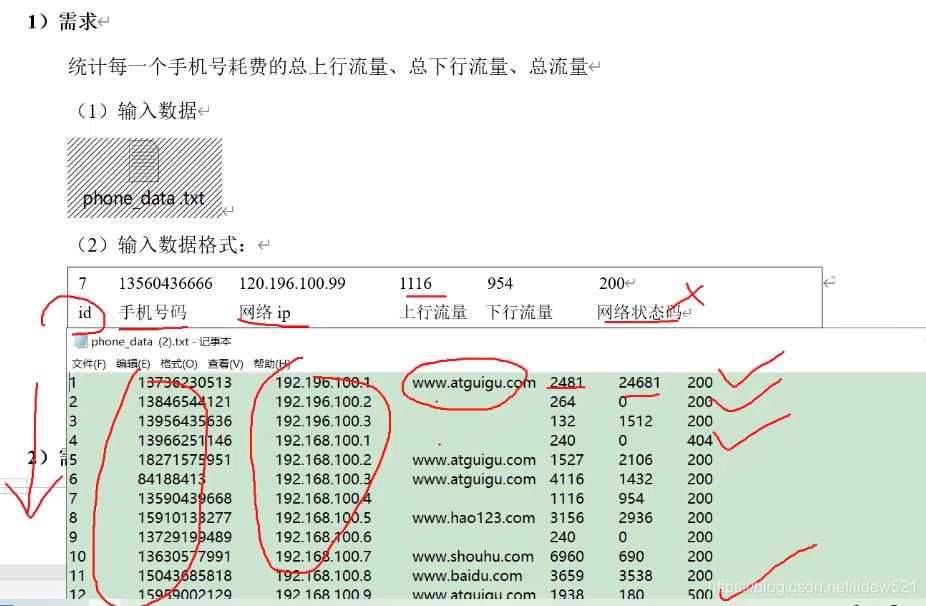
可以看到我们打开看看,可以看到,字段是
id,手机号,网络ip,上行流量,以及下行流量,网络状态码

可以看到上面的期望输出数据格式
有手机号,以及这个手机号,使用了的总的上行流量,总的下行流量,以及使用的总流量
总流量是 总的上行流量 加上 总的下行流量
然后我们来通过一个案例,来写下实现hadoop序列化的业务实体类
可以看到我们要统计每个手机号的耗费的总上行流量,总下行流量,以及总流量
可以看到我们有输入数据的文件
有输入数据的格式,以及期望输出的数据结果的格式
可以看到我们打开看看,可以看到,字段是
id,手机号,网络ip,上行流量,以及下行流量,网络状态码
可以看到上面的期望输出数据格式
有手机号,以及这个手机号,使用了的总的上行流量,总的下行流量,以及使用的总流量
总流量是 总的上行流量 加上 总的下行流量

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























