







 超级会员免费看
超级会员免费看
 本文介绍了Hadoop中的序列化和反序列化过程,对比了Hadoop序列化与Java序列化在效率和数据包大小上的差异。Hadoop的序列化机制减少了数据包大小,提高了数据传输速度。
本文介绍了Hadoop中的序列化和反序列化过程,对比了Hadoop序列化与Java序列化在效率和数据包大小上的差异。Hadoop的序列化机制减少了数据包大小,提高了数据传输速度。

然后我们再来看一下hadoop中的序列化,可以看到
序列化其实就是把内存中的对象,比如我们一个user对象,转换成字节码序列对吧,
这个字节码,其实就一个一个的byte,这样的数据就可以存到磁盘上了,并且也可以
在网络中进行传输了。
而反序列化就是把存在磁盘上的user对象,再通过反序列化转换过来成一个user对象,
加载到内存中使用对吧。这样就完成了序列化和反序列化
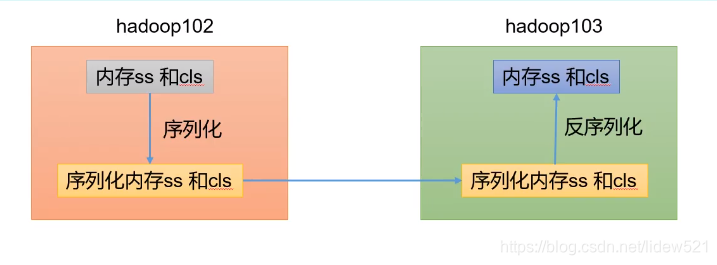
我们去看看hadoop的这个序列化和反序列化的过程。
可以看到比如我们有个hadoop102,hadoop103这两个集群中的机器,我们
有个ss字符串,有个cls字符串,这两个字符串,现在在hadoop102内存中,然后
如果我们需要把ss,cls这个两个字符串传输到龄一个hadoop103机器上
这个时候,我们需要先把ss,cls这两个内存中的字符串,转换成字节码,比如
转换成一个个的byte数据,这个过程是序列化,然后这个byte数据,就可以存在
磁盘上了,也可

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











