



原文地址:Improving retrieval using Hypothetical Document Embeddings(HyDE)
2023 年 11 月 5 日
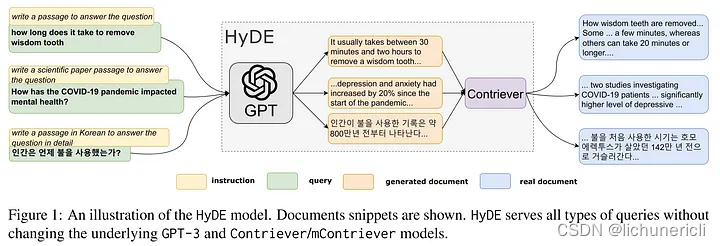
什么是HyDE?
HyDE 使用一个语言学习模型,比如 ChatGPT,在响应查询时创建一个理论文档,而不是使用查询及其计算出的向量直接在向量数据库中搜索。
它更进一步,通过对比方法学习无监督编码器。这个编码器将理论文档转换为一个嵌入向量,以便在向量数据库中找到相似的文档。
它不是寻求问题或查询的嵌入相似性,而是专注于答案到答案的嵌入相似性。
它的性能非常稳健,在各种任务(如网络搜索、问答和事实核查)中的表现与经过良好调整的检索器相匹配。
它的灵感来源于论文Precise Zero-Shot Dense Retrieval without Relevance Labels
为什么需要LLM生成假设性回答?
在面对缺乏具体性或缺乏易于识别的元素从给定上下文中推导答案的问题时,有时候会相当具有挑战性。
例如,考虑必胜客(Pizza Hut)连锁餐厅的情况,它通常以销售食物而闻名。然而,如果有人询问必胜客最好的菜品是什么,这个问题暗示了对食物的关注。这里的难点在于没有指定具体的食物项。因此,寻找洞察力变得有困难。为了解决这个问题,我们利用语言模型(LLM)的帮助来编写一个假设性的答案,然后将其转化为嵌入向量。这些嵌入向量然后在向量存储库中根据语义相似性进行检查,以帮助寻找相关信息。
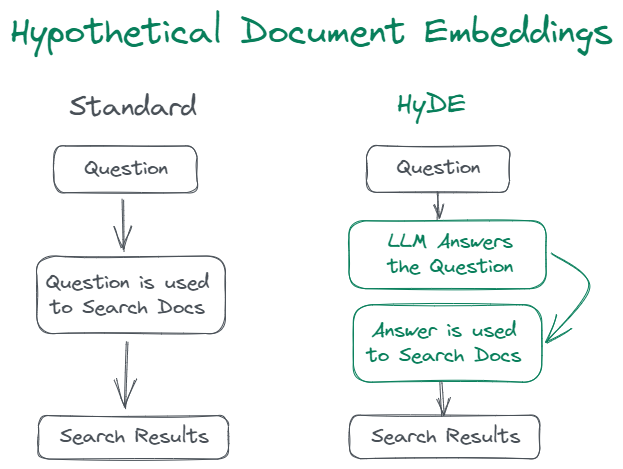
HyDE 利用 LLM(GPT3)的帮助创建一个“假设性”答案,然后搜索嵌入向量以找到匹配项。在这里,我们进行比较的是答案到答案的嵌入相似性搜索,而不是传统 RAG 检索方法中的查询到答案的嵌入相似性搜索。
然而,这种方法有一个缺点,即它可能无法始终如一地产生良好的结果。例如,如果讨论的主题对语言模型来说完全陌生,这种方法就无效了,可能会导致生成错误信息的次数增加。
实现HyDE
安装所需的依赖项
!pip -q install langchain huggingface_hub openai chromadb tiktoken faiss-cpu
!pip -q install sentence_transformers
!pip -q install -U FlagEmbedding
!pip -q install -U cohere
!pip -q install -U pypdf导入已安装的依赖项
from langchain.llms import OpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import LLMChain, HypotheticalDocumentEmbedder
from langchain.prompts import PromptTemplate
from langchain.vectorstores import FAISS
from langchain.document_loaders.pdf import PyPDFDirectoryLoader
from langchain.document_loaders import TextLoader
from langchain.embeddings import HuggingFaceBgeEmbeddings
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
import langchain设置所需的API密钥
from getpass import getpass
os.environ["COHERE_API_KEY"] = getpass("Cohere API Key:")
os.environ["OPENAI_API_KEY"] = getpass("OpenAI API Key:")打印文档的辅助函数
def pretty_print_docs(docs):
print(
f"\n{'-' * 100}\n".join(
[f"Document {i+1}:\n\n" + d.page_content for i, d in enumerate(docs)]
)
)加载所需的文档
pdf_folder_path = "/content/Documenation"
loader = PyPDFDirectoryLoader(pdf_folder_path)
docs = loader.load()检查加载文档的长度和内容
print(len(docs))
print(docs[0].page_content)将文本拆分成块
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(docs)
print(len(texts))设置嵌入模型 — BGE 嵌入
model_name = "BAAI/bge-small-en-v1.5"
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
bge_embeddings = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs={'device': 'cuda'},
encode_kwargs=encode_kwargs
)设置 LLM
llm = OpenAI()使用“web_search”提示加载
embeddings = HypotheticalDocumentEmbedder.from_llm(llm,
bge_embeddings,
prompt_key="web_search"
)
print(embeddings.llm_chain.prompt)
langchain.debug = True
# Now we can use it as any embedding class!
result = embeddings.embed_query("According to Kelly and Williams what is ethics?")
print(result)设置基础向量存储检索器
vectorstore = FAISS.from_documents(texts, embeddings)
retriever = vectorstore.as_retriever(search_kwargs={"k": 20})根据查询从向量存储中检索最相关的上下文
query = "According to Kelly and Williams what is ethics?"
docs = retriever.get_relevant_documents(query)
pretty_print_docs(docs)RAG流水线的生成部分
llm = ChatOpenAI(model_name="gpt-3.5-turbo-16k",temperature=0.1)
qa = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever)生成响应
%%time
response = qa.run(query=query)
print(response)Multiple generations
我们也可以生成多个文档,然后将这些文档的嵌入向量进行合并。默认情况下,我们是通过取平均值的方式来合并这些嵌入向量。我们可以通过改变用于生成文档的语言模型,使其返回多个内容,从而实现这一点。
multi_llm = OpenAI(n=4, best_of=4)
#
embeddings = HypotheticalDocumentEmbedder.from_llm(
multi_llm, bge_embeddings, "web_search"
)
#
result = embeddings.embed_query("According to Kelly and Williams what is ethics?")为多次文本生成设置向量存储 - 假设文档检索器
vectorstore = FAISS.from_documents(texts, embeddings)
retriever = vectorstore.as_retriever(search_kwargs={"k": 20})
query = "According to Kelly and Williams what is ethics?"
docs = retriever.get_relevant_documents(query)
pretty_print_docs(docs)样本多个生成的文本
- “text”: “\nKelly and Williams define ethics as the principles of right and wrong that govern the behavior of individuals and the decisions they make. They believe that ethical behavior is based on moral values, such as honesty, respect, and fairness, and is guided by the moral code of a particular society. They also argue that the moral code of a society is based on a shared set of values and beliefs that guide individuals in making ethical decisions. Ultimately, Kelly and Williams believe that ethical behavior is based on individual responsibility and choice, and that it is essential for people to have a sense of right and wrong in order to live lives of integrity and meaningfulness.”,
- ......
RAG流水线的生成部分 - HyDE
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
#
llm = ChatOpenAI(model_name="gpt-3.5-turbo-16k",temperature=0.1)
#
qa = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever)
%%time
#
response = qa.run(query=query)
print(response)为HyDE使用自定义提示
除了使用预配置的提示外,我们还可以轻松构建自己的提示,并在生成文档的LLMChain中使用它们。如果我们知道查询将处于哪个领域,这可能会很有用,因为我们可以调整提示以生成更相似的文本。
prompt_template = """Please answer the user's question as a single food item
Question: {question}
Answer:"""
prompt = PromptTemplate(input_variables=["question"], template=prompt_template)
llm_chain = LLMChain(llm=llm, prompt=prompt)
# Hypthetical Document Retriever
embeddings = HypotheticalDocumentEmbedder(
llm_chain=llm_chain,
base_embeddings=bge_embeddings
)
result = embeddings.embed_query(
"According to Kelly and Williams what is ethics?"
)设置向量存储 - 例如 ChromaDB
# set up Vectorstore
docsearch = Chroma.from_documents(texts, embeddings)检索相似文档
query = "What is the role of ethical manager?"
docs = docsearch.similarity_search(query)
print(docs[0].page_content)RAG流水线的生成部分
llm = ChatOpenAI(model_name="gpt-3.5-turbo-16k",temperature=0.1)
retriever = docsearch.as_retriever(search_kwargs={"top_k": 2})
qa = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever)Response
%%time
response = qa.run(query=query)
print(response)
query = "What should be the qualities of a good ethical manager?"
docs = docsearch.similarity_search(query)
pretty_print_docs(docs)RAG-Response Generated
%%time
response = qa.run(query=query)
print(response)Conclusion
HyDE,或称假设性文档扩展,利用语言学习模型(LLMs)如 ChatGPT 生成理论文档,以提高搜索的准确性。它使用无监督编码器将理论文档转换为用于检索的向量。这种方法在网络搜索、问答和事实核查等任务中表现出色,其稳健的性能可与经过良好调整的检索器相媲美。然而,这种方法并非完美无缺;如果主题对LLM来说完全陌生,这种方法可能会产生不准确的信息。尽管如此,HyDE 在检索技术方面标志着重大进步,它提供了一种新颖的方法,专注于答案到答案的嵌入相似性。

















 1626
1626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









