




论文探索了在中型
ImageNet-1k数据集上预训练的普通ViT到更具挑战性的COCO目标检测基准的可迁移性,提出了基于Vision Transformer的You Only Look at One Sequence(YOLOS)目标检测模型。在具有挑战性的COCO目标检测基准上的实验结果表明,2D目标检测可以以纯sequence-to-sequence的方式完成,并且附加的归纳偏置最小来源:晓飞的算法工程笔记 公众号
论文: You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection

Introduction
Vision Transformer(ViT) 证明,直接继承自NLP的Transformer编码器架构可以在大规模图像识别方面表现出色。以图像块嵌入序列作为输入,仅需少量的Fine-tune数据,ViT即可成功地从纯粹的sequence-to-sequence角度将足量数据预训练的视觉表达迁移到更具体的图像分类任务。
一个自然的问题是:ViT能否直接迁移到更具挑战性的对象和区域级目标任务中,例如图像级识别之外的目标检测?
ViT-FRCNN是第一个使用预先训练的ViT作为Faster R-CNN目标检测器的主干网络,但这种设计无法摆脱对卷积神经网络(CNN)的依赖和2D归纳偏差。因为ViT-FRCNN需要将ViT的输出序列重新排列为2D空间特征图,依赖于区域池化操作(即RoIPool或RoIAlign)以及基于区域的CNN架构来解码ViT特征,用于对象和区域级别的感知。
受现代CNN设计的启发,最近的一些工作将特征金字塔等设计引入到Vision Transformer中,这很大程度上提高了包括目标检测在内的密集预测任务的性能。但这些架构是以性能为导向的,不能反映Vision Transformer的特性。另外的一些如DEtection TRansformer(DETR) 的系列工作,使用随机初始化的Transformer来编码和解码CNN特征用于目标检测,也未揭示预训练Transformer的可迁移性。
直观上,ViT旨在学习远距离依赖关系和全局上下文信息,而不是本地和区域级别的关系。此外,ViT缺乏现代CNN那样的分层架构来处理视觉实体尺寸的巨大变化。根据现有的研究,目前尚不清楚纯ViT是否可以将预训练的通用视觉表达从图像级识别转移到更复杂的2D目标检测任务。
为了回答这个问题,论文提出了基于ViT架构的目标检测模型You Only Look at One Sequence(YOLOS),具有尽可能少的架构修改、区域先验以及目标任务相关归纳偏差。本质上,从预训练ViT到YOLOS检测器的变化非常简单:
- 将
ViT中用于图像分类的 [ C L S ] [\mathrm{CLS}] [CLS] 标记替换为一百个用于目标检测的 [ D E T ] [\mathrm{DET}] [DET] 标记。 - 按照
DETR用二分匹配损失替换ViT的图像分类损失,以集合预测的方式进行目标检测。这可以避免像ViT-FRCNN那样将ViT的输出序列重新解释为2D特征图,以及防止在标签分配中引入启发式算法和2D空间结构的先验知识。而且,YOLOS的预测头可以摆脱复杂多样的设计,就像分类层一样紧凑。
YOLOS继承自ViT并不是为了成为另一个高性能目标检测器,而是为了揭示预训练的Transformer从图像识别到更具挑战性的目标检测任务的多功能性和可迁移性。具体来说,论文的主要贡献总结如下:
- 使用中型
ImageNet-1k作为唯一的预训练数据集,表明普通ViT可以成功迁移至复杂的目标检测任务,并以尽可能少的修改在COCO基准上达成有竞争力的结果。 - 首次证明通过将一系列固定大小的非重叠图像块作为输入,也可以以纯
sequence-to-sequence的方式完成2D目标检测。在现有的目标检测器中,YOLOS利用最小的2D归纳偏置。 - 对于原始
ViT,目标检测结果对预训练方法非常敏感并且检测性能远未饱和。因此,YOLOS也可以用作具有挑战性的基准任务来评估ViT的不同(标签监督和自监督)预训练策略。
You Only Look at One Sequence
YOLOS遵循原始ViT架构,并与DETR一样针对目标检测进行优化。YOLOS可以轻松适应NLP和计算机视觉中可用的各种Transformer架构,这种简单的设置并不是为了更好的检测性能而设计的,而是为了尽可能公正地准确揭示Transformer系列在目标检测中的特性。
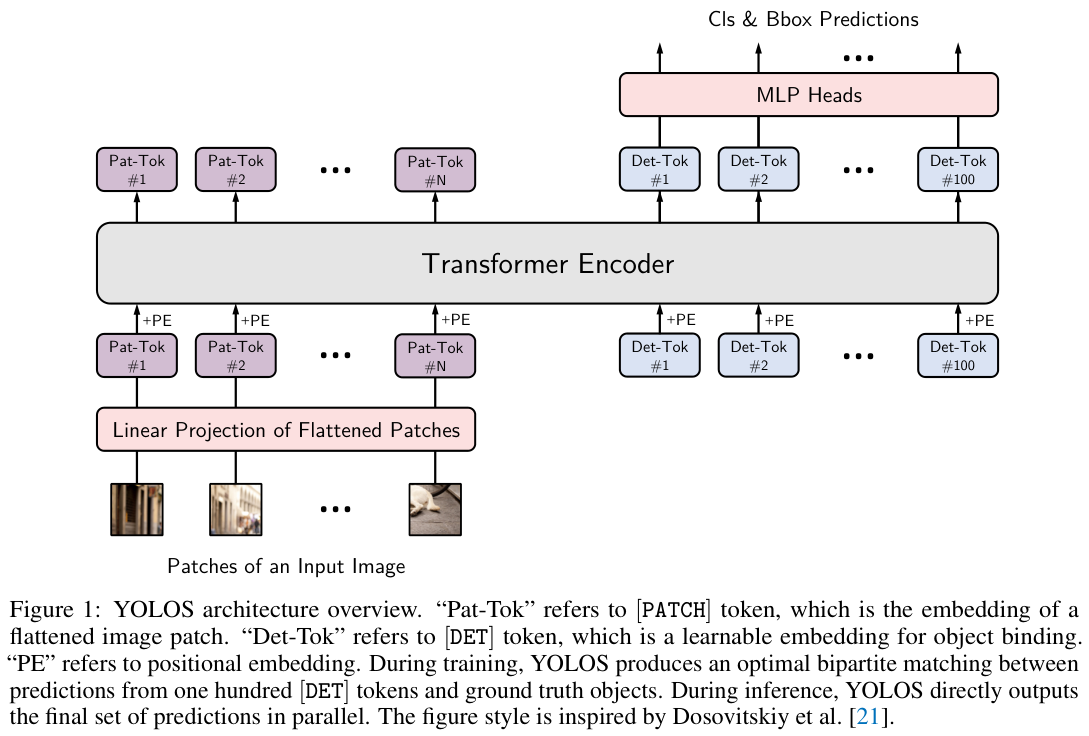
模型架构如图 1 所示,从ViT分类器到YOLOS检测器的变化很简单:
-
删除用于图像分类的 [ C L S ] [\mathrm{CLS}] [CLS] 标记,附加了一百个随机初始化的可学习检测标记 [ D E T ] [\mathrm{DET}] [DET] 到输入嵌入 [ P A T C H ] [\mathrm{PATCH}] [PATCH] 以进行目标检测。
-
在训练过程中,将图像分类损失替换为二分匹配损失,以遵循
DETR的设定预测方式进行目标检测。 -
Stem
常规ViT接收1D序列嵌入作为输入,为了处理2D图像输入,将图像 x ∈ R H × W × C \mathbf{x}\in\mathbb{R}^{H\times W\times C} x∈R
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7891
7891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









