






前言:最近要做淘宝的信息爬取,用来完成期末作业,发现淘宝的反爬机制挺强的,试了多种方法,最后终于完成,使用了正则匹配与字符串查找两种方法.
!!!郑重证明:本教程仅用作学习交流,请勿用作商业盈利,违者后果自负!如本文有侵犯任何组织集团公司的隐私或利益,请告知联系删除!!!
首先来看看淘宝搜索的URL:
f"http://s.taobao.com/search?q={key}&ie=utf8&s={i*44}"
其中key表示搜索内容不支持中文,需要转化为utf-8的‘%’分割格式
其中i代表第几页
url中文转换:
key = input("输入查询内容>>>\n")
keyCopy = key
key = str(key.encode("utf-8")).split('\'')[1]
key = key.replace("\\x", "%", -1)
登陆淘宝ctrl+u查看源码,发现所有信息都保存在了一个json文件中:
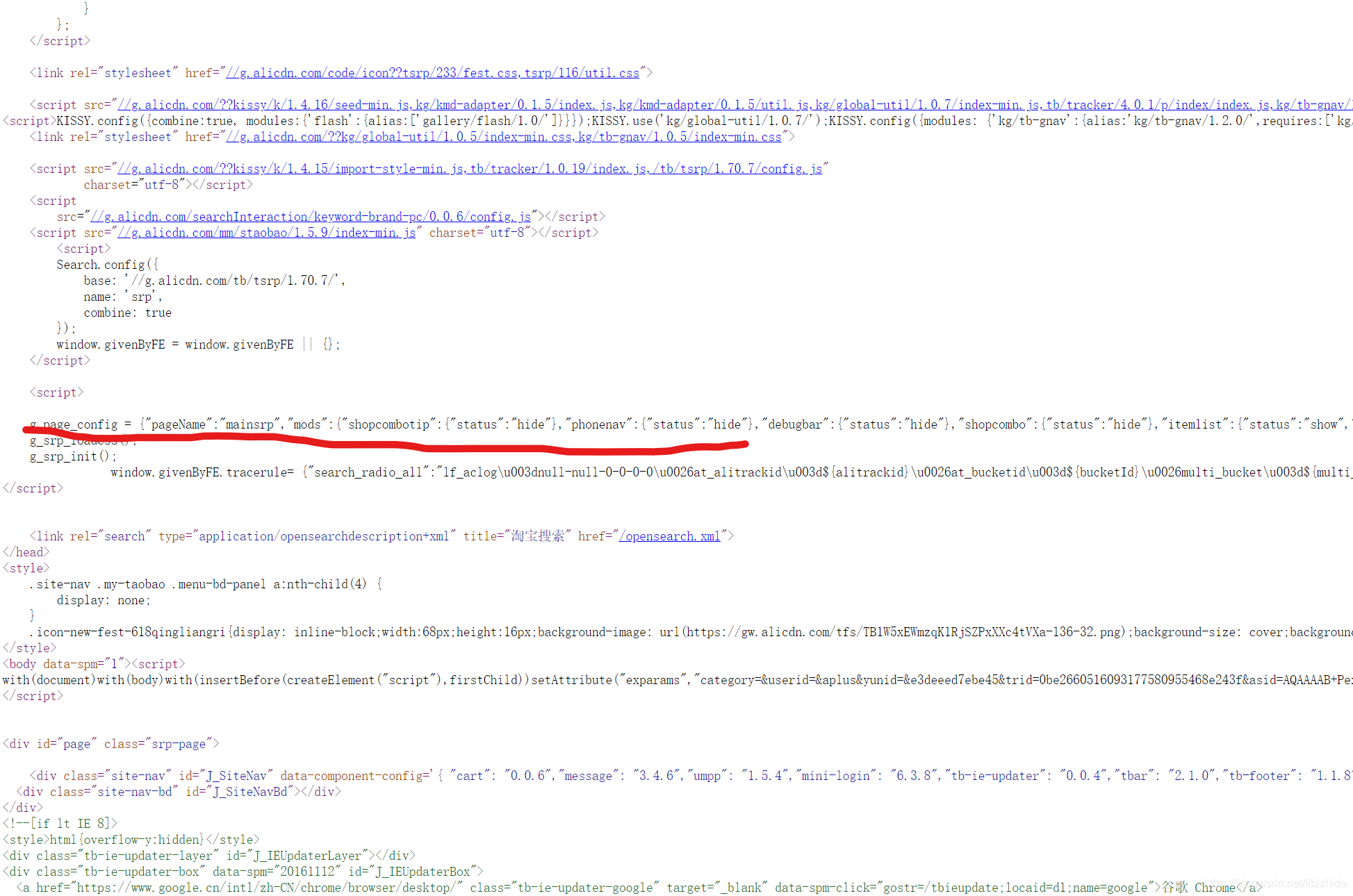
得到这些内容很简单:
soup = BeautifulSoup(html, 'lxml', exclude_encodings="utf-8")
html = str(soup.select("head>script"))
之后就可以对json文件进行分析了:
①用正则匹配
②用字符串分割split+字符串查找find
具体不做赘述,见下方源码,至于怎么来的,自己看看json文件内容便是
正则匹配
用到的库:
import pandas as pd
import urllib.request
import lxml
#import pymongo#需要保存到mongoDB,就把下面mongoDB用到的代码取消注释
完全代码:
import re
import time
import random
import pandas as pd
import urllib.request
#import pymongo
# 正则规则
r_title = '"raw_title":"(.*?)"' # 标题
r_location = '"item_loc":"(.*?)"' # 销售地
r_sale = '"view_sales":"(.*?)人付款"' # 销售量
r_price = '"view_price":"(.*?)"' # 销售价格
r_nid = '"nid":"(.*?)"' # 商品ID
r_img = '"pic_url":"(.*?)"' # 图片URL
r_store = '"nick":"(.*?)"' # 店铺
# 纪录总条数
countFile = 0
countAll = 0
# 数据整理并插入mongodb数据库中
def sharp(html=""):
global countAll, countFile
data = []
countS = 0
# 正则匹配
title = re.findall(r_title, html)
location = re.findall(r_location, html)
sale = re.findall(r_sale, html)
price = re.findall(r_price, html)
nid = re.findall(r_nid, html)
img = re.findall(r_img, html)
store = re.findall(r_store, html)
# 匹配失败
if len(title) == 0:
print("整理失败,已被淘宝反爬,请更新headers...")
exit(0)
# 匹配成功
for j in range(len(title)):
data.append([nid[j], img[j], price[j], sale[j],
title[j], store[j], location[j]])
# 拷贝
dataCopy = data.copy()
# 保存到csv中
data = pd.DataFrame(
data, columns=['_id', 'image', 'price', 'deal', 'title', 'shop', 'location'])
key = "temp"
data.to_csv(f'{key}{countFile}.csv', encoding='gbk', index=False)
countFile += 1
'''
print("整理成功,正在插入数据...")
# 将数据写到mongoDB中
for i in dataCopy:
count = 0
tempDict = {'_id': "", 'image': "", 'price': "",
'deal': "", 'title': "", 'shop': "", 'location': ""}
for j in tempDict:
if count == 2:
tempDict[j] = "¥"+i[count]
else:
tempDict[j] = i[count]
count += 1
try:
mycol.insert(tempDict)
countS += 1
except:
pass
countAll += countS
print(f"本次一共插入{countS}条数据...")
'''
# 连接数据库
'''
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["taobao"]
mycol = mydb["meishi"]
'''
# 以下headers来自自己的浏览器
# headers格式化工具:https://curl.trillworks.com/
headers = {
,###本部分需用自己的headers###
}
key = input("输入查询内容>>>\n")
keyCopy = key
# 转化中文字符串
key = str(key.encode("utf-8")).split('\'')[1]
key = key.replace("\\x", "%", -1)
count = int(input("爬取页数(一页有48条数据,建议爬取一页,淘宝反爬机制强大,一天不要爬取太多)>>>\n"))
for i in range(count):
# 发送请求,得到html文本
url = f"http://s.taobao.com/search?q={key}&ie=utf8&s={i*44}"
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
html = response.read().decode('utf-8')
print("正在整理数据...")
sharp(html)
if count > i+1:
# 生成随机数,得到下一次爬取时间
ranTemp = random.randint(4, 13)
print(f"{ranTemp}秒后进行下一次爬取...")
[[print(f"剩余{ranTemp-1-k}秒..."), time.sleep(1)]
for k in range(ranTemp)]
print(f"一共爬取到{countAll}条数据...")
字符串方法
用到的库:
from bs4 import BeautifulSoup
import pandas as pd
import urllib.request
import lxml
#import pymongo#需要保存到mongoDB,就把下面mongoDB用到的代码取消注释
完全代码:
from bs4 import BeautifulSoup
import time
import random
import pandas as pd
import urllib.request
import pymongo
import sys
p_list = ['"pic_url":"', '"view_price":"', '"view_sales":"',
'"raw_title":"', '"nick":"', '"item_loc":"']
# 数据整理并插入mongodb数据库中
countAll = 0
'''
@func: 字符串截取函数
@return:后一个引号前的字符
@note:index必须前一个引号后一个序号
'''
def get_primary(a="", index=0):
b = ""
for i in range(index, len(a)):
if a[i] != '"':
b += a[i]
else:
return b
'''
@func: H5查找函数,输入html文本
@return:None
@note:如果被反爬了会自动退出
'''
def findH(html=""):
global countAll
countS = 0
data = []
soup = BeautifulSoup(html, 'lxml', exclude_encodings="utf-8")
html = str(soup.select("head>script"))
if html == "":
print("整理失败,已被淘宝反爬,请更新headers!!!")
exit(0)
html = str(html).split('"nid":"')
for i in html:
temp = []
temp.append(get_primary(i, 0))
for j in p_list:
index = i.find(j)
if index == -1:
break
else:
temp.append(get_primary(i, len(j)+index))
if j == '"item_loc":"':
data.append(temp)
dataCopy = data.copy()
data = pd.DataFrame(
data, columns=['_id', 'image', 'price', 'deal', 'title', 'shop', 'location'])
key = "tempp"
data.to_csv('%s.csv' % key, encoding='utf-8', index=False)
'''
print("整理成功,正在插入数据...")
for i in dataCopy:
count = 0
tempDict = {'_id': "", 'image': "", 'price': "",
'deal': "", 'title': "", 'shop': "", 'location': ""}
for j in tempDict:
if count == 2:
tempDict[j] = "¥"+i[count]
else:
tempDict[j] = i[count]
count += 1
try:
mycol.insert(tempDict)
countS += 1
except:
pass
countAll += countS
print(f"本次一共插入{countS}条数据!!!")
'''
# 连接数据库
'''
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["taobao"]
mycol = mydb["meishi"]
'''
# 以下headers来自自己的浏览器
# headers格式化工具:https://curl.trillworks.com/
# 需用自己
headers = {
,###本部分需用自己的headers###
}
if __name__ == "__main__":
key = input("输入查询内容>>>\n")
keyCopy = key
key = str(key.encode("utf-8")).split('\'')[1]
key = key.replace("\\x", "%", -1)
count = int(input("爬取页数(一页有48条数据,建议爬取一页,淘宝反爬机制强大,一天不要爬取太多)>>>\n"))
for i in range(count):
url = f"http://s.taobao.com/search?q={key}&ie=utf8&s={i*44}"
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
html = response.read().decode('utf-8')
print("\n正在整理数据...")
findH(html)
if count > i+1:
ranTemp = random.randint(4, 13)
print(f"{ranTemp}秒后进行下一次爬取...")
[[print(f"\r剩余{ranTemp-1-k}秒...", end=""), sys.stdout.flush(), time.sleep(1)]
for k in range(ranTemp)]
print(f"\n一共爬取到{countAll}条数据!!!")
headers的获取方法:
登陆淘宝后,找到这一行:
右键copy as cURL(bash)
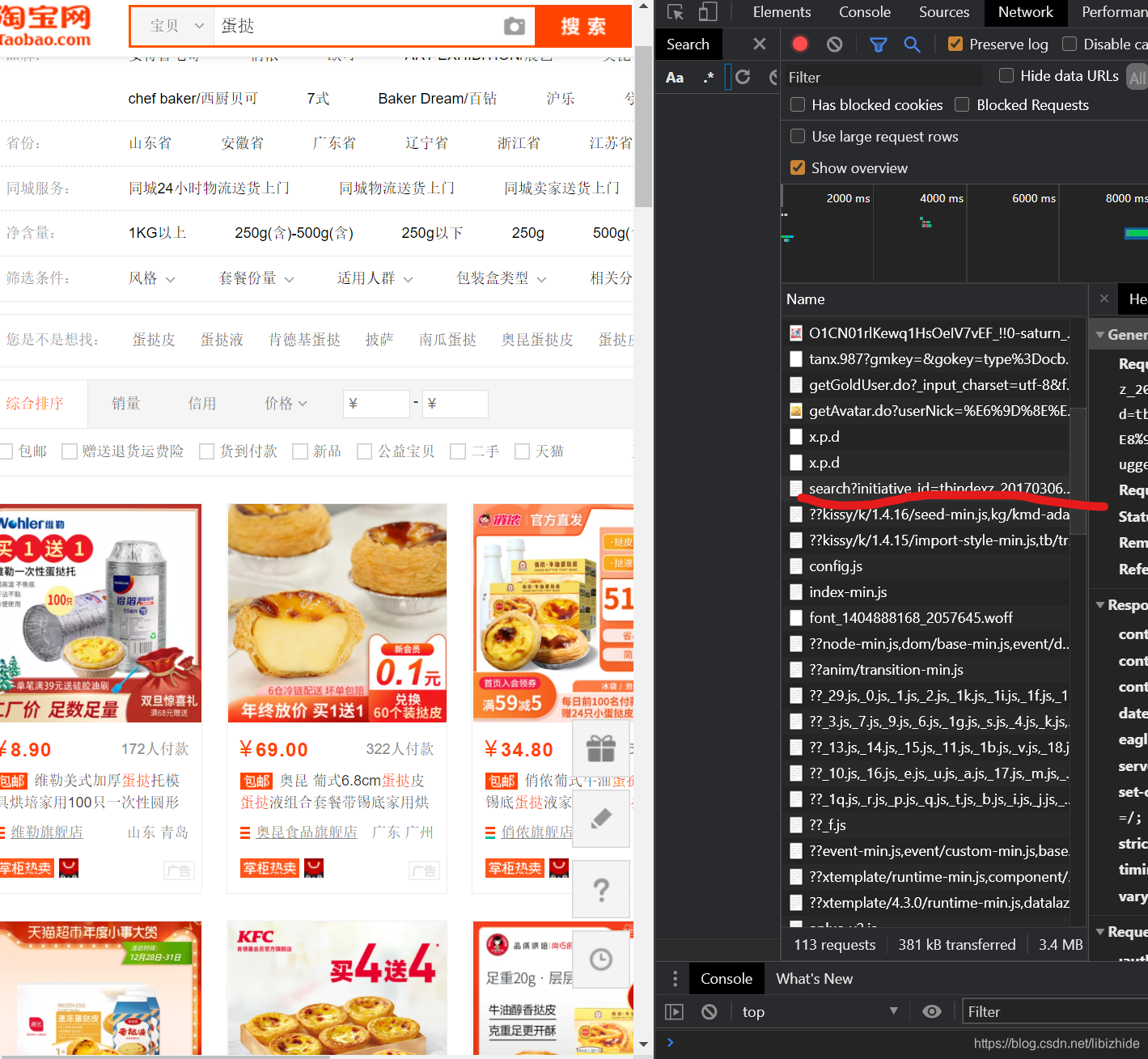
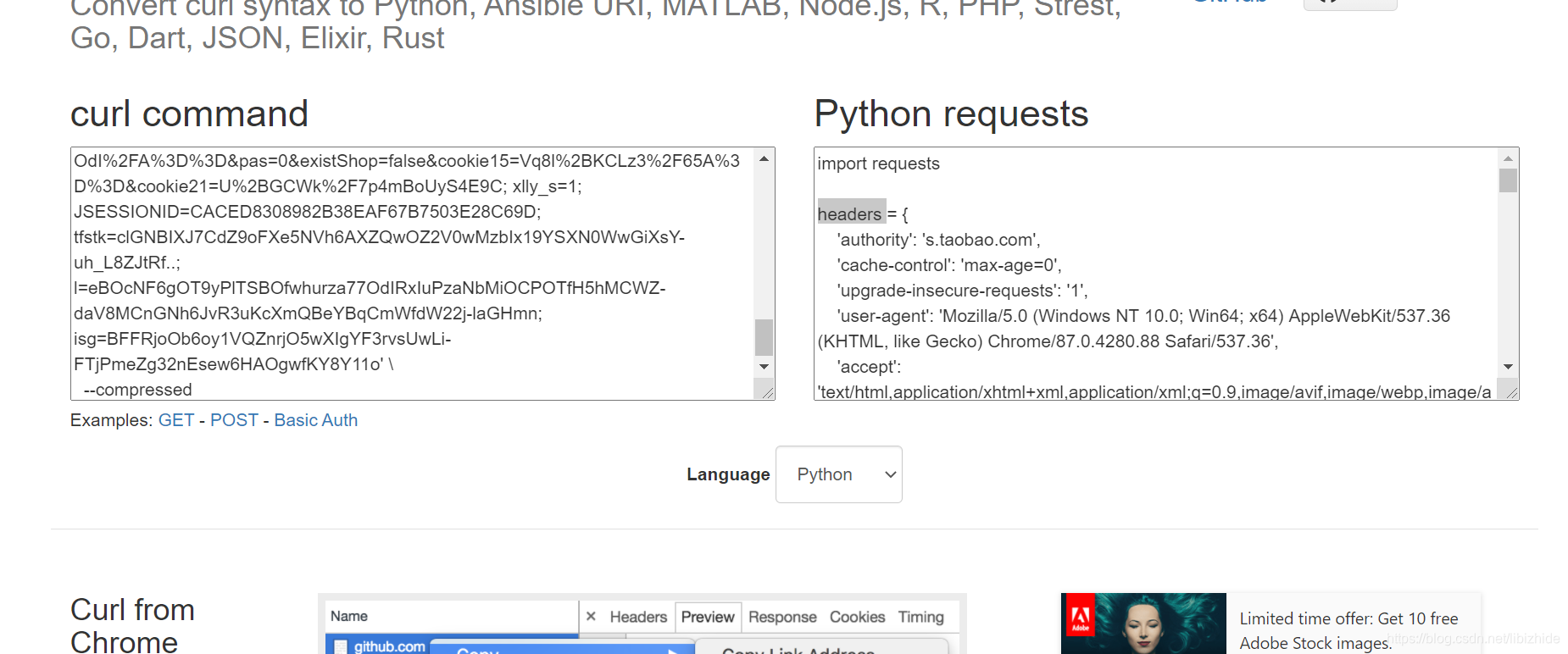
粘贴到:https://curl.trillworks.com/ 中
如图:把其中headers字典取出粘贴进去即可。
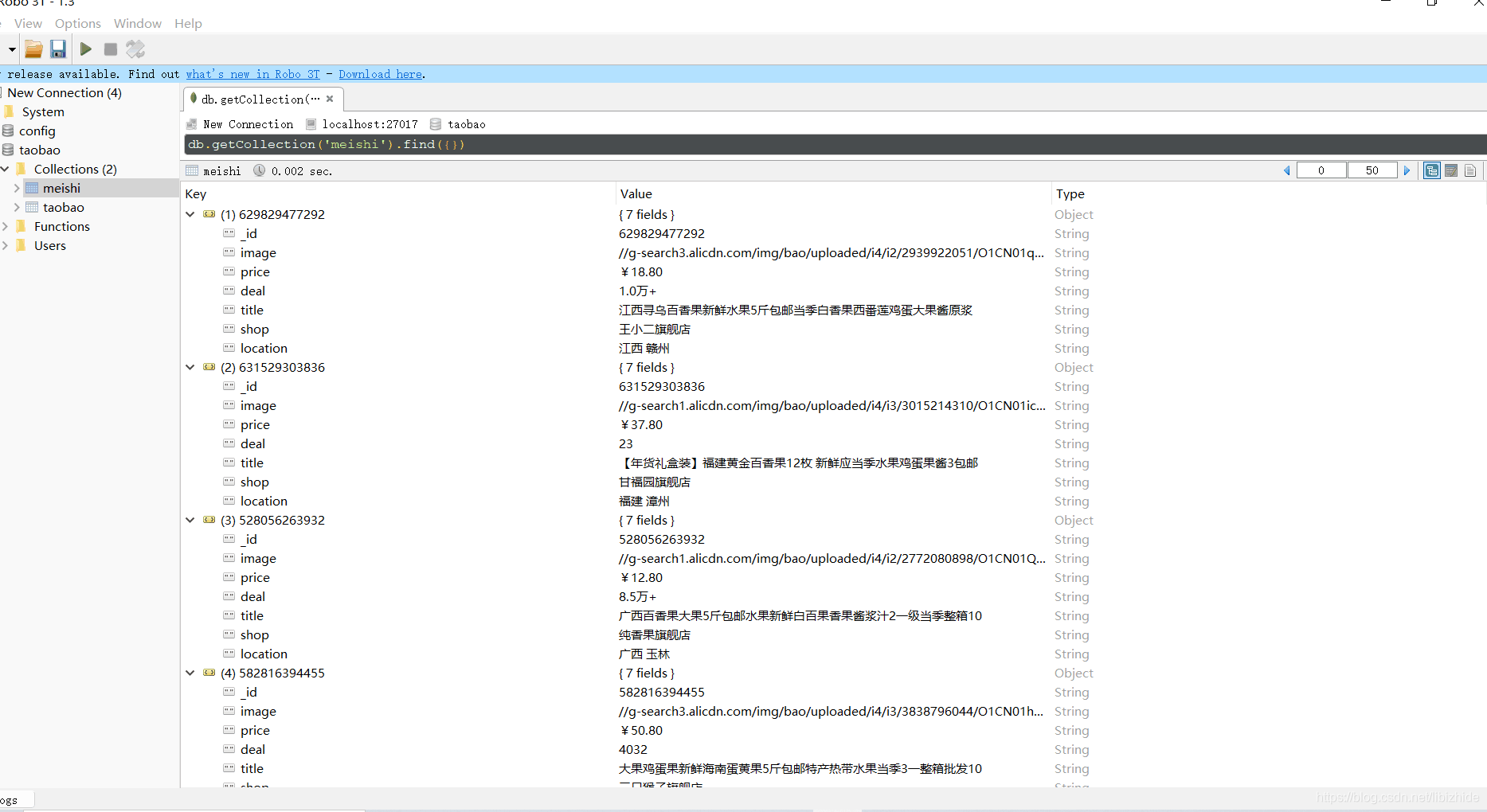
最后爬取成功

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









