



摩尔线程、沐曦股份登陆科创板,壁仞科技挂牌港交所,百度也发布公告称,昆仑芯将分拆上市,国产AI芯片迎来了新的发展阶段,GPU是如何工作的?GPU是如何支撑大模型训练的?结合Google DeepMind 的文章《How to Think About GPUs》或许可以找到一些答案(原文链接在文末)。
什么是GPU
现代机器学习GPU(例如H100、B200)基本上是一组专门进行矩阵乘法的计算核心(称为流式多处理器,SM),连接到一块高速内存条组成,例如英伟达的H100有132个SM,而B200有148个。每个 SM 基本上完全独立,所以一块 GPU 可以同时处理数百个独立任务。
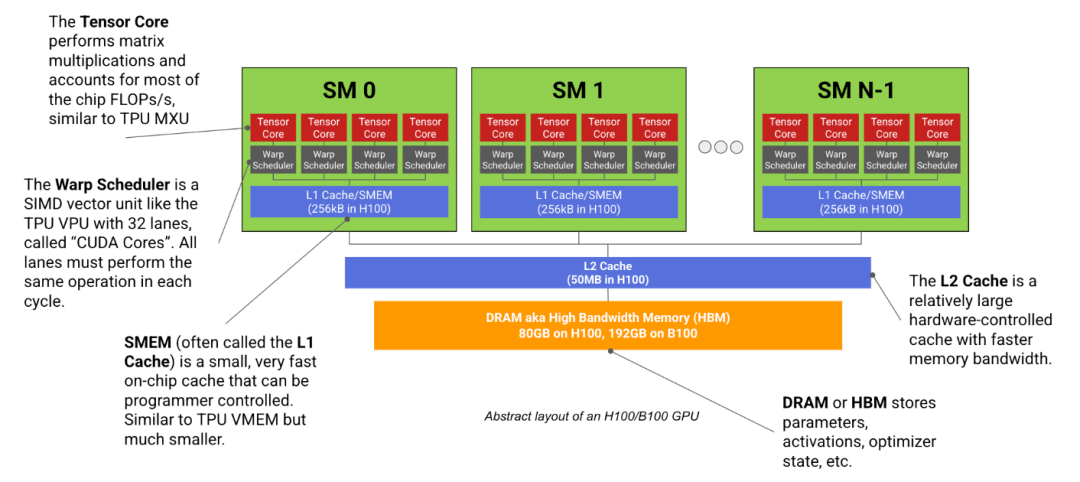
每个SM均由 CUDA Core、Tensor Core、寄存器、调度器、数据缓存等组成,其中 :
-
CUDA Core:主要用来做浮点数的加、减、乘、除等基本运算,尤其是 乘加运算(比如 a × b + c)像一群认真写作业的小学生,用于做大量简单的计算
-
Tensor Core :专门用来做矩阵乘法,矩阵乘法 是 AI(尤其是深度学习)中最核心、最耗时间的计算,比如识别一张图片是不是猫,背后就是成千上万个矩阵在相乘。所以Tensor Core像一个会心算魔方的天才少年,做 AI 专用的复杂计算
H100 SM结构图
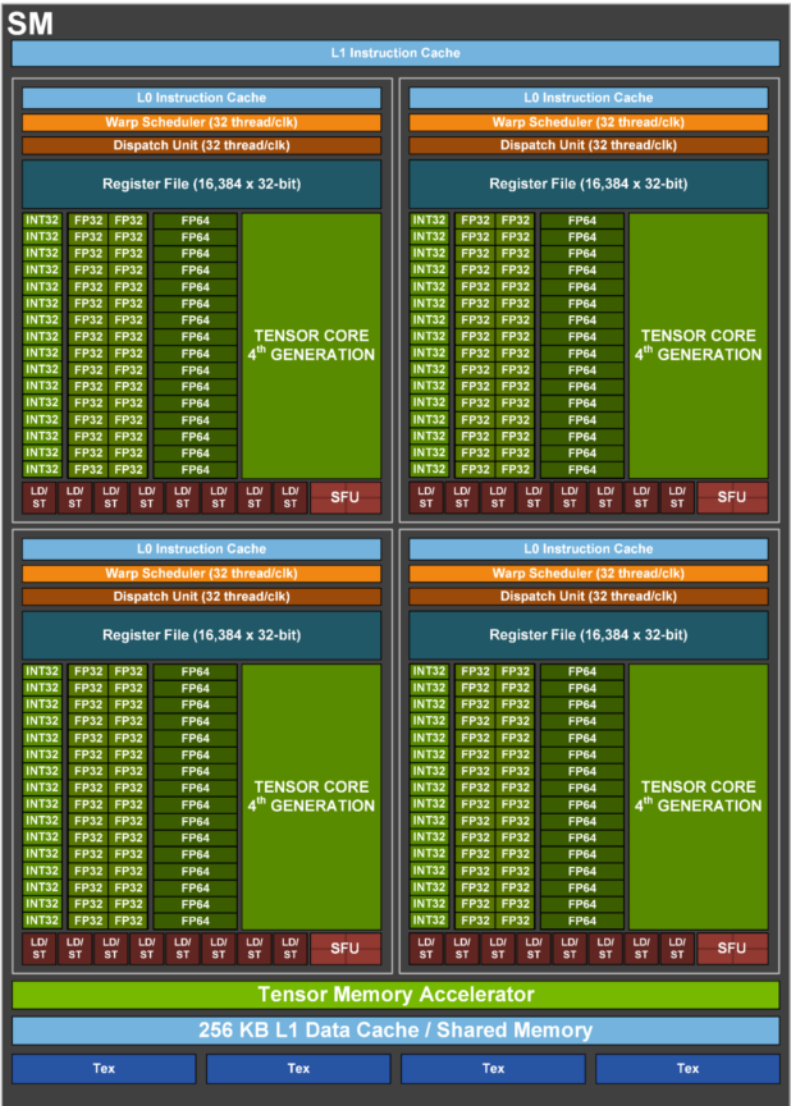
以下是不分型号的GPU规格总结。不同型号的显卡内存数量、时钟频率和FLOP略有差异。

分层网络结构
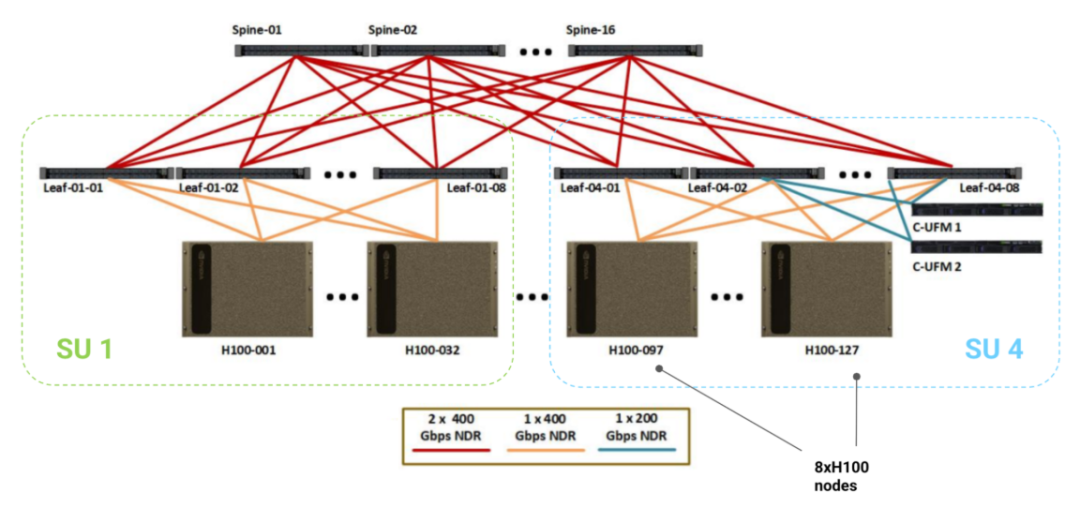
在人工智能尤其是大模型领域,我们会听说千卡集群或者万卡集群,这么多的GPU是如何一起发挥作用的?这就不得不提到网络,GPU则采用分层树状交换网络,将众多GPU组织在一起。
- 节点:通常由8个GPU组成,称为节点(GB200最多可达72个)通过称为NVLink的高带宽互连。
- SU:节点通过使用较低带宽的InfiniBand(IB)或以太网网络,连接到更大的单元(称为SU或可扩展单元),这些开关又可以连接到任意大的单元,配备更高级别的开关。
通过GPU->节点->SU->… 的层层结构,众多GPU得以一起发挥作用
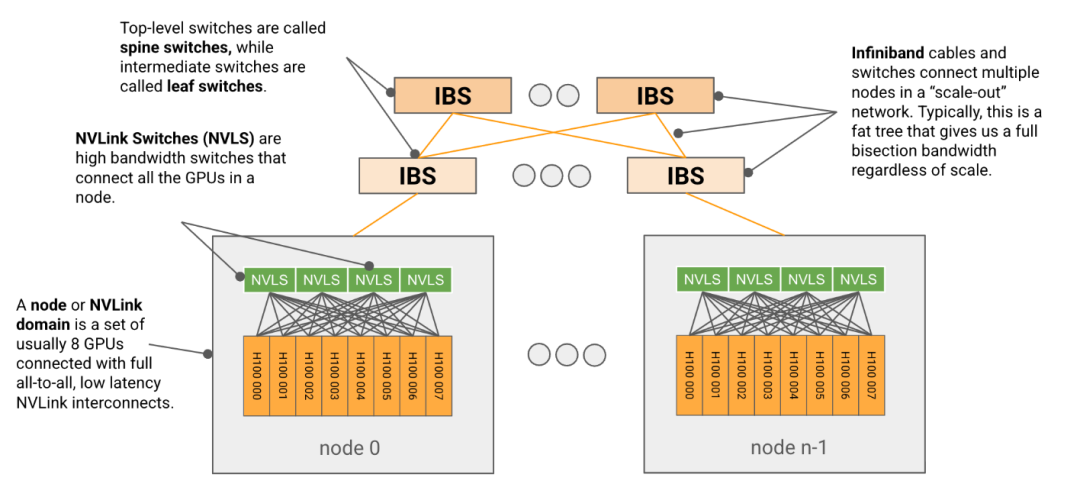
GPU节点是一个小型单元,通过全对全、全带宽、低延迟的NVLink互连连接。每个节点包含多个高带宽NVSwitch,负责在所有本地GPU之间交换数据包。实际的节点级拓扑随着时间发生了很大变化,包括每个节点交换机的数量,但对于H100来说,每个节点有4个NVSwitche,GPU以链路模式连接。
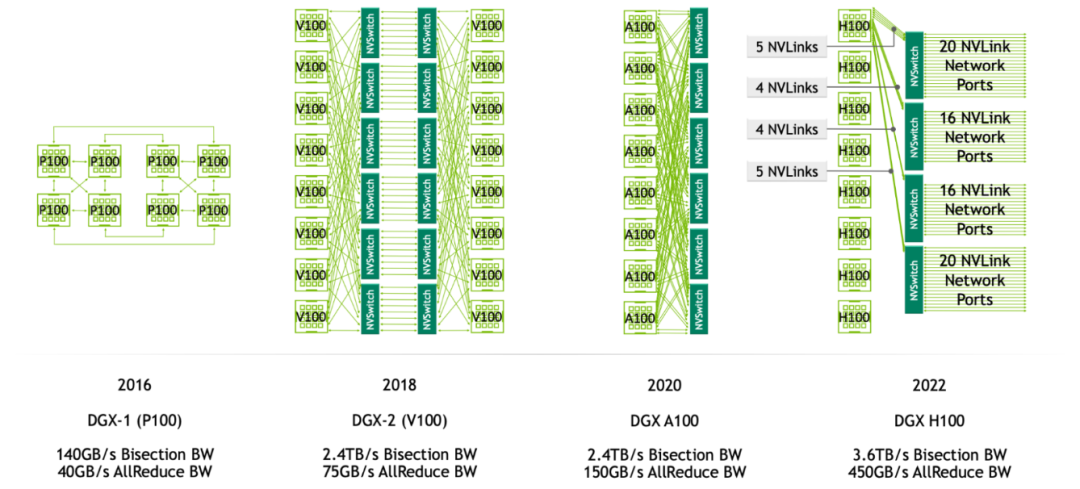
下图展示了一个可供参考的 1024 块 GPU 的 H100 系统架构:底部每一格代表一个标准的 8xH100 节点,每个节点包含 8 块 GPU、8 个 400Gbps 的 ConnectX-7 网卡(每块 GPU 配一个),以及 4 个 NVSwitch。
LLM在GPU上扩展的Roofline
训练大模型需要大量 GPU 协同工作。但 GPU 之间要互相传数据(比如参数、中间结果),这个“通信”如果太慢,就会拖累整体速度——哪怕你的 GPU 算得再快也没用。
你可以把它想象成:你开车去旅行,最高速度受限于两个因素:
- 路况(比如高速公路限速 120 km/h)→ 带宽限制
- 车本身的性能(比如发动机功率)→ 计算能力限制
为了让超大模型能在有限算力和内存的硬件上“跑起来”,突破算力或显存限制往往会引入很多并行策略。我们试着以很多厨师合作要做1000个蛋糕来理解这几种策略:
数据并行(Data Parallelism):所有 GPU 都跑完整模型,但各自处理不同数据,最后要把梯度汇总。好像:
- “每人照着同一本菜谱,做不同的蛋糕”
- 所有厨师都有一模一样的完整菜谱(模型副本)。
- 厨师 A 做第 1~100 个蛋糕,厨师 B 做 101~200 个……
- 做完后,大家聚在一起说:“我做的时候发现糖放多了一点,下次少放!”——这就是同步经验(梯度)。
- 然后统一更新菜谱,再做下一批。
张量并行(Tensor Parallelism, TP):把一个矩阵乘法拆到多个 GPU 上一起算(比如切权重矩阵)。好像:
- “一道工序拆给多人,流水线协作做同一个蛋糕”
- 菜谱太复杂,比如“打蛋 → 混面 → 烘烤”三步。
- 厨师 A 只负责打蛋,厨师 B 负责混面,厨师 C 负责烘烤。
- 但他们不是各做各的蛋糕,而是一起做一个蛋糕:A 打好蛋传给 B,B 混好面传给 C。
- 为了加快速度,他们同时处理多个蛋糕(A 在打第 2 个蛋时,B 在混第 1 个面)。
专家并行(Expert Parallelism, EP):MoE 模型专用:把不同的“专家”放在不同 GPU 上。好像:
- “每个厨师只擅长做一种口味的蛋糕,顾客点单后派单”
- 你开了个“千味蛋糕店”,有 128 种口味(128 个专家),但每个顾客只点 4 种。
- 厨师 A 只会做“巧克力味”,厨师 B 只会做“抹茶味”……
- 顾客下单后,系统把订单自动分发给对应口味的厨师。
- 做完后,再把不同口味的蛋糕拼成一份套餐。
流水线并行(Pipeline Parallelism, PP):把模型按层切开,前几层在 GPU A,后几层在 GPU B…… 好像:
- “把整个菜谱切成几段,每人负责一段,接力做蛋糕”
- 菜谱共 100 步,太长了,一个人记不住。
- 于是切成两半:厨师 A 负责第 1~50 步,厨师 B 负责 51~100 步。
- A 做完前半部分,把“半成品”传给 B,B 继续做完。
- 为了不闲着,A 做完第 1 个蛋糕的前半,立刻开始第 2 个……
如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 960
960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









