







 本文深入讲解KMP算法,一种高效查找字符串中模式串的方法。通过对比暴力解法,阐述KMP算法的优势及其工作原理,包括next数组的计算及KMP算法实现。
本文深入讲解KMP算法,一种高效查找字符串中模式串的方法。通过对比暴力解法,阐述KMP算法的优势及其工作原理,包括next数组的计算及KMP算法实现。
- 题意:给定一个字符串text,和一个模式串pattern。让你判断text是否包含pattern,如果包含,则返回text中出现pattern的第一个字符的坐标。否则返回-1。如果pattern是空字符串(长度为0),则返回1
- 解法1—暴力:我们遍历text的每个位置i,并从i开始遍历长度为 s i z e p size_p sizep的字符串,看其是否和pattern相等,如果相等返回i,否则继续遍历。
- 解法2—KMP。KMP是发明KMP算法三位大牛名字的缩写。他专门用来从给定字符串中找到另一个字符串。
- 上述解法1太过于暴力,所以KMP算法用来优化上述解法。
- 首先,我们看下述过程:
初始化:text=ABACBCDHIJK,pattern=ABAD 某一步: ABACBCDHIJK,i=3 ABAD,j = 3 => ABACBCDHIJK, i=3 ABAD, j=1- 针对p 字符串,我们维护一个数组next,next[j]=k,代表的是p[j-k~j-1]=p[0~k-1]。那么如果T[i] != P[j], 那么我们只需要移动j=next[j]就好,而不需要将i再回滚。为什么呢?我们怎么保证解不会出现在T[i-j~i]之间呢?
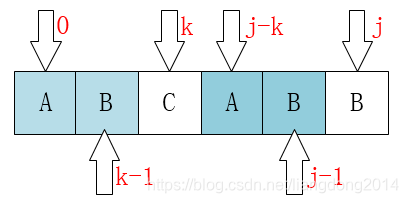
- 为了有助于我们理解,我从KMP,复制了上图。我们可以看到当T[i]!=P[j]的时候,我们其实是判断T[i] == P[k]。为什么呢?因为p[j-k~j-1]=p[0~k-1]=T[i-k, i-1]。其实理解成如果T[i]!=P[j],我们同时从0->p.size()方向和j->0方向遍历,找到两者相等的最长子字符串。此时从0->p.size()方向结束的位置就是我们下一个和T[i]比较的位置。
- 那么怎么计算next数组呢?
- 首先边界条件,next[0] = -1。代表的意思是如果T[i]!=P[0]的话,那i就应该切换到下一个了。
- 如果P[j] == P[k]的话,那么next[j+1] = k + 1。根据我们的定义next[j] = k =>P[0~k-1] == P[j-k~j-1]。那么此时P[j] == P[k] =>P[0~k] == P[j-k~j]=>next[j+1] = k+1。
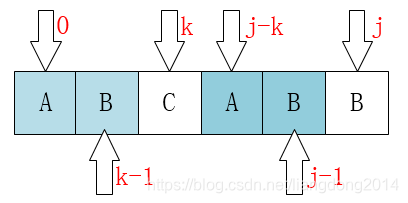
- 如果P[j]
≠
\neq
̸=P[k],那么k=next[k]。如何理解呢?同样以下图为例,这时候我们要判断的是next[j+1]的值,但是我们知道P[k] != P[j],所以我们肯定不能移动到k的位置,必须移动到K之前的某个位置。所以就是k=next[k],再进行迭代,知道找到P[j] == P[k]的位置。
- 获得pattern对应next的代码如下:
int* get_next(string needle){ int* next = new int[needle.length()]; next[0] = -1; int j = 0; int k = -1; int size = needle.length(); while(j<size - 1){ if(k == -1 || needle[k] == needle[j]){ j++; k++; next[j] = k; }else{ k = next[k]; } } return next; }- KMP算法的代码如下:
int KMP(string haystack, string needle){ if(needle == ""){ return 0; } int* next = get_next(needle); int i=0; int j=0; while(i < int(haystack.length()) && (j < int(needle.length()))){ // cout<<"i = "<<i<<", j = "<<j<<endl; if(j == -1 || haystack[i] == needle[j]){ i++; j++; }else{ j = next[j]; } } if(j == needle.length()){ return i-j; }else{ return -1; } }

















10-24
 787
787
787
08-30
453
453
08-13

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









