







前言
最近在做RAG相关的项目,在做检索模型的时候,由于我的需求更偏向于主题检索且需要较大的通用性。现有的检索模型bge、m3e等更偏向于语义匹配,即使针对主题做模型微调也没有很好的通用性,不能很好的完成需求。尝试直接使用LLM做Embedding,主要思想是将输入添加Prompt(将输入总结成一个词),然后使用最后一个词的最后一层作为整个输入的Embedding。
这里细读下面的2篇文章,并在中文的主题分类数据集上进行测试(这里使用公开数据集-科大讯飞的长文本分类),之后希望能在项目中有较好的应用。另外,由于两篇文章的思路比较简单,这里只做简单介绍,直接在数据集上测指标。
Simple Techniques for Enhancing Sentence Embeddings in Generative Language Models
原始论文: https://https://arxiv.org/pdf/2404.039211
论文github: https://https://github.com/ZBWpro/PretCoTandKEoTandKE
核心思想
使用预训练语言模型(PLM)完成Sentence Embedding任务时,一般聚焦于微调PLM,这种方式的通用性较差。直接使用LLM完成Sentence Embedding可以借助大模型的通用性,在少量数据上做调整,达到更通用的目的。经过实验后,作者发现从PLM中提取句子Embedding不是必须进行显示的限制(如: 将输入总结为1个词)。这种限制对于生成模型在直接推理场景下是有益的,但对于判别模型或生成式PLMs的微调时不是必要的。
论文的目标是提出一种既满足高质量句子嵌入的需求,又节省计算资源的方法。
文章提出了两种创新的提示工程技术,可以进一步增强预训练语言模型(PLM)Sentence Embedding的表达能力:Pretended Chain of Thought(假装思维链)和Knowledge Enhancement(知识增强)。
- 伪装的思维链(Pretended Chain of Thought, Pretended CoT):
-
该方法受到零样本思维链(Zero-shot CoT)设计的启发,其核心思想是在提示中加入“After thinking step by step,”(逐步思考后)这样的前置语句。这样做的目的并不是真的要求模型输出中间推理步骤,而是希望通过这种方式激发模型更加细致地处理句子表示。
-
Pretended CoT 通过模拟逐步推理的过程,帮助模型更好地理解和压缩句子的语义信息。
Prompt如下所示:
After thinking step by step , this sentence : “[X]” means in one word:“
2. 知识增强(Knowledge Enhancement):
-
这种方法通过在提示中加入关于文本摘要的人类经验,以文本形式直接指导模型如何提炼句子的主要信息。具体来说,它强调句子的主语和动作承载了更大的语义权重,而描述性词汇虽然重要但属于附加信息。
-
通过这种方式,模型被引导将注意力集中在句子的核心词汇上,从而在生成句子嵌入时能够更加准确地捕捉到句子的中心意义。
Prompt如下所示:
The essence of a sentence is often captured by its main subjects and actions, while descriptive terms provide additional but less central details. With this in mind , this sentence : “[X]” means in one word:“
实验结果

文本匹配实验结果
从上表可以看出,直接使用LLM的方法在大部分的数据集上与无监督微调的通用自编码模型的结果持平,而这种方式不需要微调,且具有更高的通用性。
模型大小对结果的影响:
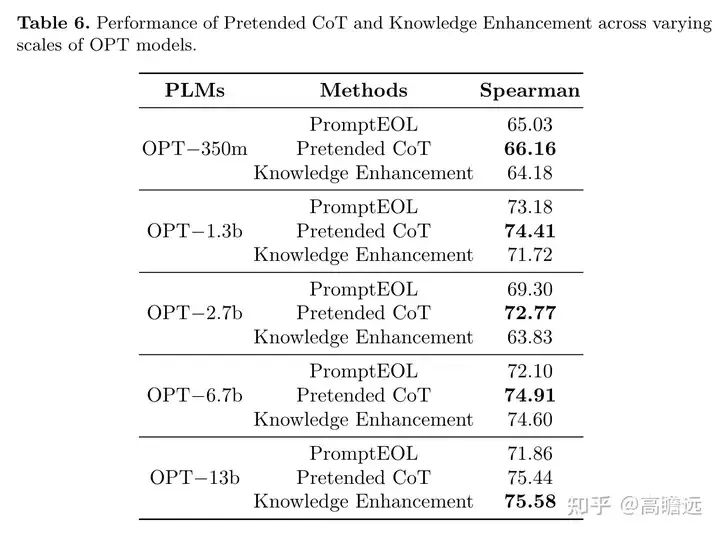
模型大小的影响
可以看出在350m到1.3b的模型上有大的提升,在PretendedCoT方法上从1.3b到13b上,精度提升较小。模型规模从6.7b到13b,实验的几个方法都有所提升,但提升幅度较小。
主要部分的代码实现:
from transformers import AutoModelForCausalLM, AutoTokenizer
class EmbeddingModel(object):
def __init__(self, model_path):
"""
初始化模型类。
"""
self.model_path = model_path
self.tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True
)
self.prompt = "After thinking step by step, summry this sentence: {input}: "
print("start to load model")
start = time.time()
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype='auto',
output_hidden_states=True
)
self.model = model.eval()
end = time.time()
print(f"load model spend time: {end-start :.4f} s")
def cons_batch(self, sentences, max_length=500):
"""
将输入的sentences列表组成batch,批量进模型
"""
sentences = [self.prompt.format(input=sentence) for sentence in sentences]
batch = self.tokenizer.batch_encode_plus(
sentences,
return_tensors='pt',
padding=True,
max_length=max_length,
truncation=max_length is not None
)
# Move to the correct device
for k in batch:
batch[k] = batch[k].to("cuda") if batch[k] is not None else None
return batch
def encode(self, sentences, batch_size=10):
result = []
for i in range(0, len(sentences), batch_size):
batch = self.cons_batch(sentences[i:i + batch_size])
with torch.no_grad():
outputs = self.model(output_hidden_states=True, return_dict=True, **batch)
embedding = outputs.hidden_states
last_hidden_states = embedding[-1][:, -1, :] # 取最后一个token的embedding
if last_hidden_states.dtype == torch.bfloat16:
# bfloat16 not support for .numpy()
last_hidden_states = last_hidden_states.float().cpu() # size: (batch_size, 4096)
last_hidden_states = last_hidden_states / torch.norm(last_hidden_states, p=2, dim=-1, keepdim=True)
result.append(last_hidden_states)
return np.concatenate(result, axis=0).astype('float') # size: (sentence_length, 4096)
# 这里主要注意last_hidden_states = embedding[-1][:, -1, :],取最后一个词的最后一层作为最终的Embedding
Meta-Task Prompting Elicits Embedding from Large Language Models
原始论文: https://https://arxiv.org/pdf/2402.184588
核心思想
跟上篇论文相同,本文用于从大型语言模型(LLMs)生成高质量的句子嵌入,而无需模型微调或处理特定任务的工程。
本文的主要思路是: 利用元任务(meta-tasks)来指导语言模型,使其能够从不同的角度生成句子的多维表示。通过构造多任务的提示词,然后使用融合的方式表示最终的句向量。但需要对多个提示进行LLMs的推断计算成本较高,不适合线上任务。
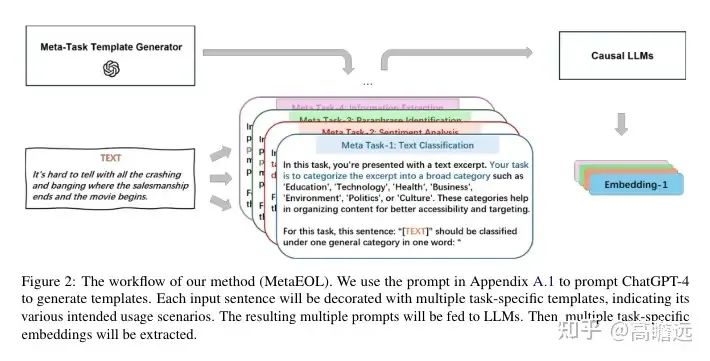
如上图所示,文章定义了4种任务,文本分类(Text Classification, TC)、情感分析(Sentiment Analysis, SA)、释义识别(Paraphrase Identification, PI)和信息提取(Information Extraction, IE)。
- 将从不同元任务中得到的嵌入进行平均,以形成最终的句子嵌入。
实验结论:
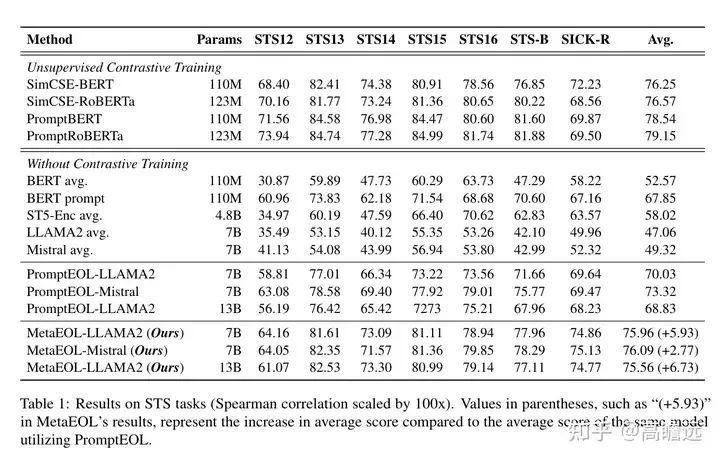
实验结论
上述两篇文章都明确限制输出为一个词,以确保模型将整个句子的信息聚合并压缩成一个单一的、信息丰富的词。这里在测试下其他的Prompt,看下是否会有一定程度的改进。
主题分类实战
数据集: 科大讯飞的长文本分类https://storage.googleapis.com/cluebenchmark/tasks/iflytek_public.zip
数据概览:

数据示例
原始数据集总
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2287
2287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









