




 为解决高并发场景下的缓存热点访问问题,提出了一种透明多级缓存方案TMC。该方案通过热点探测与本地缓存前置,有效缓解分布式缓存的压力,并确保数据一致性。
为解决高并发场景下的缓存热点访问问题,提出了一种透明多级缓存方案TMC。该方案通过热点探测与本地缓存前置,有效缓解分布式缓存的压力,并确保数据一致性。
前言:
正常情况下,我们为了缓解数据库读写压力,我们会在应用程序中增加一层缓存,但在高并发场景下,热点数据的访问依旧会对缓存造成压力,通过横向扩容也并不能解决本质问题。那么,有没有一种热点预测,精准匹配的解决方案呢? 以下是我在有赞公司技术文章里看到的一种多级缓存架构设计,以此记录,仅供学习。
TMC,即“透明多级缓存(Transparent Multilevel Cache)”,是有赞 PaaS 团队给公司内应用提供的整体缓存解决方案。
TMC 在通用“分布式缓存解决方案(如 CodisProxy + Redis,如有赞自研分布式缓存系统 zanKV)”基础上,增加了以下功能:
- 应用层热点探测
- 应用层本地缓存
- 应用层缓存命中统计
以帮助应用层解决缓存使用过程中出现的热点访问问题。
为什么要做 TMC
使用有赞服务的电商商家数量和类型很多,商家会不定期做一些“商品秒杀”、“商品推广”活动,导致“营销活动”、“商品详情”、“交易下单”等链路应用出现缓存热点访问的情况:
- 活动时间、活动类型、活动商品之类的信息不可预期,导致 缓存热点访问 情况不可提前预知;
- 缓存热点访问 出现期间,应用层少数 热点访问 key 产生大量缓存访问请求:冲击分布式缓存系统,大量占据内网带宽,最终影响应用层系统稳定性;
为了应对以上问题,需要一个能够 自动发现热点 并 将热点缓存访问请求前置在应用层本地缓存的解决方案,这就是 TMC 产生的原因。
多级缓存解决方案的痛点
基于上述描述,我们总结了下列 多级缓存解决方案需要解决的需求痛点:
- 热点探测:如何快速且准确的发现 热点访问 key ?
- 数据一致性:前置在应用层的本地缓存,如何保障与分布式缓存系统的数据一致性?
- 效果验证:如何让应用层查看本地缓存命中率、热点 key 等数据,验证多级缓存效果?
- 透明接入:整体解决方案如何减少对应用系统的入侵,做到快速平滑接入?
TMC 聚焦上述痛点,设计并实现了整体解决方案。以支持“热点探测”和“本地缓存”,减少热点访问时对下游分布式缓存服务的冲击,避免影响应用服务的性能及稳定性。
TMC 整体架构
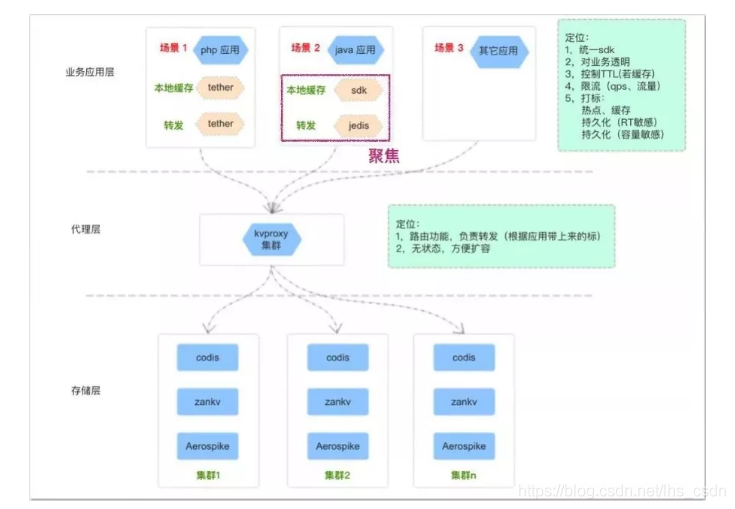
TMC 整体架构如上图,共分为三层:
- 存储层:提供基础的 kv 数据存储能力,针对不同的业务场景选用不同的存储服务(codis/zankv/aerospike);
- 代理层:为应用层提供统一的缓存使用入口及通信协议,承担分布式数据水平切分后的路由功能转发工作;
- 应用层:提供统一客户端给应用服务使用,内置“热点探测”、“本地缓存”等功能,对业务透明;
本篇聚焦在应用层客户端的“热点探测”、“本地缓存”功能。
TMC 本地缓存
如何透明?
TMC 是如何减少对业务应用系统的入侵,做到透明接入的?对于公司 Java 应用服务,在缓存客户端使用方式上分为两类:
- 基于 spring.data.redis包,使用 RedisTemplate编写业务代码;
- 基于 youzan.framework.redis包,使用 RedisClient编写业务代码;
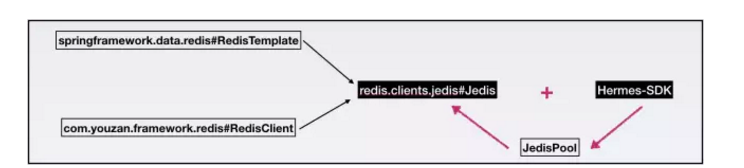
不论使用以上那种方式,最终通过 JedisPool创建的 Jedis对象与缓存服务端代理层做请求交互。
TMC 对原生 jedis 包的 JedisPool和 Jedis类做了改造,在 JedisPool 初始化过程中集成 TMC“热点发现”+“本地缓存”功能 Hermes-SDK包的初始化逻辑
使 Jedis客户端与缓存服务端代理层交互时先与 Hermes-SDK交互,从而完成 “热点探测”+“本地缓存”功能的透明接入。
对于 Java 应用服务,只需使用特定版本的 jedis-jar 包,无需修改代码,即可接入 TMC 使用“热点发现”+“本地缓存”功能,做到了对应用系统的最小入侵。
整体结构
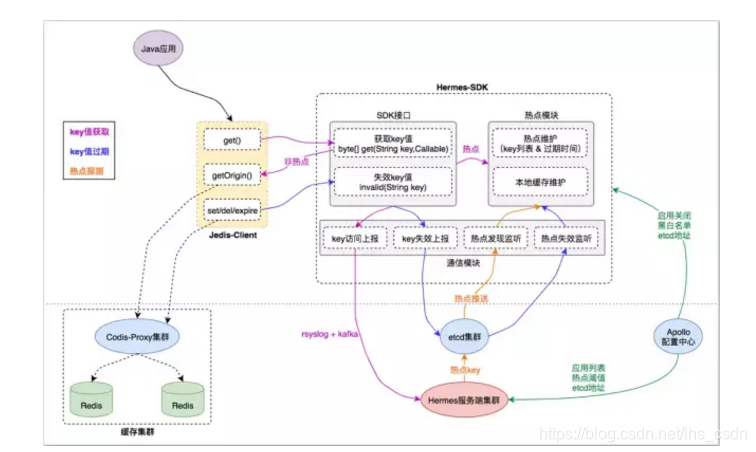
模块划分
TMC 本地缓存整体结构分为如下模块:
- Jedis-Client:Java 应用与缓存服务端交互的直接入口,接口定义与原生 Jedis-Client 无异;
- Hermes-SDK:自研“热点发现+本地缓存”功能的 SDK 封装,Jedis-Client 通过与它交互来集成相应能力;
- Hermes 服务端集群:接收 Hermes-SDK 上报的缓存访问数据,进行热点探测,将热点 key 推送给 Hermes-SDK 做本地缓存;
- 缓存集群:由代理层和存储层组成,为应用客户端提供统一的分布式缓存服务入口;
- 基础组件:etcd 集群、Apollo 配置中心,为 TMC 提供“集群推送”和“统一配置”能力;
基本流程
1)key 值获取
- Java 应用调用 Jedis-Client 接口获取 key 的缓存值时,Jedis-Client 会询问 Hermes-SDK 该 key 当前是否是 热点key;
- 对于 热点key ,直接从 Hermes-SDK 的 热点模块 获取热点 key 在本地缓存的 value 值,不去访问 缓存集群 ,从而将访问请求前置在应用层;
- 对于非 热点key ,Hermes-SDK 会通过 Callable回调 Jedis-Client 的原生接口,从 缓存集群 拿到 value 值;
- 对于 Jedis-Client 的每次 key 值访问请求,Hermes-SDK 都会通过其 通信模块 将 key 访问事件 异步上报给 Hermes 服务端集群 ,以便其根据上报数据进行“热点探测”;
2)key 值过期
- Java 应用调用 Jedis-Client 的 set() del() expire()接口时会导致对应 key 值失效,Jedis-Client 会同步调用 Hermes-SDK 的 invalid()方法告知其“key 值失效”事件;
- 对于 热点 key ,Hermes-SDK 的 热点模块 会先将 key 在本地缓存的 value 值失效,以达到本地数据强一致。同时 通信模块 会异步将“key 值失效”事件通过 etcd 集群 推送给 Java 应用集群中其他 Hermes-SDK 节点;
- 其他 Hermes-SDK 节点的 通信模块 收到 “key 值失效”事件后,会调用 热点模块 将 key 在本地缓存的 value 值失效,以达到集群数据最终一致;
3)热点发现
- Hermes 服务端集群 不断收集 Hermes-SDK上报的 key 访问事件,对不同业务应用集群的缓存访问数据进行周期性(3s 一次)分析计算,以探测业务应用集群中的热点 key列表;
- 对于探测到的热点 key列表,Hermes 服务端集群 将其通过 etcd 集群 推送给不同业务应用集群的 Hermes-SDK 通信模块,通知其对热点 key列表进行本地缓存;
4)配置读取
- -Hermes-SDK 在启动及运行过程中,会从 Apollo 配置中心 读取其关心的配置信息(如:启动关闭配置、黑白名单配置、etcd 地址…);
- Hermes 服务端集群 在启动及运行过程中,会从 Apollo 配置中心 读取其关心的配置信息(如:业务应用列表、热点阈值配置、etcd 地址…)
稳定性
TMC 本地缓存稳定性表现在以下方面:
- 数据上报异步化:Hermes-SDK 使用 rsyslog技术对“key 访问事件”进行异步化上报,不会阻塞业务;
- 通信模块线程隔离:Hermes-SDK 的 通信模块 使用独立线程池+有界队列,保证事件上报&监听的 I/O 操作与业务执行线程隔离,即使出现非预期性异常也不会影响基本业务功能;
- 缓存管控:Hermes-SDK 的 热点模块 对本地缓存大小上限进行了管控,使其占用内存不超过 64MB(LRU),杜绝 JVM 堆内存溢出的可能;
一致性
TMC 本地缓存一致性表现在以下方面:
- Hermes-SDK 的 热点模块 仅缓存 热点 key 数据,绝大多数非热点 key数据由 缓存集群 存储;
- 热点 key 变更导致 value 失效时,Hermes-SDK 同步失效本地缓存,保证 本地强一致;
- 热点 key 变更导致 value 失效时,Hermes-SDK 通过 etcd 集群 广播事件,异步失效业务应用集群中其他节点的本地缓存,保证 集群最终一致;
热点发现
整体流程

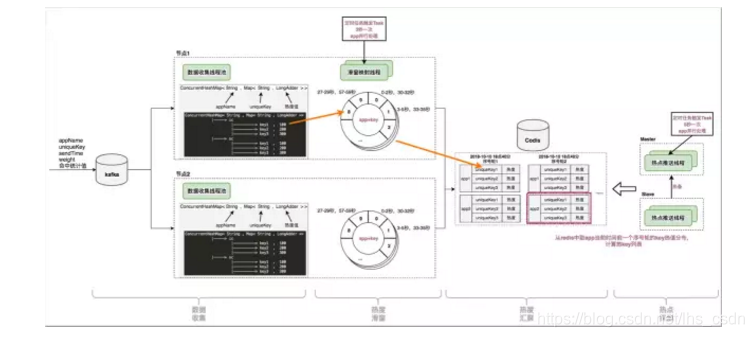
TMC 热点发现流程分为四步:
- 数据收集:收集 Hermes-SDK 上报的 key 访问事件;
- 热度滑窗:对 App 的每个 Key,维护一个时间轮,记录基于当前时刻滑窗的访问热度;
- 热度汇聚:对 App 的所有 Key,以 的形式进行 热度排序汇总;
- 热点探测:对 App,从 热 Key 排序汇总 结果中选出 TopN 的热点 Key ,推送给 Hermes-SDK;
数据收集
Hermes-SDK通过本地 rsyslog将 key 访问事件以协议格式放入 kafka,Hermes 服务端集群的每个节点消费 kafka 消息,实时获取 key 访问事件。
访问事件协议格式如下:
1.appName:集群节点所属业务应用
2.uniqueKey:业务应用 key 访问事件 的 key
3.sendTime:业务应用 key 访问事件 的发生时间
4.weight:业务应用 key 访问事件 的访问权值
Hermes 服务端集群节点将收集到的 key 访问事件存储在本地内存中,内存数据结构为 Map<string,map>,对应业务含义映射为 Map<appname,map>。
热度滑窗
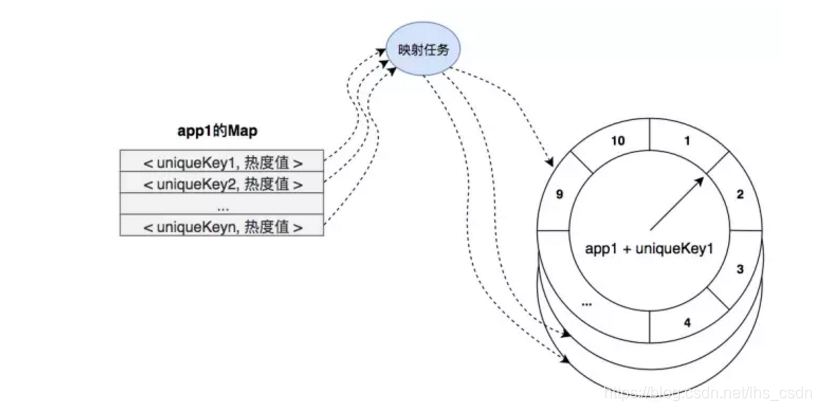
时间滑窗
Hermes 服务端集群节点,对每个 App 的每个 key,维护了一个 时间轮:
- 时间轮中共 10 个 时间片,每个时间片记录当前 key 对应 3 秒时间周期的总访问次数;
- 时间轮 10 个时间片的记录累加即表示当前 key 从当前时间向前 30 秒时间窗口内的总访问次数;
映射任务
Hermes 服务端集群节点,对每个 App 每 3 秒 生成一个 映射任务,交由节点内 “缓存映射线程池” 执行。映射任务内容如下:
- 对当前 App,从 Map<appname,map>< appname,map<="" code="">中取出 appName 对应的 Map Map>;
- 遍历 Map>中的 key,对每个 key 取出其热度存入其 时间轮 对应的时间片中;
热度汇聚
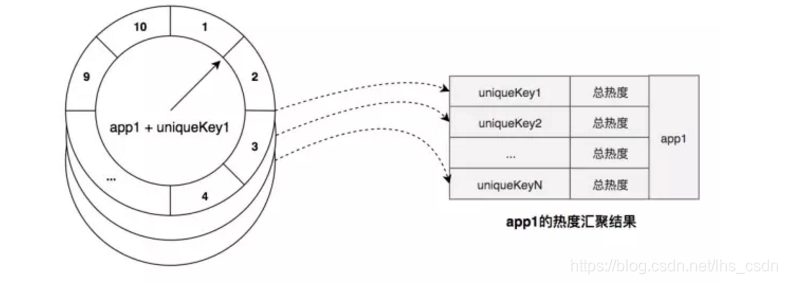
完成第二步“热度滑窗”后,映射任务继续对当前 App 进行“热度汇聚”工作:
- 遍历 App 的 key,将每个 key 的 时间轮 热度进行汇总(即 30 秒时间窗口内总热度)得到探测时刻 滑窗总热度;
- 将 < key , 滑窗总热度 > 以排序集合的方式存入 Redis 存储服务 中,即 热度汇聚结果;
热点探测
- 在前几步,每 3 秒 一次的 映射任务 执行,对每个 App 都会产生一份当前时刻的 热度汇聚结果
- Hermes 服务端集群 中的“热点探测”节点,对每个 App,只需周期性从其最近一份 热度汇聚结果 中取出达到热度阈值的 TopN 的 key 列表,即可得到本次探测的 热点 key 列表;
TMC 热点发现整体流程如下图:
特性总结
实时性
Hermes-SDK 基于rsyslog + kafka 实时上报 key 访问事件。映射任务3 秒一个周期完成“热度滑窗” + “热度汇聚”工作,当有 热点访问场景出现时最长 3 秒即可探测出对应 热点 key。
准确性
key 的热度汇聚结果由“基于时间轮实现的滑动窗口”汇聚得到,相对准确地反应当前及最近正在发生访问分布。
扩展性
Hermes 服务端集群节点无状态,节点数可基于 kafka 的 partition 数量横向扩展。
“热度滑窗” + “热度汇聚” 过程基于 App 数量,在单节点内多线程扩展。
参考资料:https://tech.youzan.com

















 1151
1151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









