






目标检测领域DETR系列模型论文`
Stable-DINO:Detection Transformer with Stable Matching

文章目录
论文及源码
提示:这里可以添加本文要记录的大概内容:
论文链接:https://arxiv.org/abs/2304.04742
源码链接:https://github.com/IDEA-Research/Stable-DINO
一、背景
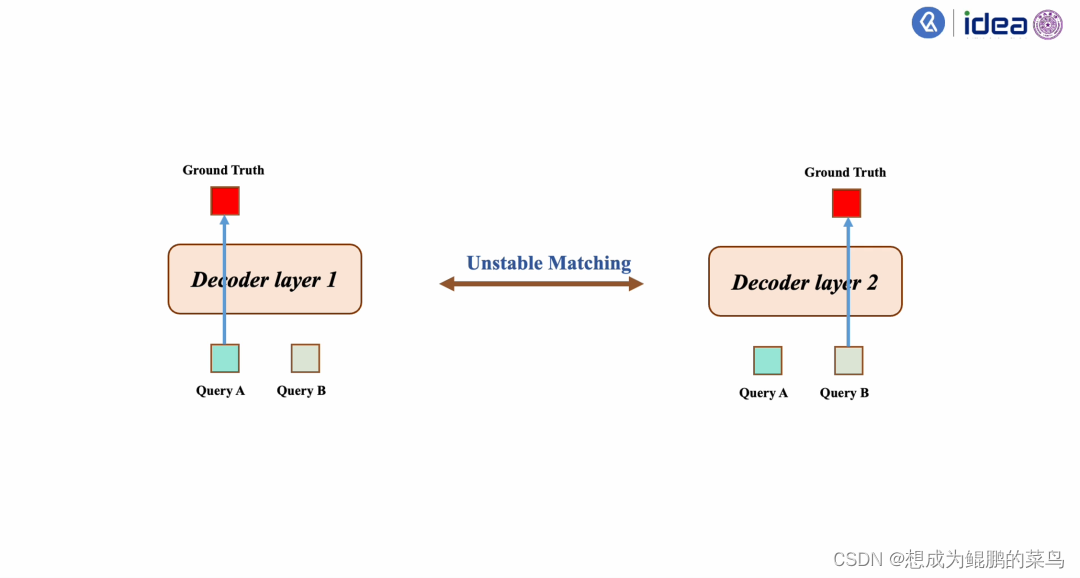
不同Decoder层之间,目标检测query和真值(Ground Truth)匹配不稳定性的问题。
例如,下图所示。在第一个Decoder层中存在两个query,分别为query A和query B,其中query A与Ground Truth匹配。而在第二个Decoder层中,却是query B与Ground Truth匹配。 这两种不同的匹配结果会使得模型朝着两个不同的方向进行优化,从而出现训练不稳定的问题。
二、论文内容
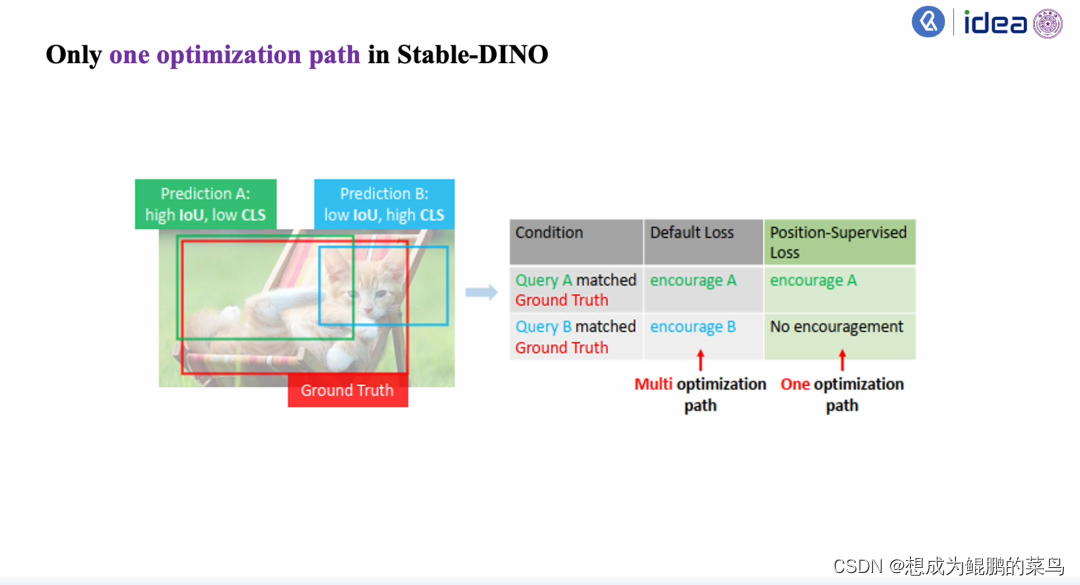
1.Multi optimization path
Ground Truth是红色框,Prediction A是绿色框,而Prediction B是蓝色框。作者发现Prediction A和Ground Truth的匹配重叠度会更高,因此它有个更高的IOU值,却会有一个更低的分类的指数;Prediction B有一个更低的IOU的值,却有一个更高的分类指数。
作者发现在训练过程中Ground Truth有可能匹配到这两个中的任意一个结果:当Ground Truth和Production A匹配的时候,模型会使得Prediction A朝着Ground Truth方向优化;而Prediction B和Ground Truth匹配之后,Prediction B会朝Ground Truth方向进行优化。作者发现这两个不同的优化目标,有一个是让一个低分类值的Prediction变成高分类值;而另一个是让一个低IoU score的预测值变成一个高的IoU score值。但是由于Detection Transformmer模型是一个基于匈牙利匹配的一个one to one的匹配,这两种不同的优化目标就会使得这个模型在训练中变得不稳定,作者把这种现象称为Multi optimization path现象(多优化路径)。
2.改进
作者希望加上Loss之后这个模型,可以使Query B匹配到之后朝着A方向优化,但是当Query A匹配到这个Ground Truth的时候,不去它鼓励它的匹配。这就是该论文的核心目的。
先回顾一下在DINO或者在之前的detection Transformer里常用的几个方案。一个是它的分类Loss——这是个标准的分类Loss,这是一个在分类前匹配过程中标准的匹配的损失。

作者提出了Position-Supervised Loss和Position-modulated matching Cost。在Stable-DINO里作者做了一个非常简单的改进。红字是作者唯一改进的部分:用它的与s ——一个和IoU有关的值去监督它的分类的score,相当于给它的分类score设置了一个上限。同理,作者也会使用一个和IoU有关的值去调制它的分类Score,使得它匹配的过程中匹配的损失不仅考虑到分类,还考虑到了IoU的值。
下面来看为什么该论文的方案可以解决这个问题:
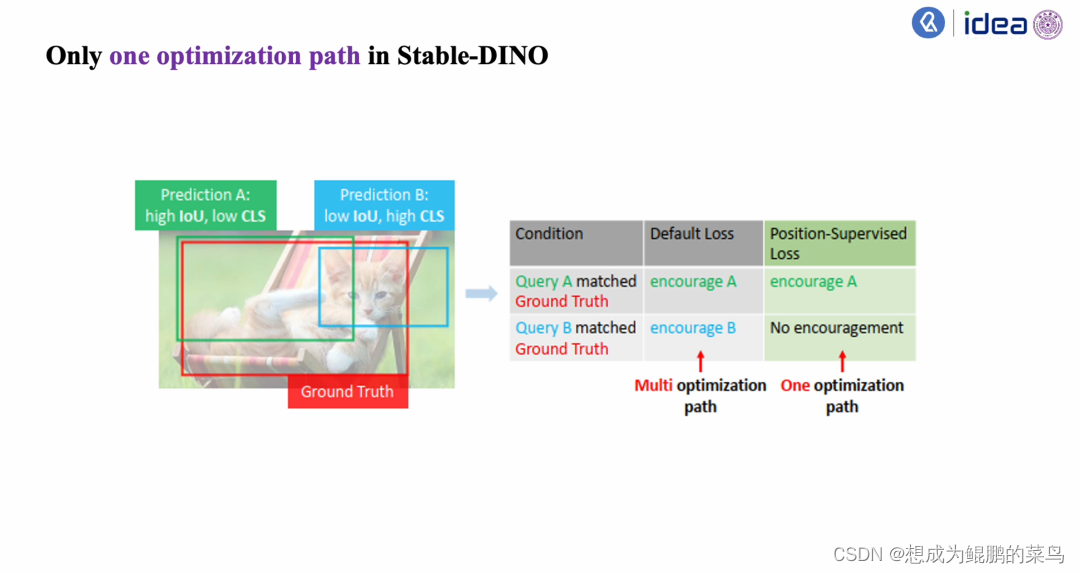
我们看到这里还是Prediction A、Prediction B以及一个红色Ground Truth。当Prediction A和Ground Truth匹配到的时候,这个Loss依然会要求Prediction A朝着Ground Truth去优化;但是当Prediction B和Ground Truth匹配到的时候(注意一下,Prediction B有一个比较低的IOU值和比较高的分类值)我们发现,这时候就会要求我们的模型——它的classification score朝着IoU方向去优化,即我们会用IOU去监督classification score。
在这种情况下会发现,我们不会鼓励Prediction B和Ground Truth去做匹配,这就会使得这条路径上没有优化,这样我们就永远在鼓励QueryA和Ground Truth做匹配——也就是避免了Multi Optimization path现象。
作者对比了使用Stable Matching之后DINO之前和之后的结果。
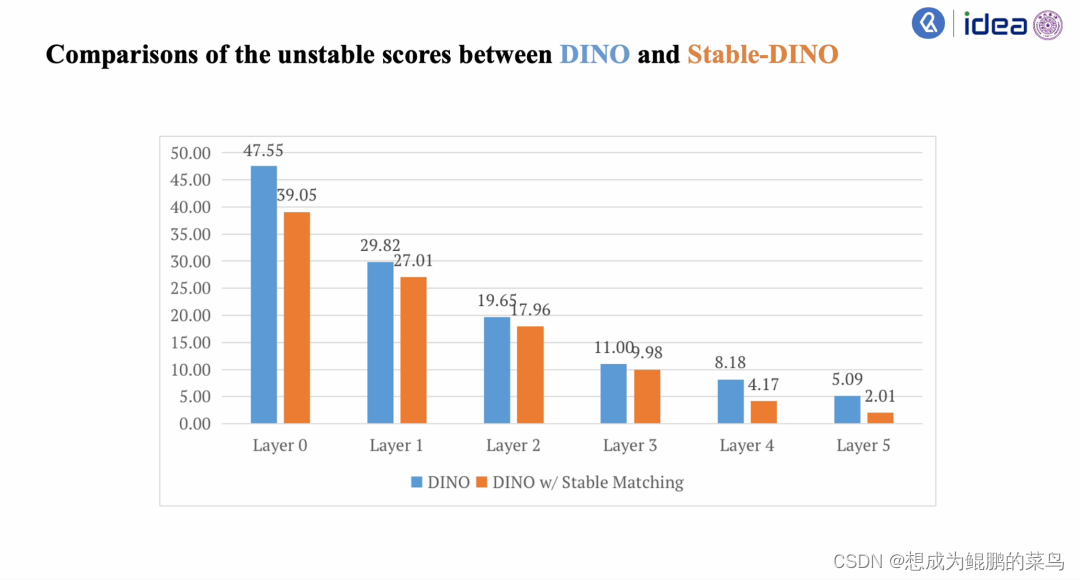
在这里比较的是一个不稳定的分数,就是指两层layer之间它们匹配结果到底有多少层不一样。作者发现,在使用了Sable Match的方法之后,Stable-DINO相比于DINO而言就拥有了更好的匹配的稳定性,橙色相比于蓝色的点数要更低。
3.Memory fusion
除了这两个方案以外,作者在文章里还提出了Memory fusion的方案,可以使得模型有更快的收敛速度。可以看到,a图是指原始的模型的设计,在backbone之后,有几层堆叠以后的layer——这些Encoder layer之间是一层一层过的。
作者发现可以将Backbone和Encoder layer的feature提取出来拼接到一起,然后再重新投影回原始维度送入Decoder,这可以使得模型有更快的收敛速度。右图就是我们收敛速度的对比:
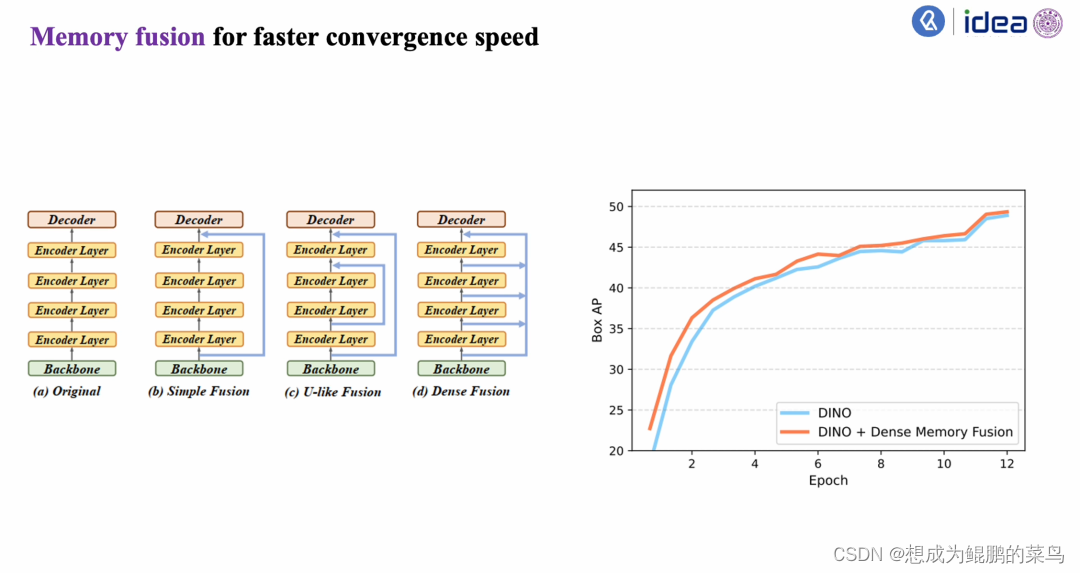
蓝色是DINO,橙色是使用了Dense memory fusion之后的性能,在这里比较了一下模型的performance:
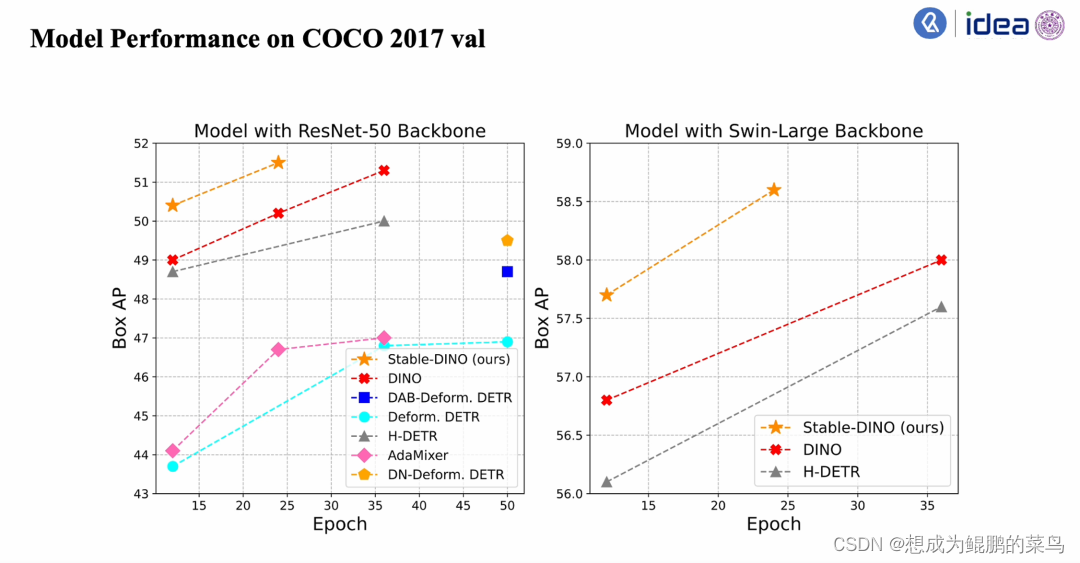
在COCO 2017 validation set上作者发现Stable-DINO模型相比于DINO更好。注意一下,DINO已经是之前最好的结果了——它是红色的曲线,相比DINO就有了一个点的提升。
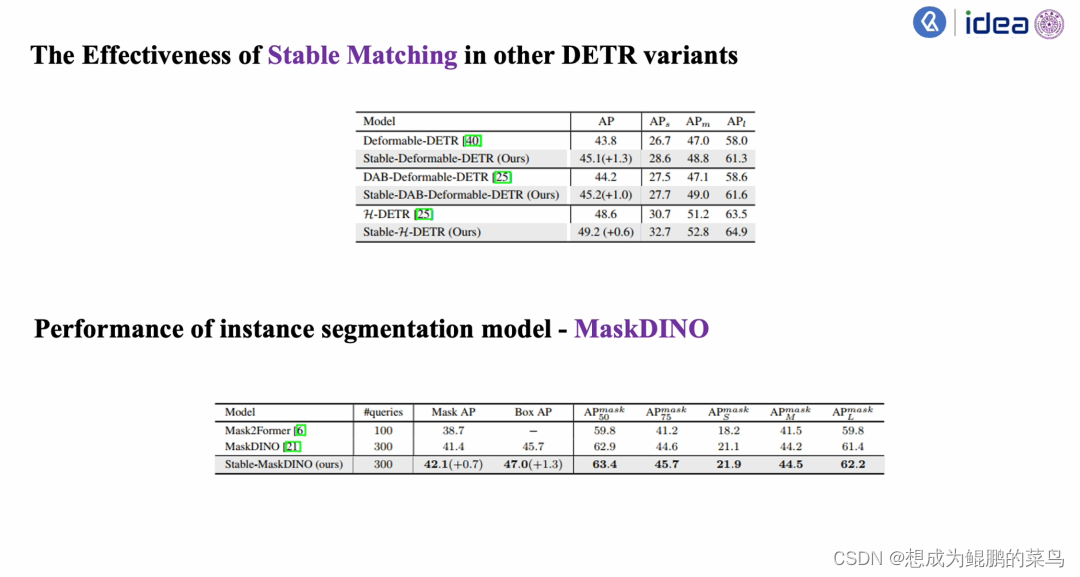
作者发现Stable-DINO模型不仅在ResNet-50这种小backbone上有比较好的性能,在一些大的backbone,比如Swin large上,依然有比较不错的稳定的性能的提升。之后作者又将该方法扩展到了其他的DETR类模型上:比如说在Deformable DETR和H-DETR上。发现模型都有了稳定的一个性能提升。除了在目标检测模型上,作者还在一些分割模型上——比如instance segmentation模型在MaskDINO模型上依然有稳定的性能提升。
最后就是展示可视化的结果:

左边这一列是原始DINO结果,中间这列是Stable DINO的结果,而右边这列是Ground Truth。可以看到左上角这张图会有重叠的elephant的一个现象,但是在右边这张图就没有
在左边这张图里其实漏检了bicycle或者更多的物体,但是在中间Stable DINO这个结果里有更好的检测效果。
贡献总结
提示:这里对文章进行总结:
1.Position-supervised Loss,使用IoU信息去监督分类信息;
2.Position-modulated Cost,使用IoU信息调制分类信息,是分类信息能更好的同时表示分类和IoU值;
3.Memory Fusion,使模型有更快的收敛速度。
参考
笔者刚开始学习,内容主要是搬运ReadPaper微信公众号内容,主要目的是整理记忆。
ReadPaper微信公众号:https://mp.weixin.qq.com/s?__biz=MzkyMTIwMjg4OA==&mid=2247519168&idx=2&sn=42e15b41407c61f37aa8ef3425c2ef92&chksm=c185f267f6f27b71a21895eb3821ebeac3726e3ab04b3a7bbe67dec5114809a961a539fb1906&mpshare=1&scene=1&srcid=1110nu0mjgs4ftmaXJXo36m0&sharer_shareinfo=9f429d273a7ce3e483afefe0d9fca07e&sharer_shareinfo_first=9f429d273a7ce3e483afefe0d9fca07e#rd

















 1220
1220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









