



1. 环境配置
1.1 Python 安装
-
版本要求:推荐安装 Python 3.11,因 Python 3.12 存在与
jieba、setuptools的兼容性问题,且 NumPy 2.2.3 暂不支持 Python 3.13。 -
环境变量配置:安装时勾选 “Add Python to PATH”;若未勾选,需手动添加环境变量。
-
验证安装:
python --version
1.2 虚拟环境配置
-
创建虚拟环境:
python -m venv venv
-
激活虚拟环境:
Windows:venv\Scripts\activate
1.3 依赖包安装
在激活的虚拟环境中执行以下命令:
pip install flask jieba numpy transformers pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
1.4 运行项目
-
启动服务:
python xinfa_QA.py
-
访问网页:
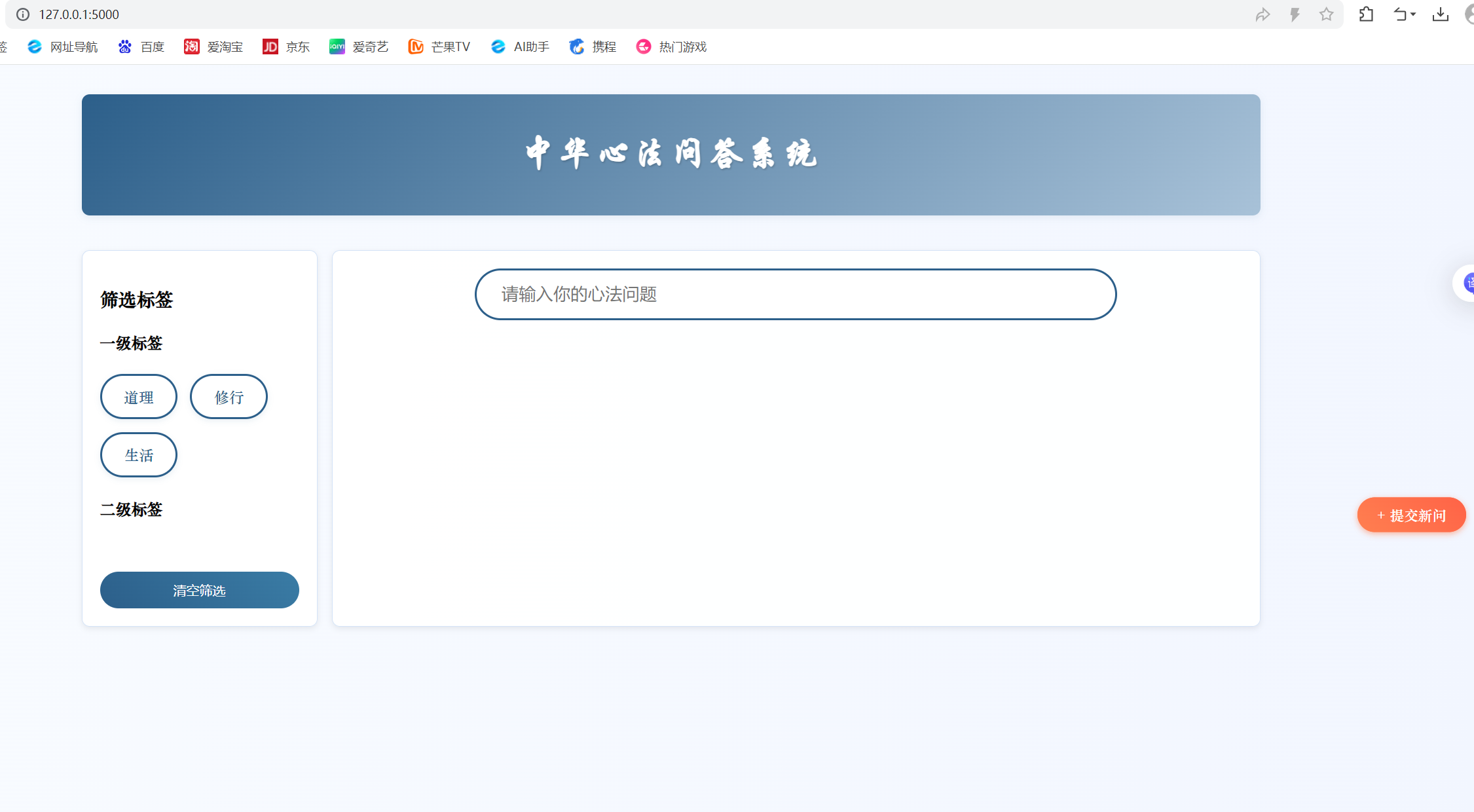
打开浏览器输入 http://127.0.0.1:5000 即可。
1.5 后续使用
关闭终端后重新运行项目时,仅需:
-
激活虚拟环境(见 1.2)。
-
再次执行
python xinfa_QA.py。
2. 代码架构与技术实现
2.1 核心模块与依赖库
| 模块类别 | 功能说明 |
|---|---|
| 基础库 | os, csv, json - 处理文件I/O和数据序列化 |
| NLP处理 | jieba - 中文分词,torch - 深度学习框架 |
| 模型框架 | transformers - 加载预训练BERT模型 |
| Web服务 | flask - 提供RESTful API接口 |
2.2 核心类设计
2.2.1 TagConfig 类
class TagConfig:
"""标签管理系统"""
def __init__(self, csv_path):
self.LEVEL1 = set() # 存储一级标签
self.LEVEL2 = {} # 二级标签映射 {一级标签: [二级标签列表]}
self._load_csv(csv_path) # 初始化时自动加载数据
2.2.2 QASystem 类(关键方法)
| 方法 | 功能描述 |
|---|---|
_load_model() | 加载BERT tokenizer和预训练模型 (bert-base-chinese) |
_prepare_vectors() | 预计算所有问题的768维BERT嵌入向量(启动时执行) |
search() | 混合搜索策略:BERT语义相似度(70%) + Jieba关键词匹配(30%) |
2.3 关键算法流程
2.3.1 文本预处理流程
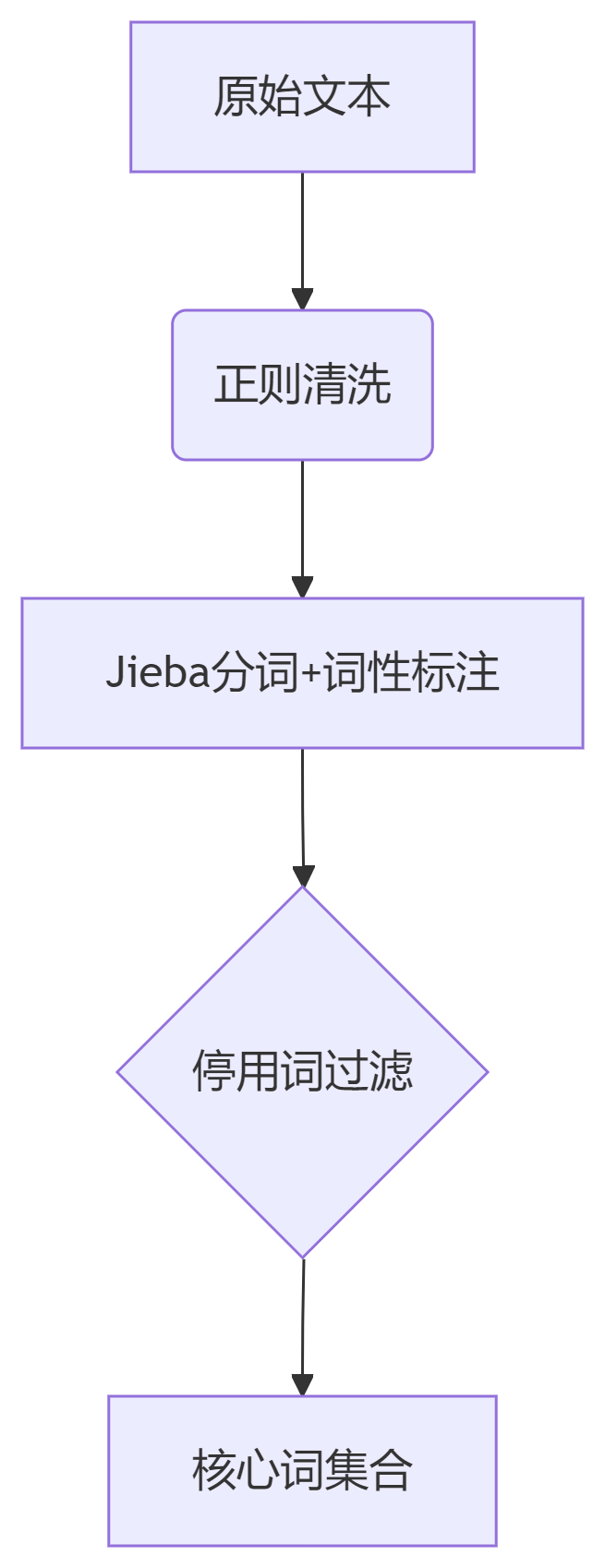
2.3.2 BERT语义编码原理
-
输入处理:
-
添加特殊标记:
[CLS]文本[SEP] -
Token转换为ID:
[101, 3928, 1765, 102]
-
-
多层语义提取:
# BERT的12层Transformer输出 with torch.no_grad(): outputs = model(**inputs, output_hidden_states=True) # 取最后4层加权平均 weights = [0.15, 0.25, 0.35, 0.25] embeddings = sum(w * h for w, h in zip(weights, outputs.hidden_states[-4:])) -
相似度计算:
cosine_sim = torch.nn.functional.cosine_similarity(q_vec, db_vecs, dim=1)
2.4 API接口设计
| 路由端点 | HTTP方法 | 请求格式 | 响应格式 |
|---|---|---|---|
/search | POST | JSON: {query, tags[]} | {top3_answers, similarity_scores} |
/submit_question | POST | FormData: text, answer, tags | {status: 200/400} |

















 1322
1322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









