



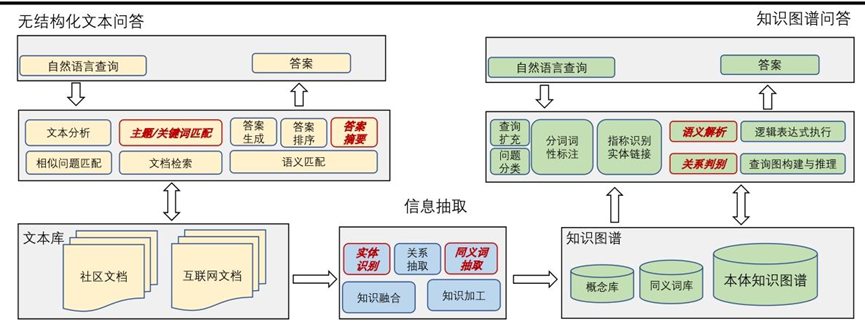
1. 课题解决的问题、输入输出及关键步骤
解决的问题:
① 知识图谱问答:让计算机理解并回答复杂问题(如“如何预防稻瘟病并提高产量?”),涉及语义解析和逻辑推理。
② 文本生成与摘要:从长篇文章中提取核心内容(如自动生成论文摘要)。
③ 信息抽取:从文本中识别关键信息(如人名、地名)并整理成结构化数据。
输入:
用户问题(自然语言,如“水稻常见病害有哪些?”)
知识图谱(结构化数据,如农业知识库)
无结构化文本(如论文、网页文章)
输出:
直接答案(如“稻瘟病、纹枯病”)
结构化答案(如表格对比不同病害症状)
文本摘要、关键词、实体分类结果
关键步骤:
- 自然语言理解:分析问题意图,拆解复杂问题。
- 知识检索:从知识库或文本中查找相关信息。
- 答案生成与排序:提供最匹配的答案,并优化可读性。
2. 各步骤的作用与原理
(1)知识图谱问答
作用:精准回答基于知识库的问题。
原理:
简单问题:识别关键词,匹配知识库中的关系(如“谁导演了《盗梦空间》?”→匹配“导演-克里斯托弗·诺兰”)。
复杂问题:拆解问题(如“如何预防稻瘟病?”→分解为“病害原因→防治方法”),再组合答案。
(2)文本生成与摘要
作用:提炼文章核心内容。
原理:
摘要生成:先提取关键句(草稿),再优化语言(精炼)。
关键词提取:分析高频词和重要实体(如“水稻”“病害”)。
(3)信息抽取
作用:从文本中提取结构化数据(如“某论文提到‘稻瘟病由真菌引起’→提取‘稻瘟病-致病原因-真菌’”)。
原理:训练模型识别实体(如病害名、农药名)和关系(如“治疗”“预防”)。
3. 课题的难点及解决方案
难点1:复杂问题理解困难
问题:用户提问可能含糊或多层逻辑(如“怎样种水稻更赚钱?”涉及种植技术、成本、市场等)。
解决:
层次化解析:将问题拆解成子问题(如“高产技术→成本控制→市场价格”)。
知识图谱辅助:用结构化数据(如“水稻-施肥量-产量”)辅助推理。
难点2:文本生成不准确
问题:生成的摘要可能遗漏重点或语义混乱。
解决:
分步生成:先提取关键句,再优化语言(类似“先写大纲再润色”)。
预训练模型:用GPT等模型补全上下文,提高连贯性。
难点3:数据噪声干扰
问题:文本中的错误标注或无关信息影响结果(如“水稻”误标为“小麦”)。
解决:
噪声过滤模型:自动修正错误标签(如通过上下文判断“水稻”更合理)。
多数据源验证:对比不同资料库,确保答案可靠性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









