




 本文探讨了一种树形结构问题,通过二分搜索找到树上根节点到连续叶节点距离的最大值最小解。文章详细介绍了如何使用DFS求解叶节点及相邻叶节点的LCA,以及二分搜索中检查函数的正确实现。
本文探讨了一种树形结构问题,通过二分搜索找到树上根节点到连续叶节点距离的最大值最小解。文章详细介绍了如何使用DFS求解叶节点及相邻叶节点的LCA,以及二分搜索中检查函数的正确实现。
https://www.luogu.com.cn/problem/P6058
题目大意,求树上根节点到分段连续叶节点的距离的最大值最小。看到最大值最小,当然先往二分答案上去考虑了。
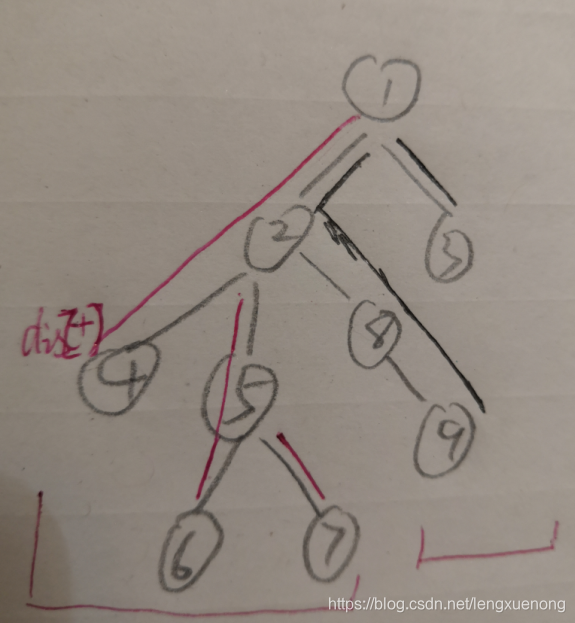
怎样求连续叶节点的距离呢?如下图所示dis[4]+(dis[6]-dis[lca(4,6)]+...
因此我们需要求出连续叶节点的Lca.一般情况下的LCA可以用倍增或者tarjan,但这个有点特殊,他是连续的叶节点的lca,我们在dfs的过程中只需要记录回溯后的深度最小的点,那么这个点就是其lca。因此我们可以仅用一次dfs求出需要的叶节点,叶节点到根节点的距离,相邻叶节点的LCA。
在做题的过程中总得40分,就以为自己LCA写错了,换了倍增求,还是一样的错。那就是二分的检查函数写错了,查了很久才发现,分段检查的时候忘了判断初始的dis[]是否符合要求。
还有一个问题,下面得代码开氧气优化会RE,可是本蒟蒻不知道为什么。
//二分答案,枚举距离检查。
//记录每个叶子节点最近的前一个叶子节点。,求每个节点与其相邻的叶子
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N=3e5+10;
vector<pair<int,int> >g[N];
int n,k,Lca[N],Deep[N],mindep=1e9,minpoint=0;//记录其比他小的最近的节点v,和v的最近公共祖先。
int num=0,lef[N];
ll dis[N];
int dfs(int u,int fa,int dp,ll sumw) {
dis[u]=sumw,Deep[u]=dp;
for(int i=0; i<g[u].size(); i++) {
int v=g[u][i].first;
ll w=g[u][i].second;
if(v==fa)continue;
if(g[v].size()==1) {
Lca[v]=minpoint;
mindep=1e9;
lef[++num]=v;
}
dfs(v,u,dp+1,sumw+w);
}
if(mindep>Deep[u])mindep=Deep[u],minpoint=fa;
}
bool check(ll x) { //计算距离x需要分几段。
int cnt=1;
ll sum=dis[lef[1]];
for(int i=2; i<=num; i++) {
if(sum>x)return 0;//一开始没想到这句,总得40分:(
int v=lef[i],u=Lca[v];
if(sum+dis[v]-dis[u]<=x)sum+=dis[v]-dis[u];
else
cnt++,sum=dis[v];
if(cnt>k)return 0;//需要的人手多余k个,这个时间太短了,增加时间
}
return cnt<=k; //时间还可以更少
}
int main() {
scanf("%d%d",&n,&k);
int u,v,w;
ll l=0,r=0,mid,ans;
for(int i=1; i<n; i++) {
scanf("%d%d%d",&u,&v,&w);
g[u].push_back(make_pair(v,w));
g[v].push_back(make_pair(u,w));
r+=(ll)w;
}
dfs(1,0,0,0);
while(l<=r) {
mid=(l+r)/2;
if(check(mid))
ans=mid,r=mid-1;
else l=mid+1;
}
ans*=2;
printf("%lld\n",ans);
}

















 105
105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









