




 本文介绍了Hive采用Tez优化MR任务的方式,通过DAG来减少IO冗余,详细阐述了Tez的部署过程、常见问题及解决方案,并对比测试了Tez与MR在Hive上的性能差异,包括scan、聚合、join等操作。
本文介绍了Hive采用Tez优化MR任务的方式,通过DAG来减少IO冗余,详细阐述了Tez的部署过程、常见问题及解决方案,并对比测试了Tez与MR在Hive上的性能差异,包括scan、聚合、join等操作。
背景:
如果作业由多个MR任务完成,则必然经过多次完整的Map–shuffer–Reduce,中间节点的数据多次写入HDFS,浪费IO读写。(可以将HDFS理解为多个任务之间的共享存储。)Tez的引入可以较小的代价的解决这一问题。
Tez采用了DAG(有向无环图)来组织MR任务。
核心思想:将Map任务和Reduce任务进一步拆分,Map任务拆分为Input-Processor-Sort-Merge-Output,Reduce任务拆分为Input-Shuffer-Sort-Merge-Process-output,Tez将若干小任务灵活重组,形成一个大的DAG作业。
Tez与oozie不同:oozie只能以MR任务为整体来管理、组织,本质上仍然是多个MR任务的执行,不能解决上面提到的多个任务之间硬盘IO冗余的问题。 Tez只是一个Client,部署很方便。
目前Hive使用了Tez(Hive是一个将用户的SQL请求翻译为MR任务,最终查询HDFS的工具Tez采用了DAG(有向无环图)来组织MR任务。 核心思想:将Map任务和Reduce任务进一步拆分,Map任务拆分为Input-Processor-Sort-Merge-Output,Reduce任务拆分为Input-Shuffer-Sort-Merge-Process-output,Tez将若干小任务灵活重组,形成一个大的DAG作业。 Tez与oozie不同:oozie只能以MR任务为整体来管理、组织,本质上仍然是多个MR任务的执行,不能解决上面提到的多个任务之间硬盘IO冗余的问题。 Tez只是一个Client,部署很方便。 目前Hive使用了Tez(Hive是一个将用户的SQL请求翻译为MR任务,最终查询HDFS的工具)
传统的MR:
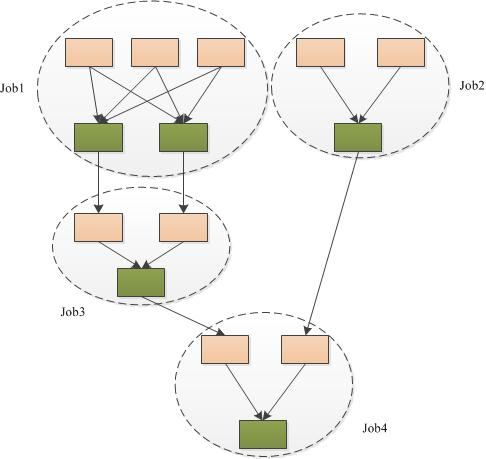
tez:
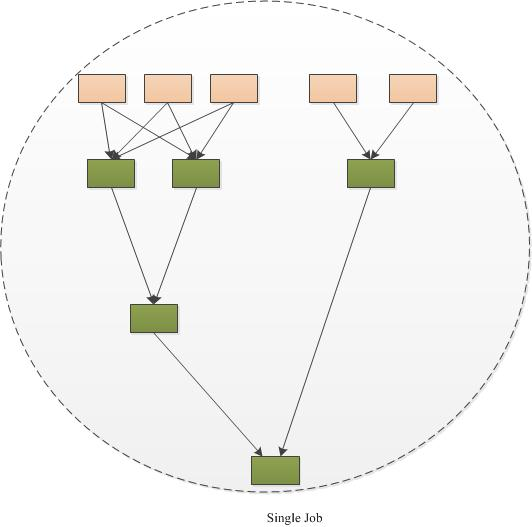
TEZ技术:
- Application Master Pool 初始化AM池。Tez先将作业提交到AMPoolServer服务上。AMPoolServer服务启动时就申请多个AM,Tez提交作业会优先使用缓冲池资源
- Container Pool AM启动时会预先申请多个Container
- Container重用
Tez实现方法:
Tez对外提供了6种可编程组件,分别是:
- Input:对输入数据源的抽象,它解析输入数据格式,并吐出一个个Key/value
- Output:对输出数据源的抽象,它将用户程序产生的Key/value写入文件系统
- Paritioner:对数据进行分片,类似于MR中的Partitioner
- Processor:对计算的抽象,它从一个Input中获取数据,经处理后,通过Output输出
- Task:对任务的抽象,每个Task由一个Input、Ouput和Processor组成
- Maser :管理各个Task的依赖关系,并按顺依赖关系执行他们
除了以上6种组件,Tez还提供了两种算子,分别是Sort(排序)和Shuffle(混洗),为了用户使用方便,它还提供了多种Input、Output、Task和Sort的实现
TEZ执行引擎的问世,可以帮助我们解决现有MR框架的一些不足,比如迭代计算和交互计算,除了Hive组件,Pig组件也将TEZ用到了自己的优化中。
另外,TEZ是基于YARN的,所以可以与原有的MR共存,不会相互冲突,在实际的应用中,我们只需在hadoop-env.sh文件中配置TEZ的环境变量,并在mapred-site.xml设置执行作业的架构为yarn-tez,这样在YARN上运行的作业就会跑TEZ计算模式,所以原有的系统接入TEZ很便捷。当然,如果我们只想Hive使用TEZ,并不想对整个系统做修改,那我们也可以单独在Hive中做修改,也很简单,这样Hive可以在MR和TEZ之间自由切换而对原有的Hadoop MR任务没有影响,所以TEZ这款计算框架的耦合很低,让我们使用很容易和方便。
1 CDH集群测试环境
| 组件 | 版本 |
|---|---|
| CDH | 5.11.0 |
| HADOOP | 2.6.0 |
| HIVE | 1.1.0 |
CDH集群中Tez部署
版本:tez-0.8.5
部署
上传Tez tar包及lib
# 上传tez-tar包至hdfs;
$ hdfs dfs -put ./tez-0.8.5.tar.gz /apps/tez/
# 拷贝编译完的Tez,apache-tez-0.8.5-src-2.6.0-cdh5.11.0/tez-dist/target/tez-0.8.5目录下的lib包至CDH-Hive的lib目录(所有Hiveserver2以及Hive Metastore Server)
$ cd apache-tez-0.8.5-src-2.6.0-cdh5.11.0/tez-dist/target/tez-0.8.5
$ cp ./*.jar /opt/cloudera/parcels/CDH-5.11.0-1.cdh5.11.0.p0.34/lib/hive/lib
$ cp ./lib/*.jar /opt/cloudera/parcels/CDH-5.11.0-1.cdh5.11.0.p0.34/lib/hive/lib
###################################################################
# 同步所有CDH-Hive节点(包括gateway,metastore,hievserver机器)
###################################################################
配置Tez配置文件
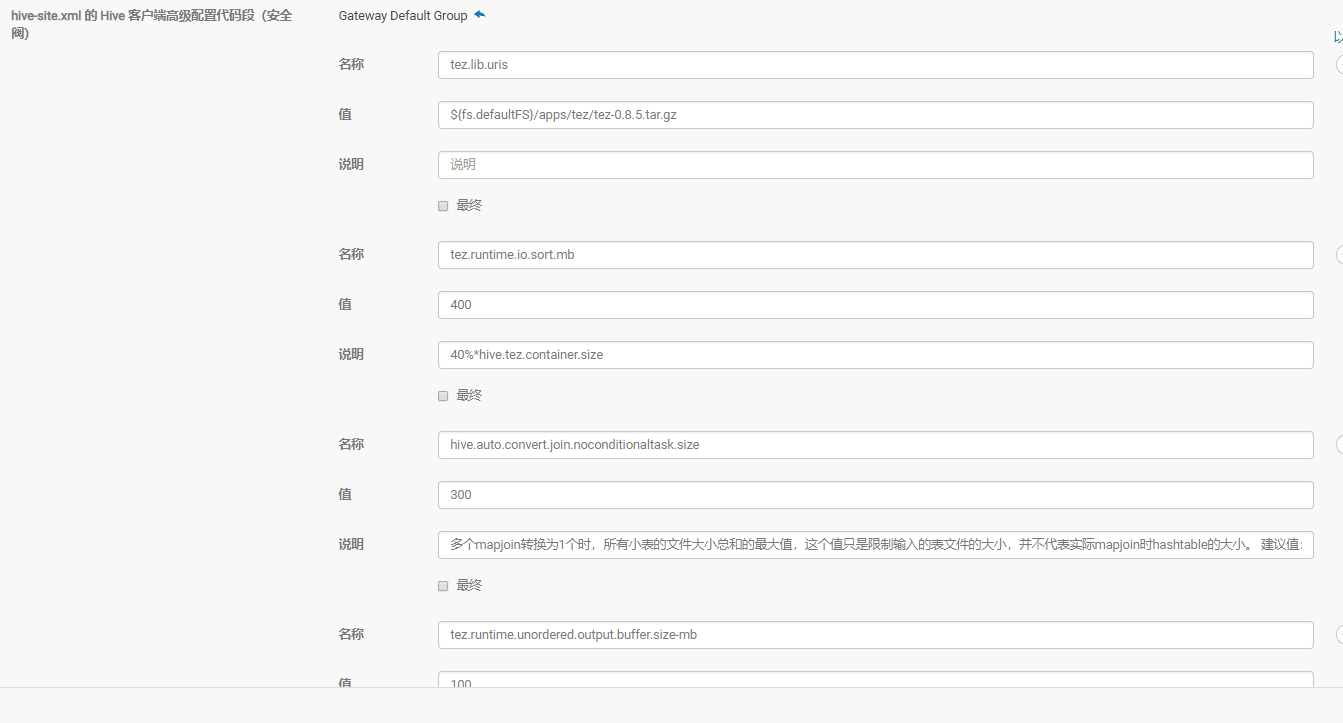
添加Tez配置文件:
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/apps/tez/tez-0.8.5.tar.gz</value>
</property>
<!-- 由于TEZ-UI与timeline之间问题没解决,暂时注释掉 -->
<!-- <property>
<name>tez.tez-ui.history-url.base</name>
<value>http://tez-ui-serverIP:port/tez-ui/</value>
</property>
<property>
<name>yarn.timeline-service.hostname</name>
<value>${timelineServerIP}</value>
</property> -->
<property>
<name>tez.runtime.io.sort.mb</name>
<value>1600</value>
<description>40%*hive.tez.container.size</description>
</property>
<property>
<name>hive.auto.convert.join.noconditionaltask.size</name>
<value>1300</value>
<description>多个mapjoin转换为1个时,所有小表的文件大小总和的最大值,这个值只是限制输入的表文件的大小,并不代表实际mapjoin时hashtable的大小。 建议值:1/3* hive.tez.container.size</description>
</property>
<property>
<name>tez.runtime.unordered.output.buffer.size-mb</name>
<value>400</value>
<description>Size of the buffer to use if not writing directly to disk.。 建议值:10%* hive.tez.container.size</description>
</property>
<property>
<name>hive.tez.container.size</name>
<value>4096</value>
<description>Set hive.tez.container.size to be the same as or a small multiple(1 or 2 times that 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2033
2033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











