




 博客讲述了Zookeeper因OOM问题导致服务挂掉及选举失败的排查过程。通过检查oom信息、数据目录、堆栈信息,发现是由于concurrentHashMap占用大量内存,其中存储了7万多条SQL节点信息,每个SQL语句达到1M大小,进一步分析确认是业务方提交的含有笛卡尔积的SQL导致。解决方案是修正SQL问题。
博客讲述了Zookeeper因OOM问题导致服务挂掉及选举失败的排查过程。通过检查oom信息、数据目录、堆栈信息,发现是由于concurrentHashMap占用大量内存,其中存储了7万多条SQL节点信息,每个SQL语句达到1M大小,进一步分析确认是业务方提交的含有笛卡尔积的SQL导致。解决方案是修正SQL问题。
一:问题:
zookeeper oom挂掉之后重启及选举失败
二:排查:
2.1 oom信息:
java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3236)
at java.io.ByteArrayOutputStream.grow(ByteArrayOutputStream.java:118)
at java.io.ByteArrayOutputStream.ensureCapacity(ByteArrayOutputStream.java:93)
at java.io.ByteArrayOutputStream.write(ByteArrayOutputStream.java:135)
at java.io.DataOutputStream.writeInt(DataOutputStream.java:197)
at org.apache.jute.BinaryOutputArchive.writeInt(BinaryOutputArchive.java:55)
at org.apache.jute.BinaryOutputArchive.startVector(BinaryOutputArchive.java:135)
at org.apache.zookeeper.txn.CreateTxn.serialize(CreateTxn.java:78)
at org.apache.zookeeper.server.persistence.Util.marshallTxnEntry(Util.java:263)
at org.apache.zookeeper.server.persistence.FileTxnLog.append(FileTxnLog.java:216)
at org.apache.zookeeper.server.persistence.FileTxnSnapLog.append(FileTxnSnapLog.java:355)
at org.apache.zookeeper.server.ZKDatabase.append(ZKDatabase.java:476)
at org.apache.zookeeper.server.SyncRequestProcessor.run(SyncRequestProcessor.java:110)
其中,FileTxnLog负责维护事务日志对外的接口,包括事务日志的写入和读取等;
2.2 最后一次数据目录
snapshot 文件大小(zookeeper的配置java内存为8G)
-rw-r--r-- 1 zookeeper zookeeper 5567252513 Jun 23 15:55 snapshot.100266e6e
-rw-r--r-- 1 zookeeper zookeeper 5620531053 Jun 23 16:29 snapshot.100273f67
-rw-r--r-- 1 zookeeper zookeeper 5612398635 Jun 23 16:55 snapshot.1002830dc
-rw-r--r-- 1 zookeeper zookeeper 7438441469 Jun 23 17:18 snapshot.10028ac25
-rw-r--r-- 1 zookeeper zookeeper 7585252375 Jun 23 17:22 snapshot.200000402
-rw-r--r-- 1 zookeeper zookeeper 7692673350 Jun 23 17:26 snapshot.3000003d5
其中snapshot的大小已经达到7个G,事务日志:
-rw-r--r-- 1 zookeeper zookeeper 1879048208 Jun 23 17:15 log.1002830de
事务日志也已经达到了1.75个G大小:
三:查看dump的堆栈信息:
-
解析dump
 clipboard.png
clipboard.png
-
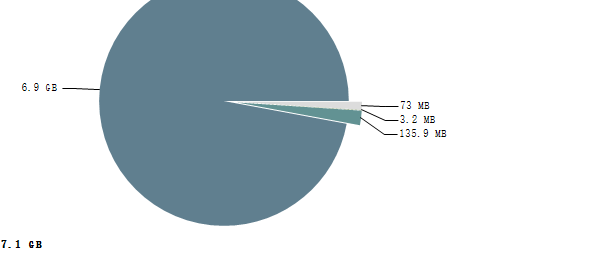
很明显看到内存问题;
点击: image.png
image.png
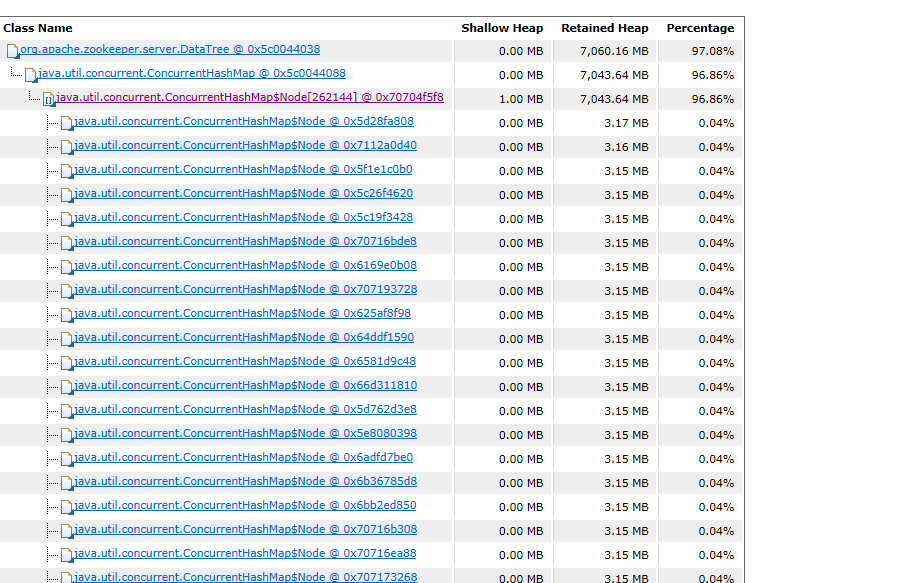
image.png
-
然后看到concurrentHashMap中占据了97%内存;里面有7万多个node节点信息;
-
再次点击查看引用对象:
 clipboard3.png
clipboard3.png -
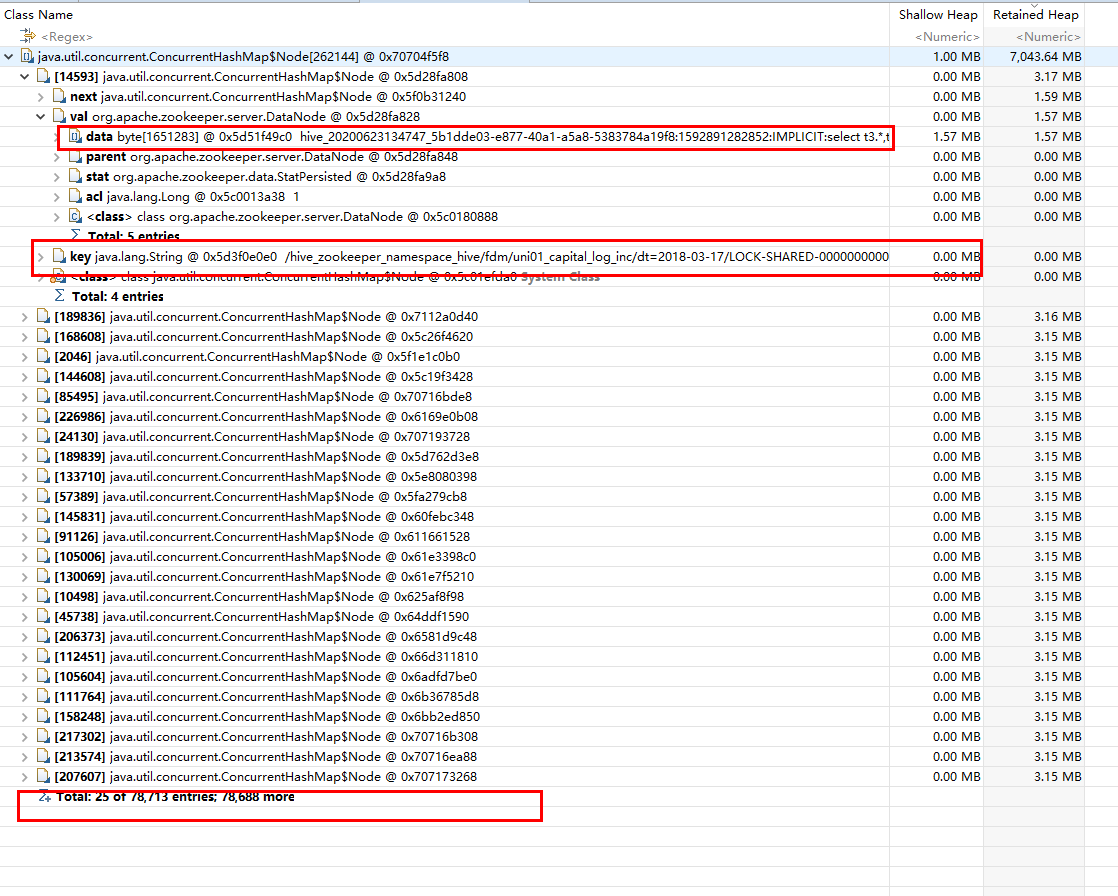
可以看到:有7万多个node,每个node的数据key与value:
- 其中key为hive在zookeeper中的目录结构;
- value则是具体的SQL语句;
-
将其中几个SQL语句保存到文件中对比查看,发现同一个SQL,而且每个SQL都达到了1M;
-
接下来就是分析SQL问题了;
四:查看zookeeper节点路径信息:
ls /hive_zookeeper_namespace_hive/gdm/LOCK-SHARED-000000
LOCK-SHARED-0000002001 LOCK-SHARED-0000002023 LOCK-SHARED-0000002025 LOCK-SHARED-0000002024 LOCK-SHARED-0000002027 LOCK-SHARED-0000001874 LOCK-SHARED-0000001876
LOCK-SHARED-0000001936 LOCK-SHARED-0000002014 LOCK-SHARED-0000001866 LOCK-SHARED-0000001907
这只是其中一个节点信息,有大量的SHARED锁,为分区查询建立的锁;存储内容则是SQL语句;
五:结论:
经过证实,是业务方提交的SQL中包含笛卡尔积导致,解决SQL问题则可以解决;


















 1024
1024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











