






 文章介绍了一种新的深度控制编辑框架,结合深度图条件和注意力机制,以提高文本驱动的3DGS渲染图像的一致性。方法通过ControlNet处理深度图编辑,利用注意力对齐潜在代码,确保编辑后的图像在多视图下外观一致。
文章介绍了一种新的深度控制编辑框架,结合深度图条件和注意力机制,以提高文本驱动的3DGS渲染图像的一致性。方法通过ControlNet处理深度图编辑,利用注意力对齐潜在代码,确保编辑后的图像在多视图下外观一致。
摘要
text-driven的编辑3D高斯方法。
首先通过使用 3DGS 渲染一组图像,并使用基于输入提示的预训练 2D 扩散模型 (ControlNet) 对其进行编辑,然后用于优化 3D 模型。
主要贡献是多视图一致性编辑。
两项:depth-conditioned editing:利用深度图,很多方法都这样做。
attention-based latent code alignment: 通过图像 latent 表示之间的self和cross 视图注意力,将编辑图像的外观调整为几个参考视图来统一。
介绍
问题提出:
首个pipeline是Instruct NeRF2NeRF [9] (IN2N),但是他不鼓励跨多个视图的一致性。即使IN2N一次编辑一张图像,同时优化3D NeRF,他收敛也很慢,渲染视图之间的不一致仍然存在。
解决:
我们提出了一个深度控制编辑框架和一个潜在代码对齐模块来显式地强制多视图一致性。
首先,由于场景的深度图自然是几何一致的,我们通过使用ControlNet[49]对深度图进行 condition 图像编辑。通过DDIM反演[41]将图像invert到它们各自的潜在代码及其深度图,然后通过编辑提示的去噪过程对其进行编辑。通过这样做,编辑后的图像继承了深度图的一致性。
其次,我们提出了一个基于注意力的潜在代码对齐模块,以鼓励编辑过程中的外观一致性。具体来说,我们通过使用自注意力和跨视图注意力,选择几个参考视图并在去噪过程中将所有其他视图的潜在代码与这些参考视图对齐。
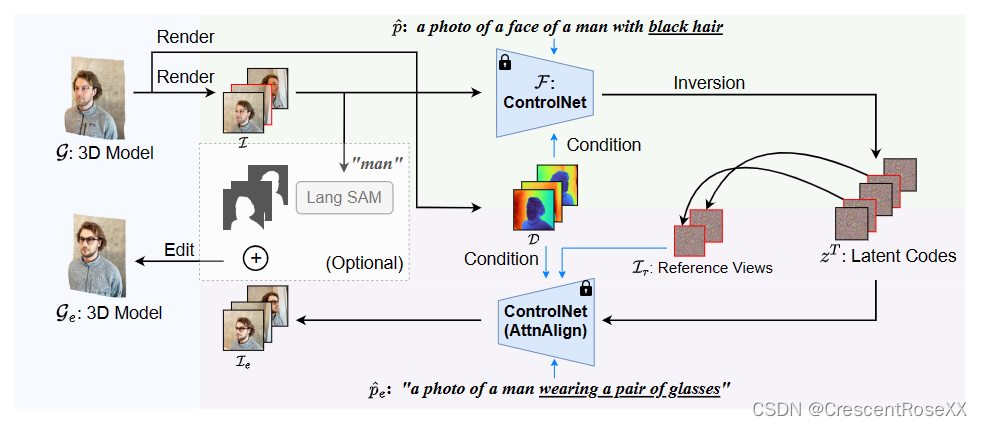
GaussCtrl pipeline。给定一个 3DGS 场景和文本指令,我们的方法使用 3DGS 渲染图像并使用文本指令编辑渲染图像,然后用于优化原始的 3DGS。我们的主要贡献是多视图一致的编辑。为此,我们提出了(1)基于ControlNet的深度条件编辑,用于几何一致性;(2)基于注意的潜在代码对齐,以提高编辑过程中的一致性
方法
给定一组图像及其重建的3D模型,我们的方法首先将每个数据集图像重新渲染到所需的分辨率,并渲染它们各自的深度图。然后,我们使用 ControlNet [49] 对所有辅以 attention-based latent code alignment 的图像进行depth-conditioned editing,以鼓励几何和外观一致性。我们使用编辑后的图像优化原始的3D模型,得到新的编辑的3D模型。
可选的还有一个Language-based Segment Anything去背景。
3.1 Background
3D高斯巴拉巴拉
ControlNet:端到端空间条件生成。我们采用 ControlNet 进行深度控制生成的能力。
3.2 Depth-conditioned Image Editing
使用ControlNet F,包括一个 U-Net 块 FU 和一个 ControlNet 块 FC,深度D。
给定一个待编辑的图像 I 及其对应的描述提示 ^p,我们首先使用 ControlNet 的 VAE 编码器计算其潜在代码 z0。然后,我们通过DDIM反演迭代地将其反转到其对应的高斯噪声zT:
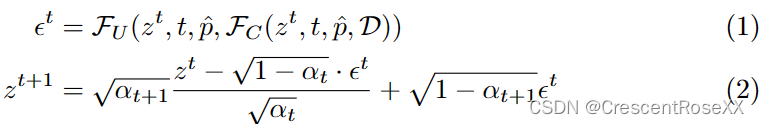
其中 t 是扩散过程的时间步长,αt 是 DDIM 调度器中的调度系数。在达到 zT 后,我们将原始提示 ^p 替换为包含更改内容的编辑提示 ^pe,并通过去噪过程获得编辑后的潜在代码 z0e:
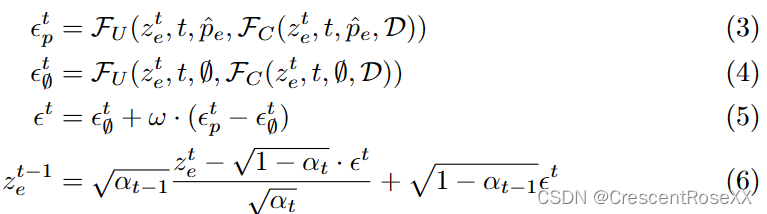
其中 zt e 表示编辑图像 (zT e = zT ) 的潜在代码,∅ 是一个空提示,等式 (5) 是classifier-free guidance [12],以提高编辑对编辑提示 ^pe 的保真度。我们使用ControlNet的VAE解码器解码z0e得到最终的图像Ie。
discussion:本来controlNet输入是随机噪声,我们换成了图像反转的噪声。
3.3 Attention-based Latent Code Alignment
几何一致性有了,但是外观一致性还没有。
具体就是在编辑过程中,通过注意力机制显式地将图像的外观与选定的参考视图对齐。
我们首先定义两个潜在代码 zi 和 zj 之间的注意力:
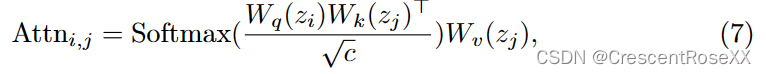
其中 Wq (·)、Wk(·) 和 Wv (·) 是线性投影,注意力操作的查询、键和值,c 是比例因子。给定 Nr 个参考图像 zt r,i 的潜在代码,其中 i = 1, 2,。.., Nr 和在时间步 t 待编辑图像 zt e 的潜在代码,我们的对齐模块定义为:
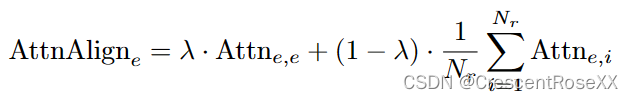
其中λ∈[0,1]。该模块将 zt e 的自注意力与 zt e 和每个参考视图 zt r,i 之间的跨视图注意力混合。跨视图注意力将所有编辑图像的外观与参考视图对齐,而 self attention 帮助每个编辑的图像保持其独特性。
(人话:先选定几个参考视图,然后把对目标视图使用自注意力,和对参考视图的cross attention。整个过程在DDIM反演后的latent空间上进行)
最后实际应用是将所有图像自我注意模块替换为U-Net块FU和ControlNet块FC中提出的对齐模块。
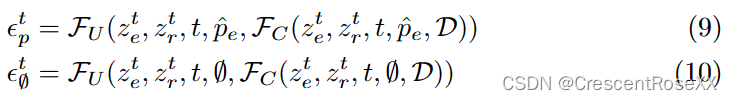

















 787
787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









