







好用的轨迹地图匹配框架可以参见:
使用graphhopper(map-matching)进行地图匹配_lei吼吼的博客-优快云博客
在上面这个博客中介绍了一些轨迹地图匹配的框架,并且详细介绍了graphhoper中的子模块map-matching(轨迹地图匹配框架)的使用方法。下面介绍一个出租车轨迹地图匹配实例:
需要进行地图匹配的数据样式:
1,30.624806,104.136604,1,2014/8/3 21:18:46
1,30.624809,104.136612,1,2014/8/3 21:18:15
1,30.624811,104.136587,1,2014/8/3 21:20:17
1,30.624811,104.136596,1,2014/8/3 21:19:16
1,30.624811,104.136619,1,2014/8/3 21:17:44
1,30.624813,104.136589,1,2014/8/3 21:19:46
1,30.624815,104.136585,1,2014/8/3 21:21:18
1,30.624815,104.136587,1,2014/8/3 21:20:48
1,30.624815,104.136639,1,2014/8/3 21:17:14
1,30.624816,104.136569,1,2014/8/3 21:22:50
1,30.624816,104.136574,1,2014/8/3 21:22:19
1,30.624816,104.136577,1,2014/8/3 21:21:49
1,30.624818,104.136564,1,2014/8/3 21:23:20
1,30.624818,104.136621,1,2014/8/3 21:15:42数据说明:第一列:车辆ID 第二列:纬度 第三列:经度 第四列:是否载客 第五列:时间戳
使用的轨迹地图匹配框架:graphhoper.map-matching
具体是匹配方法参见:
使用graphhopper(map-matching)进行地图匹配_lei吼吼的博客-优快云博客
但是使用那个地图匹配框架之前还需要做一些数据预处理,下面我将一一介绍:
一、数据排序
从数据样例就可以看出,数据不是按照时间先后排序的,但是根据常理来看轨迹数据应该是通过时间排序的,所以第一步将数据按照时间先后排序,排序代码如下:
# Author:lei吼吼
# -*- coding=utf-8 -*-
# @Time :2023/1/6 10:56
# @File: 排序.py
# @Software:PyCharm
# 这个是排序成都的那个数据集(那个数据集原来不是按照时间排序的)
# 这个函数是利用选择排序对文件进行排序
# 选择排序就是每轮都选择最小的那个放在第一个位置,然后循环
def sort_txt():
f = open('2.txt')
lines = f.readlines()
for i in range(len(lines)):
min_idx = i
for j in range(i + 1, len(lines)):
time_1 = lines[min_idx].split(',')[4]
time_2 = lines[j].split(',')[4]
t_1 = time_1.split(' ')[1].strip('\n')
t_2 = time_2.split(' ')[1].strip('\n')
if compare_big(t_1, t_2):
min_idx = j
lines[i], lines[min_idx] = lines[min_idx], lines[i]
for i in range(len(lines)):
with open("2_sort.txt", "a") as f:
# 这里注意一下:不能写成了"w",w每次都会覆盖前面写入的,a是每次都是追加
f.write(lines[i])
print("排序后的数组:")
for i in range(len(lines)):
print(lines[i])
# 这个函数是比较下面这样的数据结构的
# t1 = '21:18:46'
# t2 = '21:18:15'
# print(compare_big(t1, t2))
# 如果t1>t2,那么就输出True
def compare_big(t1, t2):
t1 = t1.split(':')
t2 = t2.split(':')
hour1 = int(t1[0])
hour2 = int(t2[0])
minute1 = int(t1[1])
minute2 = int(t2[1])
second1 = int(t1[2])
second2 = int(t2[2])
if hour1 > hour2:
return True
if hour1 == hour2:
if minute1 > minute2:
return True
if minute1 == minute2:
if second1 > second2:
return True
if second1 < second2:
return False
if minute1 < minute2:
return False
if hour1 < hour2:
return False
sort_txt()产生的文件样式如下:
2_sort.txt
1,30.654470,104.121588,0,2014/8/3 06:00:53
1,30.654470,104.121588,0,2014/8/3 06:01:53
1,30.654470,104.121588,0,2014/8/3 06:02:54
1,30.654470,104.121588,0,2014/8/3 06:03:54
1,30.654470,104.121588,0,2014/8/3 06:04:54
1,30.654470,104.121588,0,2014/8/3 06:05:55
1,30.654470,104.121588,0,2014/8/3 06:06:55
1,30.654470,104.121588,0,2014/8/3 06:07:55
1,30.654470,104.121588,0,2014/8/3 06:08:55
1,30.654470,104.121588,0,2014/8/3 06:09:56
1,30.654470,104.121588,0,2014/8/3 06:10:57
1,30.654470,104.121588,0,2014/8/3 06:11:57
1,30.654470,104.121588,0,2014/8/3 06:12:58二、数据简化
从数据样例中可以看出,车辆的经纬度数据是一分钟基本会有两个,这样的轨迹数据点太过于密集,数据量太大,使得后续的轨迹匹配难度加大。 轨迹数据可能在收集的时候会出现中断的情况,我们认为:前后数据时间相差30分钟的轨迹数据是不同的轨迹。意思就是这辆车如果他的这个轨迹点和下一个轨迹点的时间相差30分钟,那么这辆车的这两个轨迹点存在于这辆车的不同的轨迹路线中。现在进行轨迹数据简化。(注意:10分钟、30分钟都是可以自己设定的)
# Author:lei吼吼
# -*- coding=utf-8 -*-
# @Time :2023/1/7 15:37
# @File: 轨迹截断.py
# @Software:PyCharm
# 5分钟是一个点,但是30分钟就是另外一个轨迹了
from datetime import datetime
# 会生成两种文件,traj+num的是去除30分钟之外的数据的文件(并且已经分轨迹了)
# traj_simplify是简化的的轨迹文件(就是10分钟一个gpx点)
# 函数含义:判断是否为新的轨迹段(超过30分钟)
# 输入:2014/8/3 10:56:00类似的时间格式
def time_out(t1, t2):
time_1_struct = datetime.strptime(t1, "%Y/%m/%d %H:%M:%S")
time_2_struct = datetime.strptime(t2, "%Y/%m/%d %H:%M:%S")
seconds = (time_2_struct - time_1_struct).seconds
if seconds > 60 * 30:
return False
else:
return True
# 时间点太多了,进行时间点的筛选,10分钟为一个间隔
# 输入:文件的lines
def time_ten(lines):
i = 0
interval = []
traj_lines = [lines[0]]
while i + 31 < len(lines):
# 在这个点的后面30个点中选择下一个点
traj_line = traj_lines[-1]
for item in range(i + 1, i + 31):
interval.append(abs(time_interval(traj_line.split(',')[4].strip('\n'),
lines[item].split(',')[4].strip('\n')) - 10 * 60))
# print(interval)
# index这里+1是序号是从0开始的,为了得到下一个点的序号就需要+1
index = interval.index(min(interval)) + 1
# print(index)
interval.clear()
i = i + index
traj_lines.append(lines[i])
# print(traj_lines)
return traj_lines
# 计算两个时间点之间的时间差
# 输入两个时间,时间样式:2014/8/3 10:56:00
def time_interval(t1, t2):
time_1_struct = datetime.strptime(t1, "%Y/%m/%d %H:%M:%S")
time_2_struct = datetime.strptime(t2, "%Y/%m/%d %H:%M:%S")
seconds = (time_2_struct - time_1_struct).seconds
return seconds
def main():
f = open('2_sort.txt')
lines = f.readlines()
# 进行是否是新轨迹的判断
num = 1
traj_lines = [] # 这个是存放每次在同一个轨迹的的lines
# 解释一下这个for循环
# 如果不超过30分钟就是一个轨迹的,所以放入记录同一个轨迹的列表(traj_lines)中,直到找到另一个轨迹
# 创建文件,将上一个轨迹的所有点写入,然后将轨迹列表traj_lines清除,写入本轨迹的第一个点,然后进入循环找本轨迹的其他点
for item in range(len(lines)):
t1 = lines[item].split(',')[4].strip('\n')
t2 = lines[item].split(',')[4].strip('\n')
if time_out(t1, t2):
traj_lines.append(lines[item])
else:
file_name = 'traj' + str(num) + '.txt'
for i in range(len(traj_lines)):
with open(file_name, "a") as f:
# 这里注意一下:不能写成了"w",w每次都会覆盖前面写入的,a是每次都是追加
f.write(traj_lines[i])
num = num + 1
traj_lines.clear()
traj_lines.append(lines[item])
# 这里使用了traj_lines.clear()注意会不会出错
# 写num==1这个if的原因是:如果只有一条轨迹那么就不会写入文件,所以要把这种情况单独列出来
if num == 1:
file_name = 'traj' + str(num) + '.txt'
for i in range(len(traj_lines)):
with open(file_name, "a") as f:
# 这里注意一下:不能写成了"w",w每次都会覆盖前面写入的,a是每次都是追加
f.write(traj_lines[i])
# 进行轨迹简化
for j in range(1, num + 1):
file_name = 'traj' + str(j) + '.txt'
file = open(file_name)
tr_lines = file.readlines()
sim_lines = time_ten(tr_lines)
file_name = 'traj_simplify' + str(j) + '.txt'
for s in range(len(sim_lines)):
with open(file_name, "a", encoding='utf-8') as f:
# 这里注意一下:不能写成了"w",w每次都会覆盖前面写入的,a是每次都是追加
f.write(sim_lines[s])
if __name__ == '__main__':
main()这个代码会产生两种文件,如下:
traj1.txt
1,30.654470,104.121588,0,2014/8/3 06:00:53
1,30.654470,104.121588,0,2014/8/3 06:01:53
1,30.654470,104.121588,0,2014/8/3 06:02:54
1,30.654470,104.121588,0,2014/8/3 06:03:54
1,30.654470,104.121588,0,2014/8/3 06:04:54
1,30.654470,104.121588,0,2014/8/3 06:05:55
1,30.654470,104.121588,0,2014/8/3 06:06:55
1,30.654470,104.121588,0,2014/8/3 06:07:55
1,30.654470,104.121588,0,2014/8/3 06:08:55
1,30.654470,104.121588,0,2014/8/3 06:09:56
1,30.654470,104.121588,0,2014/8/3 06:10:57
1,30.654470,104.121588,0,2014/8/3 06:11:57
1,30.654470,104.121588,0,2014/8/3 06:12:58traj_simplify1.txt
1,30.654470,104.121588,0,2014/8/3 06:00:53
1,30.654470,104.121588,0,2014/8/3 06:10:57
1,30.654470,104.121588,0,2014/8/3 06:21:00
1,30.654470,104.121588,0,2014/8/3 06:31:02
1,30.654470,104.121588,0,2014/8/3 06:41:06
1,30.654470,104.121588,0,2014/8/3 06:51:09
1,30.654470,104.121588,0,2014/8/3 07:00:13
1,30.654673,104.121396,0,2014/8/3 07:10:17
1,30.654682,104.121483,0,2014/8/3 07:20:30
1,30.654632,104.121445,0,2014/8/3 07:30:43
1,30.654605,104.121440,0,2014/8/3 07:40:56
1,30.654580,104.121703,0,2014/8/3 07:51:10三、txt文件转化成gpx文件
因为我们会使用轨迹地图匹配框架:graphhoper.map-matching来进行轨迹地图匹配,但是graphhoper.map-matching的输入是gpx文件,我们现在文件是txt文件,所以我们将txt文件转化成gpx文件
# Author:lei吼吼
# -*- coding=utf-8 -*-
# @Time :2023/1/4 19:34
# @File: txt2gpx.py
# @Software:PyCharm
# 这个是将成都的数据集的txt文件转成gpx文件
def csv2gpx(outfilepath):
f = open('traj_simplify1.txt')
lines = f.readlines()
car_id = []
time = []
lat = [] # 纬度
lon = [] # 经度
for item in lines:
line = item.split(',')
car_id.append(line[0])
t = line[4].split(' ')
t_0 = t[0].split('/')
t = t_0[0]+'-0'+t_0[1]+'-0'+t_0[2] + 'T' + t[1].strip('\n') + '+00:00'
time.append(t)
lon.append(line[2]) # 经度
lat.append(line[1].strip('\n')) # 纬度
outstring = '<?xml version="1.0" encoding="UTF-8" standalone="yes"?>\n'
outstring += '<gpx xmlns="http://www.topografix.com/GPX/1/1" ' \
'xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" ' \
'xsi:schemaLocation="http://www.topografix.com/GPX/1/1 http://www.topografix.com/GPX/1/1/gpx.xsd">'
outstring += '<trk>\n<trkseg>\n'
for i in range(len(lines)):
item = '<trkpt lat="' + str(lat[i]) + '" lon="' + str(lon[i]) + '"><time>' + str(time[i]) + '</time></trkpt>'
outstring = outstring + item + "\n"
outstring += '</trkseg>\n</trk>\n</gpx>'
fw = open(outfilepath, 'w')
fw.write(outstring)
fw.close()
# ------------------------------------------Test----------------------------------
def forfolders():
csv2gpx('traj_sim_gpx.gpx')
forfolders()转化后的文件:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<gpx xmlns="http://www.topografix.com/GPX/1/1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.topografix.com/GPX/1/1 http://www.topografix.com/GPX/1/1/gpx.xsd"><trk>
<trkseg>
<trkpt lat="30.654470" lon="104.121588"><time>2014-08-03T06:00:53+00:00</time></trkpt>
<trkpt lat="30.654470" lon="104.121588"><time>2014-08-03T06:10:57+00:00</time></trkpt>
<trkpt lat="30.654470" lon="104.121588"><time>2014-08-03T06:21:00+00:00</time></trkpt>
<trkpt lat="30.654470" lon="104.121588"><time>2014-08-03T06:31:02+00:00</time></trkpt>
<trkpt lat="30.654470" lon="104.121588"><time>2014-08-03T06:41:06+00:00</time></trkpt>
<trkpt lat="30.654470" lon="104.121588"><time>2014-08-03T06:51:09+00:00</time></trkpt>
<trkpt lat="30.654470" lon="104.121588"><time>2014-08-03T07:00:13+00:00</time></trkpt>
<trkpt lat="30.654673" lon="104.121396"><time>2014-08-03T07:10:17+00:00</time></trkpt>
<trkpt lat="30.654682" lon="104.121483"><time>2014-08-03T07:20:30+00:00</time></trkpt>
<trkpt lat="30.654632" lon="104.121445"><time>2014-08-03T07:30:43+00:00</time></trkpt>
<trkpt lat="30.654605" lon="104.121440"><time>2014-08-03T07:40:56+00:00</time></trkpt>
<trkpt lat="30.654580" lon="104.121703"><time>2014-08-03T07:51:10+00:00</time></trkpt>
<trkpt lat="30.654332" lon="104.122103"><time>2014-08-03T08:01:23+00:00</time></trkpt>
</trkseg>
</trk>四、进行轨迹匹配
使用graphhopper(map-matching)进行地图匹配_lei吼吼的博客-优快云博客
匹配之后的文件
<?xml version="1.0" encoding="UTF-8" standalone="no" ?><gpx xmlns="http://www.topografix.com/GPX/1/1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" creator="Graphhopper version 1f5419977ed205d48d5507b65fae231592e52c5b" version="1.1" xmlns:gh="https://graphhopper.com/public/schema/gpx/1.1">
<metadata><copyright author="OpenStreetMap contributors"/><link href="http://graphhopper.com"><text>GraphHopper GPX</text></link><time>2014-08-03T06:00:53Z</time></metadata>
<trk><name></name><trkseg>
<trkpt lat="30.653076" lon="104.121415"><time>2014-08-03T06:00:53Z</time></trkpt>
<trkpt lat="30.652163" lon="104.122879"></trkpt>
<trkpt lat="30.651934" lon="104.123171"></trkpt>
<trkpt lat="30.651732" lon="104.123339"><time>2014-08-03T06:01:07Z</time></trkpt>
<trkpt lat="30.65445" lon="104.123867"><time>2014-08-03T06:01:29Z</time></trkpt>
<trkpt lat="30.651732" lon="104.123339"><time>2014-08-03T06:01:51Z</time></trkpt>
<trkpt lat="30.651418" lon="104.123557"></trkpt>
<trkpt lat="30.650851" lon="104.124216"></trkpt>
<trkpt lat="30.650517" lon="104.124884"></trkpt>
<trkpt lat="30.650316" lon="104.125551"></trkpt>
<trkpt lat="30.650209" lon="104.12604"><time>2014-08-03T06:02:10Z</time></trkpt>
<trkpt lat="30.650316" lon="104.125551"></trkpt>
</trkseg>
</trk>
</gpx>五、将匹配之后的估计经纬度点与地图道路ID匹配
因为项目需要的数据格式是需要轨迹点转成道路点的,项目需要的数据样式
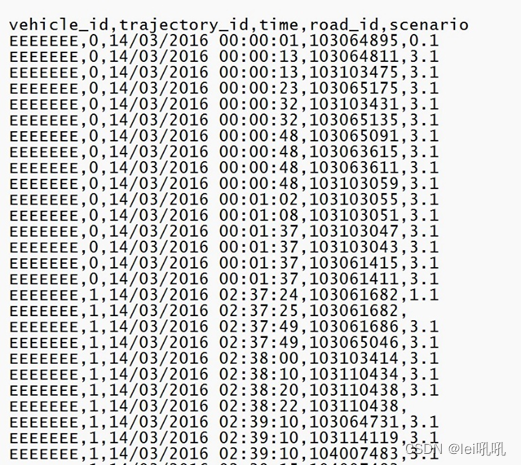
所以进行这一步(下面的代码中使用了高德地图的API,具体方法请参见通过 经纬度 获取 地理位置(Python、高德地图)_Oriental_1024的博客-优快云博客_根据经纬度坐标获取地理信息python)
# Author:lei吼吼
# -*- coding=utf-8 -*-
# @Time :2023/1/8 15:45
# @File: gps转换.py
# @Software:PyCharm
# 这个文件是将gpx文件中的经纬度和道路id匹配,并生成最终结果文件
import requests
import gpxpy
import pandas as pd
# 调用高德地图API,获取道路ID
def geocode(location):
# 参数内容 可以写成字典的格式
parameters = {'output': 'json', 'key': '你自己的高德的key', 'location': location,
'extensions': 'all'}
# 问号以前的内容
base = 'http://restapi.amap.com/v3/geocode/regeo'
response = requests.get(base, parameters)
print('HTTP 请求的状态: %s' % response.status_code)
return response.json()
if __name__ == '__main__':
# 主函数:获取道路ID 并生成最终结果文件
id_line = []
with open('traj_sim_gpx.gpx.res.gpx') as fh:
gpx_file = gpxpy.parse(fh)
segment = gpx_file.tracks[0].segments[0]
# print(segment)
coords = pd.DataFrame([{'lat': p.latitude,
'lon': p.longitude,
'time': p.time} for p in segment.points])
# 下次要转换新的数据的时候就需要把这部分的代码激活
# print(coords)
# for i in range(len(coords)):
# loc = str(coords['lon'][i]) + ',' + str(coords['lat'][i])
# data = geocode(loc) # 获取的数据类型为dict
# formatted_address = data['regeocode']['roads']
# id_line.append(formatted_address[0]['id'])
# print(id_line)
# 因为每天的次数有限,所以只能把ID打印出来
id_line=['028H48F017017604156', '028H48F017017604140', '028H48F017017604140', '028H48F01701724217', '028H48F01701724217', '028H48F01701724217', '028H48F01701724217', '028H48F0170173773', '028H48F0170173773', '028H48F01701723284', '028H48F017017683271', '028H48F01701723284', '028H48F0170173773', '028H48F0170173773', '028H48F01701724217', '028H48F01701724217', '028H48F01701724217', '028H48F0170175400', '028H48F01701722789', '028H48F01701722789', '028H48F01701722789', '028H48F01701722789', '028H48F01701722789', '028H48F01701722789', '028H48F017017659205', '028H48F017017659205', '028H48F016017659713', '028H48F016017659713', '028H48F016017605665', '028H48F016017605655', '028H48F01601720164', '028H48F01601720164', '028H48F0160173202', '028H48F0160173202', '028H48F0160173202', '028H48F0160173202', '028H48F0160173202', '028H48F0160173202', '028H48F0160173202', '028H48F0160173202', '028H48F01601727622', '028H48F01601727622', '028H48F016017603368', '028H48F016017603372', '028H48F016017603372', '028H48F016017632442', '028H48F016017604663', '028H48F0160173570', '028H48F0160173570', '028H48F0160173570', '028H48F01601740938', '028H48F016017725117', '028H48F016017725117', '028H48F016017725117', '028H48F01601740938', '028H48F0160173193', '028H48F01601740938', '028H48F0160173570', '028H48F0160173570', '028H48F0160173570', '028H48F016017604663', '028H48F016017632442', '028H48F016017632442', '028H48F0160173818', '028H48F01601724728', '028H48F016017691288', '028H48F016017691288', '028H48F016017691288', '028H48F016017691288', '028H48F016017691288', '028H48F016017691288', '028H48F0160172992', '028H48F016017705045', '028H48F01601718188', '028H48F01601718188', '028H48F01601718188', '028H48F01601718188', '028H48F016017705045', '028H48F016017705045', '028H48F016017691288', '028H48F0160173570', '028H48F016017630970', '028H48F017017659850', '028H48F0170174018', '028H48F0170173149', '028H48F017017603944', '028H48F017017603944', '028H48F017017603944', '028H48F017017749262', '028H48F017017749262', '028H48F0170174018', '028H48F0170174018', '028H48F017017659850', '028H48F0160174170', '028H48F0160174170', '028H48F016017630970', '028H48F0170175388', '028H48F0170175388', '028H48F01601724231', '028H48F0160173570', '028H48F0160173570', '028H48F016017604663', '028H48F016017632442', '028H48F016017603372', '028H48F016017632442', '028H48F0160173818', '028H48F01601724728', '028H48F016017691288', '028H48F016017691288', '028H48F016017691288', '028H48F016017691288', '028H48F016017691288', '028H48F016017691288', '028H48F0160172992', '028H48F016017705045', '028H48F01601718188', '028H48F01601718188', '028H48F01601718188', '028H48F01601718188', '028H48F016017705045', '028H48F016017705045', '028H48F016017691288', '028H48F0160173570', '028H48F016017630970', '028H48F017017659850', '028H48F0170174018', '028H48F0170173149', '028H48F017017603944', '028H48F017017603944', '028H48F017017603944', '028H48F017017749262', '028H48F017017749262', '028H48F0170174018', '028H48F0170174018', '028H48F017017659850', '028H48F0160174170', '028H48F0160174170', '028H48F0160174170', '028H48F0170175388', '028H48F0170175388', '028H48F0170175388', '028H48F0160174170', '028H48F0160174170', '028H48F016017630970', '028H48F0170175388', '028H48F0170175388', '028H48F01601724231', '028H48F0160173570', '028H48F0160173570', '028H48F016017604663', '028H48F016017632442', '028H48F016017632442', '028H48F0160173818', '028H48F01601724728', '028H48F016017691288', '028H48F016017691288', '028H48F016017691288', '028H48F016017691288', '028H48F016017691288', '028H48F016017691288', '028H48F0160172992', '028H48F016017705045', '028H48F01601718188', '028H48F01601718188', '028H48F01601718188', '028H48F01601718188', '028H48F016017705045', '028H48F016017705045', '028H48F016017691288', '028H48F0160173570', '028H48F016017630970', '028H48F017017659850', '028H48F0170174018', '028H48F017017603951', '028H48F0170174062', '028H48F017017639450', '028H48F0170173951', '028H48F017017639450', '028H48F017017639450', '028H48F017017643823', '028H48F017017643823', '028H48F0170178609', '028H48F0170178609', '028H48F017017636405', '028H48F017017636405', '028H48F0170174734', '028H48F0170174734', '028H48F017017603975', '028H48F017017603975', '028H48F017017603975', '028H48F017017613960', '028H48F017017613960', '028H48F01701724221', '028H48F017017604156', '028H48F017017604140', '028H48F017017604140', '028H48F01701724217', '028H48F01701724217', '028H48F01701724217', '028H48F01701724217', '028H48F01701724217', '028H48F01701724217', '028H48F0170173773', '028H48F0170173773', '028H48F01701723284', '028H48F017017683271', '028H48F017018604509', '028H48F017018604509', '028H48F017018622514', '028H48F017018630208', '028H48F017018630208', '028H48F0170181447', '028H48F017018615240', '028H48F017018144674', '028H48F017018144674', '028H48F0170187258', '028H48F017018601859', '028H48F017018144668', '028H48F0170187298', '028H48F017018144668', '028H48F017018601859', '028H48F0170187258', '028H48F017018144674', '028H48F017018144674', '028H48F017018604561', '028H48F017018604561', '028H48F0170186955', '028H48F0170189475', '028H48F017018361', '028H48F0170189475', '028H48F0170186971', '028H48F0170189475', '028H48F0170186971', '028H48F0170189475', '028H48F017018144992', '028H48F017018601309', '028H48F0170189475', '028H48F017018612203', '028H48F017018612203', '028H48F017018612203', '028H48F0170187523', '028H48F017018612203', '028H48F017018612203', '028H48F017018612203', '028H48F0170181447', '028H48F017018612972', '028H48F017018612968', '028H48F0170184796', '028H48F017018615263', '028H48F017018686', '028H48F017018686', '028H48F0170184282', '028H48F0170184181', '028H48F01701811127', '028H48F017018630208', '028H48F0170181447', '028H48F017018615240', '028H48F017018144674', '028H48F017018604561', '028H48F0170187057', '028H48F017018604561', '028H48F017018604561', '028H48F017018604561', '028H48F017018144674', '028H48F017018144674', '028H48F017018615240', '028H48F0170181447', '028H48F017018630208', '028H48F017018630208', '028H48F017018622514', '028H48F017018604509', '028H48F017018604509', '028H48F017017683271', '028H48F01701723284', '028H48F0170173773', '028H48F0170173773', '028H48F01701724217', '028H48F01701724217', '028H48F017017604140', '028H48F017017604140', '028H48F017017604156', '028H48F01701724221', '028H48F017017613960', '028H48F017017613960', '028H48F017017749278', '028H48F017017603975', '028H48F017017603975', '028H48F017017603975', '028H48F017017603975', '028H48F017017603975', '028H48F017017603975', '028H48F017017603975', '028H48F017017603975', '028H48F017017603975', '028H48F0170173149', '028H48F017017749262', '028H48F017017749262', '028H48F0170174018', '028H48F0170174018', '028H48F017017659850', '028H48F0160174170', '028H48F0160174170', '028H48F016017630970', '028H48F0170175388', '028H48F0170175388', '028H48F01601724231', '028H48F0160173570', '028H48F0160173570', '028H48F016017604663', '028H48F016017632442', '028H48F016017632442', '028H48F0160173818', '028H48F01601724728', '028H48F016017691288', '028H48F016017691288', '028H48F016017691288', '028H48F016017691288', '028H48F016017691288', '028H48F016017691288', '028H48F0160172992', '028H48F016017705045', '028H48F01601718188', '028H48F01601718188', '028H48F0160172992', '028H48F0160172992', '028H48F0160172992', '028H48F0160172992', '028H48F01601724728', '028H48F01601724728', '028H48F0160172992', '028H48F0160172992', '028H48F01601744821', '028H48F0160174864', '028H48F0160174864', '028H48F01601723244', '028H48F01601723244', '028H48F0160172995', '028H48F01601713787', '028H48F01601713787', '028H48F01601720302', '028H48F016017646111', '028H48F016017260', '028H48F016017260', '028H48F016017260', '028H48F01601741240', '028H48F0160171665', '028H48F0160171665', '028H48F016017624172', '028H48F0160171665', '028H48F0160171665', '028H48F0160171665', '028H48F016017574', '028H48F016017983', '028H48F016017983', '028H48F01601743578', '028H48F01601743578', '028H48F01601743578', '028H48F016017590', '028H48F016017590', '028H48F01601722496', '028H48F01601722496', '028H48F01601743416']
# file_line = []
file_lines = []
for i in range(len(coords)):
file_line = '1'+','+'1'+','+str(coords['time'][i]).strip('+00:00')+','+str(id_line[i])
# file_line 前面两个要根据具体的变化的
# time中带有gpx文件time的样子,现在要变回来
file_lines.append(file_line)
# print(file_lines)
with open('sample.txt','a') as f:
f.write('vehicle_id,trajectory_id,time,road_id')
# 车辆ID 轨迹ID 时间戳 道路ID
f.write('\n')
for i in range(len(file_lines)):
with open('sample.txt','a') as f:
f.write(file_lines[i])
f.write('\n')结果展示:
vehicle_id,trajectory_id,time,road_id
1,1,2014-08-03 06:00:53,028H48F017017604156
1,1,NaT,028H48F017017604140
1,1,NaT,028H48F017017604140
1,1,2014-08-03 06:01:07,028H48F01701724217
1,1,2014-08-03 06:01:29,028H48F01701724217
1,1,2014-08-03 06:01:51,028H48F01701724217
1,1,NaT,028H48F01701724217
1,1,NaT,028H48F0170173773
1,1,NaT,028H48F0170173773
1,1,NaT,028H48F01701723284
1,1,2014-08-03 06:02:1,028H48F017017683271
1,1,NaT,028H48F01701723284
1,1,NaT,028H48F0170173773
1,1,NaT,028H48F0170173773
1,1,NaT,028H48F01701724217
1,1,2014-08-03 06:02:29,028H48F01701724217
















 748
748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









