




基于深度学习的图像去雾综合调查与分类
摘要
随着卷积神经网络的发展,已经提出了数百种基于深度学习的去雾方法。在本文中,我们对有监督、半监督和无监督去雾进行了全面调查。我们首先讨论常用的物理模型、数据集、网络模块、损失函数和评估指标。然后,对各种去雾算法的主要贡献进行了分类和总结。此外,还进行了各种基线方法的定量和定性实验。最后,指出了可以启发未来研究的未解决问题和挑战。 https://github.com/Xiaofeng-life/AwesomeDehazing 提供了一系列有用的除雾材料。
1 引言 由于环境中含有的漂浮颗粒的吸收,相机拍摄的图像质量会有所下降。在雾霾天气下,图像质量下降的现象对摄影工作产生了负面影响。图像的对比度会降低,颜色会发生变化。同时,场景中物体的纹理和边缘会变得模糊不清。如图1所示,雾霾和无雾霾图像的像素直方图之间存在明显的差异。对于视觉任务,如物体检测和图像分割,低质量的输入会降低精心设计的模型的性能。
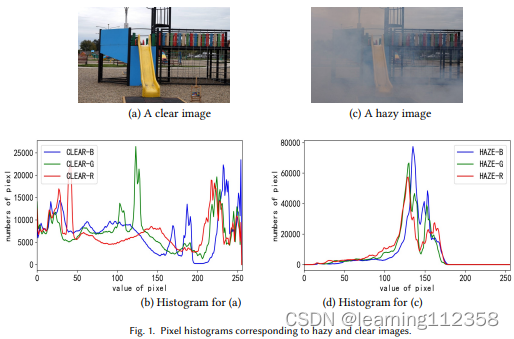
因此,许多研究人员试图从朦胧的图像中恢复高质量的清晰场景。在深度学习被广泛用于计算机视觉任务之前,图像脱色算法主要依赖于各种先验假设[50]和大气散射模型(ASM)[89]。这些基于统计规则的方法的处理流程具有良好的可解释性。然而,在面对复杂的现实世界场景时,它们可能表现出缺点。例如,著名的暗通道先验[50](DCP,2009年CVPR最佳论文)不能很好地处理含有天空的区域。
受深度学习的启发,[12, 106, 108]将ASM和卷积神经网络(CNN)结合起来估计物理参数。定量和定性的实验结果表明,深度学习可以帮助以监督的方式预测物理参数。在此之后,[80、86、104、176、184] 已经证明端到端的监督去雾网络可以独立于 ASM 来实现。由于 CNN 强大的特征提取能力,这些非基于 ASM 的去雾算法可以达到与基于 ASM 的算法相似的精度。
基于ASM和非ASM的监督算法已经显示出令人印象深刻的性能。然而,它们往往需要合成的配对图像,而这些图像与真实世界的朦胧图像不一致。因此,最近的研究集中在更适合于现实世界的除霾任务的方法上。[23, 43, 67]探讨了不需要合成数据的无监督算法,而其他研究[1, 20, 74, 166]提出了半监督算法,利用合成配对数据和现实世界的非配对数据。
在研究人员的努力下,已经提出了数百种去雾方法。为了启发和指导未来的研究,迫切需要进行全面的调查。一些论文试图部分回顾去雾研究的最新进展。例如,[79,124,146] 总结了非深度学习去雾方法,包括深度估计、小波、增强、滤波,但缺乏对最近基于 CNN 的方法的研究。帕里哈尔等人。 [101] 提供了关于有监督去雾模型的调查,但它没有对半监督和无监督方法的最新探索给予足够的关注。班纳吉等人。 [10]对现有的夜间图像去雾方法进行了介绍和分组,但很少对白天的方法进行分析。桂等人。 [44]对有监督和无监督算法进行了分类和分析,但没有总结最近提出的各种半监督方法。与现有评论不同,我们对基于深度学习的监督、半监督和无监督日间去雾模型进行了全面调查。
在本次审查的算法分析部分,有两个因素需要考虑。首先,我们如何训练所需的模型?基于此,算法分为监督、半监督和无监督三种类型。其次,预期模型展示了哪些技术有利于去雾任务,从而激发未来的工作以建立在它们之上。基于此,监督、半监督和无监督方法分别分为 18、3、4 类。现有的去雾算法如表 1 所示,根据其主要贡献进行分类。为了证明现有去雾算法已经取得的结果,第 6 节对监督、半监督和无监督算法的性能进行了定量和定性研究。
1.1 本次调查的范围和目标本次调查并未涵盖去雾研究的所有主题。我们将注意力集中在使用单眼白天图像的基于深度学习的算法上。这意味着我们不会详细讨论非深度学习去雾、水下去雾[71、135、136]、视频去雾[109]、高光谱去雾[91]、夜间去雾[161-163]、双目去雾[99] ]等。因此,当我们在本文中提到“去雾”时,我们通常指的是基于深度学习的算法,其输入数据满足四个条件:单帧图像、白天、单目、地面。由于不同的去雾方法在不同的条件和目的下,本次调查没有对各种算法的实验结果进行比较。总之,本次调查有以下三个贡献。
• 总结了常用的物理模型、数据集、网络模块、损失函数和评估指标。
• 介绍了监督、半监督和无监督方法的分类和介绍。
• 根据已有的成果和未解决的问题,对未来的研究方向进行了展望。
1.2 阅读本调查指南第 2 部分介绍了物理模型 ASM、合成和生成的真实数据集、损失函数、去雾网络中常用的基本模块以及各种算法的评估指标。第 3 节全面讨论了有监督的去雾算法。第 4 节和第 5 节分别对半监督和无监督去雾方法进行了回顾。第 6 节介绍了三类基线算法的定量和定性实验结果。第 7 节讨论了去雾研究的未解决问题。
对去雾研究进行逻辑和全面审查的一个重要挑战是如何正确分类现有方法。在表1的分类中,有几点需要指出如下。
• DCP 在去雾任务上得到验证,推理过程使用 ASM。因此,使用 DCP 的方法被认为是基于 ASM 的。
• 本调查将基于知识蒸馏的监督去雾网络视为监督算法,而不是弱监督/半监督算法。
• 使用总变异损失或GAN 损失的监督去雾方法仍被归类为监督。
在这里,我们给出了本次调查的符号约定。除非另有说明,所有符号的含义如下: 𝐼(𝑥) 表示朦胧的图像; 𝐽 (𝑥) 表示无雾图像。 𝑡(𝑥)代表传输图; 𝐼(𝑥)、𝐽(𝑥)和𝑡(𝑥)中的𝑥是像素位置。下标“𝑟𝑒𝑐”表示重建后的图像,如𝐼𝑟𝑒𝑐(𝑥)就是重建后的朦胧图像。下标“𝑝𝑟𝑒𝑑”指的是预测输出。根据[41],大气光可以被视为一个常数A或一个非均匀矩阵𝐴(𝑥
A Comprehensive Survey and Taxonomy on Image Dehazing Based on Deep Learning(学习笔记,不喜勿喷)
最新推荐文章于 2024-12-20 16:19:24 发布
 本文全面回顾了基于深度学习的图像去雾方法,涵盖了有监督、半监督和无监督策略。文章讨论了物理模型、数据集、网络模块、损失函数和评估指标,并对各种算法进行了分类和实验分析。尽管取得显著进展,但现实世界数据的不一致性和合成数据的局限性仍然是挑战。未来的研究方向包括更适应现实场景的去雾技术和新的损失函数设计。
本文全面回顾了基于深度学习的图像去雾方法,涵盖了有监督、半监督和无监督策略。文章讨论了物理模型、数据集、网络模块、损失函数和评估指标,并对各种算法进行了分类和实验分析。尽管取得显著进展,但现实世界数据的不一致性和合成数据的局限性仍然是挑战。未来的研究方向包括更适应现实场景的去雾技术和新的损失函数设计。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2589
2589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









