










如今到处都在讨论打造新质生产力,推动产业的数转智改。以大模型为典型的AI智能无疑是根正苗红的新质生产力。百模大战之外,各行各业也都在探索大模型落地的场景,推动了大模型应用工程的快速发展。
一、蓬勃发展的Python生态
由于Python在AI计算领域覆盖了从Pandas、NumPy、SciPy、Matplotlib等底层工具库,到深度学习框架PyTorch、TensorFlow等,以及如HuggingFace Transformers面向特定领域的开发框架。不论是国外的Huggingface社区还是国内的魔搭社区的各类预训练模型,基本都是基于Python深度学习框架。由此,近一年多来,大部分大模型应用工程都是基于python生态。
其中,通用框架级别的开源项目有如下:
-
Dify:开源的大模型开发平台,提供直观的界面结合AI工作流、RAG管道、Agent、模型管理、可观测性功能等,并且支持多种模型包括但不限于GPT、Mistral、Llama3等。
-
LangChain:另一个相当知名的大模型开发框架,LangChain集成了多种大语言模型及第三方API,它通过统一的接口调用不同的模型,实现了不同模型的统一接口调用。
-
Gradio:一个轻量级的开发库,可让快速为机器学习模型构建演示或 Web 应用程序。
-
DB-GPT:由蚂蚁集团开源的项目,支持构建企业级智能知识库、自动生成商业智能(BI)报告分析系统(GBI),以及处理日常数据和报表生成等多元化应用场景。
也有针对特定领域的专项应用开源,著名的如下:
-
AutoGen:由微软开源,支持多个 LLM 智能体通过扮演各种角色,如程序员、设计师,或者是各种角色的组合,通过对话就来解决任务。
-
GraphRAG:微软近期另一个开源项目,大语言模型与知识图谱结合,提升推理能力。
-
LlamaIndex:专为RAG的大型语言模型应用设计。支持将私有或特定领域的数据结构化,并安全、可靠地集成到语言模型中,以提高文本生成的准确性。
然而以上各类开源项目不尽成熟,版本还在快速迭代中;过去一年的试用体验实在不尽如人意。
《GPT图解:大模型是怎样构建的》作者黄佳指出“LangChain 封装了比如说React这些框架,也是让初学者能够迅速的就开发出来一个还能够做DEMO的agent,但不是说真正能够用在生产的这个级别。”
二、相对薄弱的Java AI生态
Java在AI领域目前不论在工具库,还是在开发框架都比较薄弱,这里简单列举如下。
比较著名的通用深度学习开发框架。例如:
-
Deeplearning4j,深度学习开发框架;
-
DJL:由AWS开源的深度学习库;
此外还有一些NLP的开发库
-
Apache OpenNLP:Apache处理自然语言文本的工具包。
-
Stanford CoreNLP:斯坦福开源的 NLP任务框架,GPL授权。
-
Hanlp(1.x):国人开源的自然语言包,中文支持好(备注,2.x版本改为python版本)
大模型开发框架,正在奋起追赶:
-
langchain4j:与langChain的作者不同,也不属于同一个开源家族,但较晚出现的langChain4j吸收了LangChain的设计精神;
-
Spring-AI:同样吸收了langchain的设计理念(github上代码结构同langchain以及langchain4j可见的相似);与langchain4j不同的是,充分利用了spring框架的能力。
两个项目都在非常早期阶段(虽然spring-ai号称1.0-m1版本,但功能和langchain4j还有不少差距),功能还在迭代中。
三、大模型应用离不开Java生态
“用户在真正的工作中使用场景里面它的任务是一个复杂的任务,不是一个简单的单一任务,当用户以一个指令的方式,以一两句话,或者几句话去让他做这件事情的时候,大模型没有办法把这件事情一步一步猜出来。”
目前大模型应用由分为C端和B端两类产品
-
C端相对是独立工具形态或者工具+AI能力,比如AI翻译、网页总结插件,需要用户自身整合各类工具以加速完成目标场景。在生产力工具层面,例如:剪辑工具、图片工具、内容生成工具纷纷集成AI能力;
-
B端产品,除了产品本身需要功能强大,形态上需要嵌入客户的工作场景中,满足一体化体验;这导致了整个交付过程还包含私有化定制/客户培训/私有化部署/软硬件适配等等繁杂的工作。
Python虽然在AI计算生态有统治地位,但在企业应用开发生态上明显单薄,仅有Django等不多的用于构建Web服务的开发框架;也缺少各类中间件等基础设施;同时,Python语言的GIL也限制了多线程应用(虽然最新版本已经可以去除GIL,但大量的库需要调整,这将会是长期过程)。
Java 虽然在AI计算生态上比较薄弱,但Java拥有比python更庞大的企业级应用的开发者社区、丰富开源框架和库,如Spring、Mybatis,以及各类企业级应用中间件,这些都是构建复杂系统尤其在企业级开发领域的关键组件。
从B端大模型应用的交付场景考虑,以实际需求场景出发,结合python和Java两大社区各自生态优势,设计了基于java的大模型应用参考架构如下:
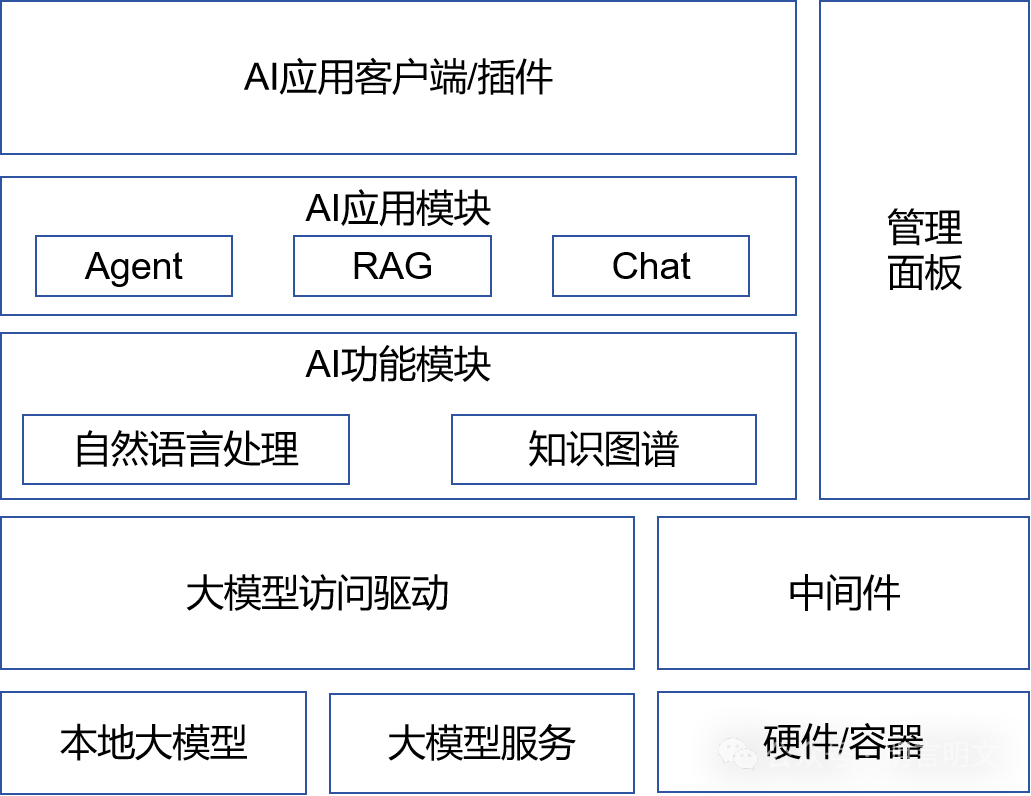
以上各层次各模块技术栈选型分别为:
-
顶层的AI应用客户端/插件:TS/Java/.NET等
-
中间三层(AI应用模块、AI功能模块、管理面板以及中间件):Java为主,包括API接口,任务调度、数据处理等等
-
底层的本地模型或大模型服务:python,提供无状态API接口;
这里面不同团队有不同选择,有些团队会基于python实现AI功能模块(NLP和KG)。
四、Java的大模型访问驱动
如前文所述,大部分的模型都是由python的深度学习框架所训练。由于Java体系的深度学习框架缺乏完整的算子,无法直接加载python输出的模型。在Java体系下访问大模型的方式有:远程API方式和进程JNI方式。
远程API方式,包括两种:
-
调用云服务:基于openAI的rest接口直接调用
-
调用本地服务:基于python生态(HFT、vllm)或Ollama等在本地环境启动大模型服务,并开放openAI的接口;
进程JNI方式,包括4种方式:
-
基于JNI + llama.cpp, 这是一个CPU 优先的 C++ 库;该库解决推理过程中的性能问题;支持GGUF 格式(huggingface社区目前优先推荐的模型格式)。下图展示了llama.cpp与其他开源项目的核心关系。

-
基于JNI + llama2.c(以及Llama3.c),llama2.c是由karpathy编写的纯C的运行底座;llama3.c则是另有其人;
-
基于AWS的DJL,支持通过jni运行pytorch以及tf模型;
-
微软的ONNX(Open Neural Network Exchange),deeplearning4j就是基于ONNX导入各预训练模型;
五、开箱可用的中间件体系
Java生态拥有最丰富的中间件及其支撑体系,特别是如下:
-
面向微服务、分布式等基础设施,充分满足横向扩展的技术需求;
-
极其丰富的各类(结构化、半结构化和非结构化)数据存储、处理以及检索工具;
-
从本地存储到对象存储;
-
apache tika提供各类文档处理工具
-
从Kettle到Spark/Flink;
-
甚至于embedding检索;
-
各类开发框架和工具类
-
各种日志工具
-
apache common工具类
各类工具应有尽有,极大避免了从0开始造轮子,落地过程中做好选型和适配即可。
六、自主构建功能模块和应用模块
不同于前两部分,虽然此处自主造轮的理由显而易见,但下定决心却不容易。
不用langchain4j和spring-ai这两个框架的原因很简单:
-
版本并不成熟,即便是spring家族也存在不少烂尾的项目;
-
过度封装,两个框架为了兼容不同模型、不同云服务商以及不同中间件,试图建立统一抽象层,导致整个架构极其复杂;
-
功能缺失,例如缺乏提示词管理支持;
-
大模型本身以及应用生态日新月异;例如:最新的llama 3.1提供了更强大能力;微软新开源了GraphRAG,这些都使得框架与抽象更新成本太高;
-
落地业务需求变化太大了,有时候需要结合实际业务情况来进行处理的,此时直接访问模型原生API更为经济;
《LangChain入门指南》一书的作者李特丽总结道:
a. 过度抽象:某些接口的抽象程度过高,新手难以理解源码;
b. 学习曲线陡峭:复杂的嵌套结构可能让初学者感到困惑。
c. 性能开销:在Agent场景下,调用LLM API的次数很多。
d. 很多提示词工程,没有对中文支持。
自主构建有一定成本,但有如下优势:
-
简化适配复杂度:统一用OpenAI的SDK来适配云服务;同时精选中间件服务;
-
NLP以及KG等功能,甚至应用模块可指定底层模型并直接调用底层模型能力。毕竟现在大模型还在快速发展:从BERT、GPT到Llama架构也就短短几年;MegaLodon、xLSTM、Infini-Attention等无限token技术也在快速发展;垂直大模型也在不断涌现;
-
快速借鉴python生态成果,例如:借鉴GraphRAG服务(理念);
-
参考langfuse,补齐提示词管理能力;
七、待完善的应用客户端
有了以上基础,就可以进一步构建AI客户端/插件。
但大模型应用落地最难还是在AI客户端/插件。难在如何融入到实际业务场景;难在不仅仅只是嵌入到工作界面,还需要“理解”工作需求,并且能有效控制大模型的幻觉(对于生成式应用来说要避免大模型胡说八道)。
越深入业务场景,所需要的AI客户端体系也会越复杂。而从这点出发,目前大模型应用架构还比较简单,未来还会进一步演化,本文所指AI客户端或许应称为AI行业应用更为准确和恰当。
下面给大家分享一份2025最新版的大模型学习路线,帮助新人小白更系统、更快速的学习大模型!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享**
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















 3638
3638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









