



视觉 H同态加密:在隐写术中的应用
摘要
蜜罐加密(HE)是一种克服传统 password-based encryption(PBE)弱点的新技术。然而,传统蜜罐加密仍存在局限性,因其使用固定分布变换编码器(DTE),仅适用于二进制比特流或整数序列。本文提出一种称为 visual honey encryption的蜜罐加密变体,该方法在贝叶斯框架中采用自适应DTE,使得所提出的方法可应用于更复杂的领域,包括图像和视频。我们将该方法应用于构建一种新型隐写方案,显著提升了传统隐写术的安全级别。
分类与主题描述
E.3[Data]:数据加密
关键词
蜜罐加密(HE),基于密码的加密(PBE),隐写术
1. 引言
Password-based encryption(基于密码的加密)方案具有许多实际应用,特别是在加密和解密密钥需要由用户记忆的情况下。例如,基于密码的加密被用于保护安卓手机用户的敏感数据;磁盘或卷加密密钥由用户的屏幕解锁密码和一个盐值[13]派生而来。不同于生物识别和加密密钥相比,密码易于实现且无需额外的硬件支持。然而,密码本身也存在固有的局限性——即记忆性和安全性。一个难以猜测的密码往往也难以记住。
因此,正如人们所预料的那样,许多用户倾向于选择容易记忆的密码,而不太关注其安全影响。普通用户经常使用诸如‘password’和‘abcd1234’之类的简单密码。结果,实际的密码空间远小于理论上的密码空间[4, 11],,使得暴力破解和字典攻击成为可能且有效。例如,一项针对从真实用户收集的544,960个密码的研究显示,用户密码的平均熵约为40.5比特,低于许多系统采用的128或192比特标准[6]。也就是说,当使用基于密码的加密方案时,攻击者可能仅在理论上可能密码的一个小子集中搜索,即最常用的那些密码,并通过猜测用于推导加密密钥的密码来破解加密信息[7]。
Honey encryption(同态加密)被提出以克服基于密码的加密方案[9, 8]的局限性。 Honey encryption生成的密文不仅可以通过正确的密码解密,也可以通过错误的密码解密。在此方案中,错误的密码会生成看似有效但实际上为假的明文,从而迷惑试图通过暴力破解攻击解密密文的攻击者。因此,即使尝试了所有可能的密码组合,攻击者也无法识别出原始明文。朱尔斯和里斯滕帕特[9]提出了一种通用框架,通过使用一种新的(随机化)消息编码方法——针对二进制比特流和整数的 distribution-transforming encoders(DTE)——来构建蜜罐加密方案。然而,该方案仍存在实际局限性,因为它在编码与解码过程中使用了固定的简单DTE。也就是说,朱尔斯和里斯滕帕特[9]的蜜罐加密方案无法灵活应用于诸如基于自然语言的文本、声音和图像等多个应用领域,因为这些数据具有各自独特的合成或语义结构。例如,互联网上传输的大量多媒体数据可被解释为空间网格结构场。由于这种图像结构,邻近像素的颜色比相距较远的像素更相似。
本文档由 funstory.ai 的开源 PDF 翻译库 BabelDOC v0.5.10 (http://yadt.io) 翻译,本仓库正在积极的建设当中,欢迎 star 和关注。
遥远的那些。由于这种复杂的数据无法直接使用原始的蜜罐加密进行加密,因此需要一种新的蜜罐加密系统来处理此类结构化数据。我们简单地将这类数据命名为 multi-dimensional data,因为图像众所周知是一种二维数据类型,而电影可被视为一种三维数据类型。
在本文中,我们提出了一种新型的蜜罐加密变体,该方法可在贝叶斯框架下利用二维马尔可夫过程应用于复杂的多维数据。用于二维图像的马尔可夫过程是设计和解释图像合成结构的一个著名数学模型。在本文中,为了区别于原始的蜜罐加密,我们将该算法命名为 visual honey encryption,因为我们主要考虑的是视觉二维图像。针对使用图像的特定应用领域,我们建立了多维蜜加密与隐写术之间的联系,因为隐写术是安全领域中处理图像最广为人知的应用之一。从这一角度出发,我们提出了一种基于 visual honey encryption的新型隐写术。在本文中,为简便起见,我们也称这种新的隐写术为 honey steganography。
本文最终有三个贡献。首先,我们提出了一种用于蜜罐加密的自适应DTE方案。因此,我们无需像传统蜜罐加密那样固定或预先确定DTE。第二个贡献是,我们引入了一种新的蜜罐加密变体,该变体通过采用自适应DTE和贝叶斯框架设计,消除了原始方法的实际局限性和弱点。由此,我们可以将蜜罐加密应用于更复杂的数据,包括基于自然语言的文本和多媒体数据。我们将这种新的灵活蜜罐加密命名为 visual honey encryption。最后一个贡献是,我们提出了一种基于 visualhoney encryption的新隐写术,其在时间复杂度方面提升了传统隐写术的安全性。
2. 背景
2.1 蜜罐加密
蜜罐加密(HE)由朱尔斯和里斯泰帕特[9],提出,是一种类似于基于密码的加密(PBE)的对称加密方案。在HE中,加密算法使用密钥将消息加密为随机化的密文,解密算法则使用密钥将密文还原为原始消息,其方式与普通加密方案类似。蜜罐加密与传统对称加密之间的一个显著区别在于使用无效密钥时解密算法的输出:传统加密会返回一个错误符号,而蜜罐加密则会输出一条看似合理的消息。
同态加密(HE)提供了两种安全属性。如果与同态加密一起使用的密钥具有足够的不可预测性,则同态加密提供语义安全性,使得计算能力受限的攻击者无法从密文中恢复出有意义的信息。此外,同态加密还提供消息恢复安全性,使得即使计算能力无限的攻击者通过尝试所有可能的密钥来解密密文,仍然无法判断所恢复的消息是否有效。通过这种方式,同态加密能够抵御暴力破解攻击。构建同态加密方案的一种通用方法是:先对消息应用分布变换编码器(DTE),然后使用密钥对编码结果进行加密。
例如密码。DTE是一种消息编码方案,即使给定随机输入值,DTE解码算法也能在原始分布中采样出消息。朱尔斯和里斯泰帕特表明,信用卡号和RSA私钥可以通过同态加密安全地保护。
2.2 隐写术
载体修改是隐写术中一种众所周知的方法,载体图像用于嵌入并传递所需的秘密消息。给定载体图像,爱丽丝通过嵌入隐藏的秘密消息来修改该载体图像。爱丽丝与鲍勃之间的通信可以通过所有可能的载体图像集合以及密钥和消息的集合来进行。设 C、 K、 M和 S分别表示载体集合、所有隐写密钥的集合、所有消息的集合以及隐写图像的集合。通常情况下,由于隐写方案是一对嵌入与提取函数 EMB和EXT,我们有 EMB: C×K×M→ S,以及 EXT: S×K→M,使得对于所有c ∈ C、m ∈ M和k ∈ K,满足 EXT(EMB(c, k, m), k) = m。此处,令s = EMB(c, k, m)为s ∈ S的隐写图像。在隐写术与隐写分析中,大量研究集中在构建完全安全的隐写术上,即隐写图像的分布 ps与载体图像的分布 pc相同。
Kullback‐Leibler(KL)距离是衡量完全安全隐写术的一个著名指标,其定义为 DKL(pc||ps) = ∑c∈C pc(c) log pc(c) ps(c)。根据KL散度,当 DKL(pc||ps) = 0时,我们可以说爱丽丝的隐写系统是完全安全的。在这种情况下,恶意者Eve无法区分载体图像与隐写图像。然而,构建这种完全安全的隐写术往往不切实际,许多实际的隐写系统并非完全安全。尽管如此,它们在约束条件 DKL(pc||ps) < ε下是 ε‐安全的。本文中,我们在KL散度之外提出另外三种度量方法:均方根误差( RMSE)、峰值信噪比(PSNR)和结构相似性(SSIM)[16]。
2.3 多维数据
我们定义了一些与多维数据相关的术语,以便更好地理解传统同态加密与我们所提出方案之间的差异。因此,在本文中,One dimensional data指代像‘1011001’这样的二进制比特流和像‘01028553945’这样的整数序列。 Multi-dimensional data指代更复杂的数据,包括图像、基于自然语言的文本和电影。
迄今为止,同态加密(HE)仅处理一维数据并生成一维的蜜词(虚假数据)。然而,随着计算机性能的提升,多维数据变得越来越普遍。包括图像和电影在内的多维数据是多媒体数据最常见的形式,但无法使用传统的蜜罐加密进行加密,因为传统方法只能处理一维数据。因此,为了使蜜罐加密适用于大多数多媒体数据,有必要开发多维蜜加密。为了区分传统的单一维度蜜罐加密与我们所提出的方法,在本文中,我们将所提出的方法命名为
Visual honey encryption (VHE)。
在VHE中,通过在错误密码下进行加密的编码操作生成的蜜多媒体数据集无法与原始多媒体区分。
数据,可以仅使用正确的密钥进行解密和解码。
3. 威胁模型
在本节中,我们讨论威胁模型和假设。
攻击者可以访问加密数据,并完全了解我们的加密方案,但缺乏用于加密数据的密钥。我们假设攻击者是计算能力受限的,只能在多项式时间内运行,无法在不知道加密密钥的情况下破解加密算法;然而,攻击者能够在有限时间 T(n) 内破解隐写方案,其中 n 是所使用图像的大小。这一假设是合理的,因为大多数隐写技术在拥有足够资源的情况下已被有效的隐写分析所攻破 [1],而即使是最强大的超级计算机,要破解高级加密算法(例如 高级加密标准 [5])在计算上也是不可行的。
我们还假设,我们的加密方案所使用的加密密钥是从用户选择的密码派生而来的。这在实际应用加密算法于用户场景时是一种常见方法。特别是,基于密码的密钥派生函数2 (PBKDF2) [10] 被广泛用作密钥派生函数,它是RSA实验室公钥密码学标准 (PKCS) 系列的一部分。
然而,在实际中,许多用户选择易于记忆的密码,而未充分关注其安全影响。因此,实际使用的密码空间远小于理论密码空间[4, 11], ,这极大地增加了攻击者通过猜测攻击破解密码的可能性。也就是说,我们假设攻击者可以迭代地猜测用户选择的密码,并尝试推导出加密密钥以解密加密数据。我们用 Ψ表示实际密码空间,它远小于理论密码空间。我们注意到 |Ψ| 表示实际密码空间的大小。
根据上述威胁模型和假设,我们的目标是保护用户在加密图像中的秘密消息,使得攻击者仅知道加密数据的存在及其特征(例如创建时间、大小等),而无法获知秘密消息本身。
4. 所提出的方法
在本节中,我们首先展示VHE的主要概念和结构。然后,我们提出一种新的方法来构建VHE的DTE,以适应多维数据。随后,我们展示如何使用VHE的DTE进行数值的编码和解码。
4.1 概念
VHE 使用从多维数据的统计特性中提取的码本对发送方和接收方的数据进行编码和解码。在此过程中,只有拥有正确密码或密钥的授权用户才能获得正确的数据(图像/视频)。相反,没有正确密码的非授权用户无法获取原始数据的信息,他们将得到一个错误但看似有效的多维数据,该数据由我们的统计码本和 DTE 的规则生成。
在本文中,我们特别关注将VHE应用于图像,因为图像是多维数据类型的代表性示例。需要注意的是,我们的V HE并不加密和编码多媒体的头部信息,而仅加密其内部像素值。从这一角度来看,尽管VHE也可用于通信信道,但我们提出的VHE更应被视为一种文件加密系统而非信道加密。此外,与文本数据不同,像素具有高度相似性,即真实图像的像素值并非随机,而是与其邻居高度关联。这种邻域结构为图像的实际应用提供了许多有用的数学特性。例如,马尔可夫随机场(MRF)被用于建模此类邻域结构,以降低图像计算的时间复杂度。在本文中,基于这一数学特性,我们利用马尔可夫规则从图像生成自适应DTE。
4.2 VHE的结构
VHE 包含一系列顺序过程:(1)数据选择,(2)使用统计公式进行码本构建,(3)使用码本进行编码与解码,(4)使用密钥/密码 K1 进行加密,以及(5)加密消息的传输。每个过程均被详细描述如下:
-
数据选择:首先,我们为明文图像选择两种类型的图像,隐写图像p 和 dc公开图像Ys。明文图像与伪造图像具有相同的格式和大小。明文图像是隐藏信息,而伪造图像是公开的。公开图像在爱丽丝和鲍勃之间共享,以便用于构建DTE。这一点即使对作为恶意主体的Eve也是公开的。由于编码器和解码器应使用相同的DTE,因此伪造图像必须在爱丽丝和鲍勃之间于通信之前共享。
-
使用统计公式进行码本构建:设x、Y和 θ分别表示编码空间、一组公开图像以及模型的其他公共参数。在此阶段,VHE利用选定的图像Y及其他已知参数,为统计码本构造完整的联合目标后验分布 p(x|Y θ),该分布在传统蜜罐加密中用作DTE。由于每个像素是按逐像素顺序依次编码的,其中 ne(i)表示第 i个像素的邻居的索引集合,VHE系统地使用条件后验分布p(xi|x ne(i), Y θ),而非完整的联合目标分布。一旦第 i个像素的条件后验分布被构造出来,VHE便构建相应的条件目标后验的累积质量函数(CMF)。令pi ∈{0, 1} d p和 c i ∈{0, 1} d c分别为第 i个明文图像和第 i个编码数据。为简便起见,d c对于灰度图像取8,对于真彩色图像取24。
-
使用码本的编码与解码:在编码与解码阶段,VHE 使用统计码本、累积质量函数(CMF(·))将 pi 编码为 c i 或将 c i 解码为 pi 。该累积质量函数起到统计作用
码本 by
ci= CMF(pi), for encoding and ci ∈{0, 1}dc
pi= CMF−1(ci), for decoding pi ∈{0, 1}dp(1)
其中 dp ≤ dc。也就是说,通过累积质量函数 CMF(·) 将具有 dp 位二进制数字的输入值编码为 dc 位二进制数字,而CMF−1() 是其逆运算。因此,明文图像中的每个像素值都可以根据共享公共图像的统计特性进行编码或解码。
-
使用加密密钥进行加密 K1和使用解密密钥进行解密 K2:加密通过使用高级加密标准、RSA等传统加密算法完成。如果 K2= K1在对称密码系统中针对适当的接收者鲍勃,加密密文将被正确解密,然后通过我们的DTE解码为隐藏的明文图像 p。否则,加密密文将被解密为一个与实际比特流不同的随机序列,因为 K1 6= K2,恶意主体Eve将获得从该随机序列解码出的伪造图像 h的变化形式。
-
加密数据的传输
例如,我们有一个隐藏的明文图像 p(如图1‐(a)所示)和一个公共图像 Y(如图1‐(b)所示)。如图1‐(c)和图1‐(d)所示,在对称加密系统中,当 K1和 K2相同时,接收者可以得到正确的隐藏图像。然而,当 K1 6= K2时,接收者将获得一些变化的伪造图像。也就是说,只有一个p,但却有 |Kenc/dec| h,其中|Kenc/dec| 是 K1 ∈ Kenc和 K2 ∈ Kdec进行加密或解密时的密钥或密码空间的基数。

4.3 与隐写术的关联
图1显示,当使用错误密码对密文进行解密和解码时,Eve获得的虚假图像具有与期望的真实图像相似的特性。视觉蜜罐加密(VHE)的优势在于,Eve完全不会得到无意义的随机图像。然而,VHE在实际中可能由于以下两个原因而不够实用:1)图1‐(c)和图1‐(d)不同,它们的直方图也会不同,因此机器能够区分它们;2)尽管存在如图1‐(d)所示的各种伪造或欺骗图像h,但这些图像比图1‐(c)中的原始明文图像p更接近公共图像Y。因此,我们所提出的视觉蜜罐加密并非完美的蜜罐加密。然而,我们意识到存在一种简单但实用的解决方案来解决此问题。
解决方案是将p替换为Y。在这种情况下,接收者输出p和 h之间的差异显著减小,使得图2中的 |p −h| 小于图1中的 | p −h| 。

图2展示了如何实现实用VHE。然而,在这种情况下,我们无法像图1所示那样自行选择要发送的隐藏图像,因为p必须是公共图像Y的一个变体,即p ≈ Y。有趣的是,我们发现通过将VHE与隐写术相结合,可以克服这一实际缺陷。我们可以将秘密消息m嵌入到现在作为载体图像c的p中,即s= Emb(c, m)。在这种情况下,p=s ≈Y且m=Ext(s),但 m ≠Ext(h)。
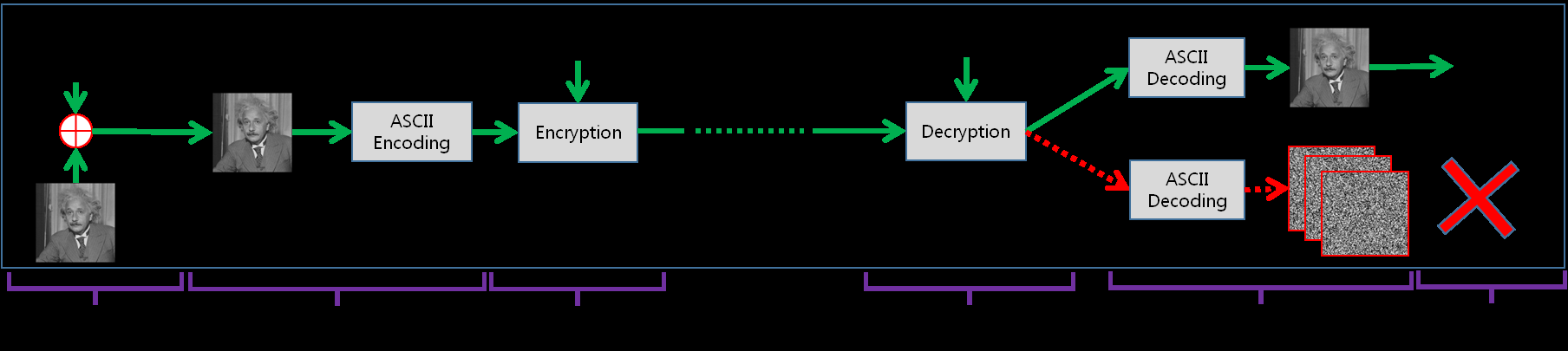
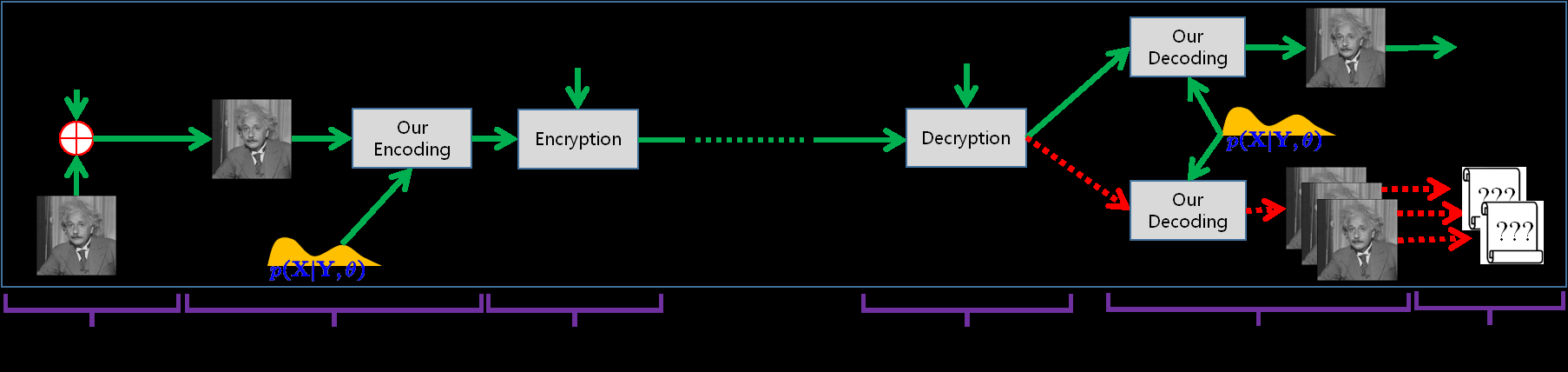
通过将隐写术与实用VHE相结合,本文提出了一种新的强大隐写术算法,如图3所示。该图展示了三种不同的隐写术模型。图3‐(1)是传统的隐写术模型,其中隐写图像直接传输给鲍勃,且未经过任何加密。攻击者仅通过隐写图像执行隐写分析以提取隐藏消息。图3‐(2)比图3‐(1)更为复杂,因为在通信过程中增加了加密过程。尽管在实际中许多系统遵循此模型(因为通信信道日益加密),但它在隐写术或加密方面均未带来理论上的改进,因此在文献中尚未被广泛讨论。图3‐(3)展示了我们提出的模型,它是图3‐(2)的一种变体,其中传统的ASCII编码器和解码器被我们提出的基于DTE的编码器和解码器所取代。
4.4 编码/解码分布的构造
在描述基于VHE的新隐写方案的主要算法(如图3‐(3)所示)之前,我们先定义算法中使用的符号。
在此表中,p表示隐写图像p,Y表示假图像,二者均为 L1 × L 2 大小的矩阵,而 x和 y分别是它们对应的向量化形式,对应 L1 L 2 × 1为 L= L 1 L 2 。
我们所提出的方法背后的基本思想是使用统计编码方案,而不是传统的ASCII编码方案。给定一个隐写图像s和一个假图像Y,我们可以通过重构底层概率密度函数来进行编码或解码过程。在本文中,用 p(x|Y θ)表示密度函数,类似于蜜罐加密的DTE。该分布可以在贝叶斯框架中得到很好的解释。
为了简化表示,我们将矩阵向量化以构建x和y,转换为x= V(s) 和 y ( n ) = V(Y ( n ) ),这是传统贝叶斯统计中更熟悉的形式。在此向量化形式中,x表示x 1:L 1 L 2 ={xi} L 1 L 2 i=1 。通过
(1) 无加密模块的隐写术
(2) 带加密模块的隐写术
(3) 提出的Honey隐写术
 无加密模块的隐写术,(2) 带加密模块的隐写术,(3) 提出的Honey隐写术。在本图中,绿色实线箭头表示爱丽丝和鲍勃之间的适当通信流程,而红色虚线箭头表示爱丽丝和Eve之间的不当流程。图中有六个步骤:(a) 将消息嵌入载体图像,(b) 编码,(c) 加密,(d) 解密,(e) 解码,和 (f) 提取消息。)
无加密模块的隐写术,(2) 带加密模块的隐写术,(3) 提出的Honey隐写术。在本图中,绿色实线箭头表示爱丽丝和鲍勃之间的适当通信流程,而红色虚线箭头表示爱丽丝和Eve之间的不当流程。图中有六个步骤:(a) 将消息嵌入载体图像,(b) 编码,(c) 加密,(d) 解密,(e) 解码,和 (f) 提取消息。)
| 符号 | 定义 |
|---|---|
| N | 公开图像或 公开图像副本的数量 |
| d p | 每次操作明文的二进制位数 每次操作明文的二进制位数 |
| dc | 每次操作明文的二进制位数 每种操作的密文 |
| m | 要发送的密文消息 |
| c | 用于隐藏密文的封面图像 消息将被嵌入 |
| s | 包含 c和m 的隐写图像 |
| z | 来自 s 的编码数据 |
| p | 要发送的隐写图像p= s |
| Y | 公开图像 |
| V(·) | 一个变换函数 从矩阵到向量 |
| x | 一种编码s的向量化形式 |
| y | 一种编码Y的向量化形式 |
| u | 加密数据 |
使用贝叶斯链式法则,我们现在有
p(x|y, θ)=
L
∏
i=1 p(xi |x1:i − 1 , y, θ) (2)
其中 L= L1L2。通常,图像具有特殊的网格结构,这通常用二维马尔可夫结构来建模,因为它可以利用马尔可夫毯减少计算的时间和空间复杂度。因此,我们有一个目标分布,并将其分解为
p(x|y, θ)=
L
∏
i=1
p(xi|xMB(i) , y, θ)=
L
∏
i=1
p(xi|xne(i) , y, θ).
(3)
这里, xi是第 i个像素的值。 MB(i)和 ne(i)分别表示第 i个像素用于依赖关系的马尔可夫毯和邻居。注意,我们所提出的方法按顺序执行编码和解码过程。因此,我们的直接目标是构造第 i个像素的条件分布,而不是整幅图像的完整联合分布 p(xi| xne( i ),y)。该条件分布意味着第 i个像素受到邻近像素和假图像p像素值的影响。
通过假设假图像中像素的独立性,可以进一步降低第 i个像素的条件密度
p(xi |Xne ( i ) , y, θ)= p(xi |xne( i ) , yi , y ∼ i , θ) (4)
其中 y i 是对应于 x i 的干净假图像的第 i个像素,y ∼i 表示除y i 外的y的向量化形式。即,y = y i ∪y ∼i 和 y i ∩y ∼i ={}。现在这
分布可以被重写为
p(xi|Xne(i), y, θ)= p(xi|xne(i), yi, y∼i, θ)
∝ p(yi|xi, θ)p(xi|xne(i), θ). (5)
在方程(5)中,我们现在有两个关键因素:似然函数 p(yi|xi, θ)和先验函数 p(xi|xne(i), θ)。这些在贝叶斯框架中进行解释。第一个因素是似然函数 p(yi|xi, θ),表示 xi 对伪造像素 yi 的拟合程度的概率。另一个因素是利用邻近值构建的先验项。在图像应用中,该先验通常使用马尔可夫随机场[2, 3, 12]来设计。
请注意,方程(2)和(5)主要针对单张伪造图像 Y 及其向量化形式 y。在单图像情况下,先验和似然对构建后验分布具有完全相同的影响。然而,我们可能拥有多张伪造图像而非仅一张。在这种情况下,这些方程可重写为 Y= y(1:N)= y(1), y(2), · · ·, y(N):
p(x|Y, θ)=
L
∏
i=1
p(xi|xne(i), Y, θ)
∝
L
∏ p(y(n) i |xi, θ)]p(xi|xne(i), θ)(6)
其中 y(n) i表示第 n张伪造图像的第 i个像素值。回到多张伪造图像中第 i个像素的条件后验分布,我们有 p(xi|xne(i), Y θ) =[∏N n=1 p(y(n) i |xi, θ)]p(xi|x ne(i), θ)。在本文中,我们使用常见的正态分布来定义似然和先验。
p(y
(n)
i |xi, θ)= N(y (n) i; xi, r 2 )= N(xi; y (n) i, r2)
p(xi|xne(i), θ)= N(xi; f(xne(i)), ρ 2
) (7)
其中 σ ∈ θ和 ρ ∈ θ是每个分布的标准差, N(·; a, b)是均值为 a、方差为 b的正态分布。 f(·)是任意线性/非线性函数。
已知正态分布的乘积会形成一个正态分布,如附录A所示。因此,方程(7)中的 p(xi|x ne(i), Y θ) 可通过合并后的正态分布统一表示
p(xi|xne(i) , Y, θ)= N(xi; µ, σ 2
) (8)
其中
σ= √ √ ∑
n=1
1
r2
+ 1 ρ2)
− 1
µ= σ 2(∑ N n=1 y
( n )
i
r 2
+
f(xne( i ))
ρ 2).
此外,可以通过将一张伪造图像复制成 N份来将其用于多张伪造图像。在本文中,我们通过这种方式使用一张伪造图像生成了 N张图像。在结果部分,我们展示了随着N的变化,影响程度也随之变化。
4.5 编码与解码方案
每个像素在单通道或灰度图像中有8位,因此 x i ∈{0, 1, · · ·, 2 8 − 1}。蜜罐加密的基本思想是改变编码和解码规则传统的ASCII到基于分布的编码方案。在统计编码方案中,每个值可以以不同的权重进行编码和解码。这意味着某些值可以比其他值具有更高的权重。为了实现这些不同的权重,需要增加编码数据的长度。换句话说,为了在dc位系统(dc= 8用于图像像素)中编码值,需要更长的比特来编码该值,即 dp ≤ dc。现在让我们回到单通道图像。在这种情况下,我们将 2dp个值编码为 2dc个二进制码。这也意味着 dc位图像被量化为 dp位像素。在结果部分,我们设置dp= 4和 dc= 8。
2dp个值的集合可以通过 Z={z0 ∪z1 ∪…∪z2dp−1}手动或自动定义。通常,对于 dc位图像,minZ ≤ 0和 2dc> max Z。我们首先对公式(8)中的条件后验分布 p(xi= z|xne(i), Y θ)进行离散化和量化,以表示 z ∈ Q的 2d= 16个离散值的概率质量函数(PMF)。现在第i个像素的累积质量函数定义为
p(i) cmf(zk)=
2k−1
∑
k=0
p(xi= zk|xne(i), Y, θ)
∑2d−1 j=0 p(xi= zj|xne(i), Y, θ)
. (9)
在使用公式(9)的累积质量函数进行编码或解码之前,我们需要对累积质量函数进行修改,以保持编码器和解码器的一致性。如前所述, 2dp值(符号)被编码为具有不同权重的 dc位数值。具有较高概率质量函数的符号将在 2dc值中覆盖更多的数值,而一些概率质量函数相对较低的符号将覆盖较少的数值。这些是蜜罐加密的DTE所具有的特性,也正是这些特性赋予了其强大能力。然而,它们会导致编码与解码操作中的不一致性。如果某些符号的概率质量函数低于 1/2dc,则我们无法对其进行编码。因此,我们需要调整概率质量函数和累积质量函数,以确保任何符号的概率质量函数都大于 1/2dc。为了实现这一点,我们降低具有主导权重的符号的概率,并将减少的权重分配给其他低权重的符号。

图4展示了关于从 d p 位数字编码到 d c 位数字的编码器以及从 d c 位数字解码到 d p 位数字的解码器的三个信息图。深蓝色条形表示公式(8)中 p(xi |xne( i ) , Y θ)的概率质量函数,绿色条形表示其对应的累积质量函数。最后,每个累积质量函数的条形代表 d c 位编码。也就是说, 2 d p p c i = CMF c i d c = 6 p i d p = 4 (i)的值被编码为 2 d c位二进制数字,通过()实现。例如,在图4中我们为简便起见进行了设置。
4.6 预处理的必要性
在上一节中,我们描述了累积质量函数(CMF)的过程以及如何为每种情况分配比特数组。尽管为每种情况分配比特数组看似简单,但在精确的编码与解码过程中仍有一个问题需要解决:每种情况必须至少对应一个比特数组。实际上,各种概率值差异较大,有些非常小,有些则占主导地位。然而即使是极小的概率值也必须用至少一个比特数组来表示;如果某个很小的概率值没有被分配到任何一个比特数组,那么我们就无法表达它。因此,在这一步骤中,我们必须为即使可以忽略不计的小概率也分配一个比特数组。这一过程虽然是必要的,但会改变各情况的概率分布,同时也会修改累积质量函数( CMF)。小于1/2dc的概率值被重新分配为 1/2dc,而占主导地位的概率值则被降低。由于小概率情况被赋予了概率 1/2dc,因此使用错误密钥解密和解码得到的输出图像 h 会呈现散粒噪声。因此,不幸的是,攻击者可以很容易地区分 p 和 h。
我们通过引入一个预处理步骤来解决这个问题,如图5所示:发送方的载体图像 c 被替换为对随机图像 r 解码后得到的若干 h 中的一个。这样,接收者的 s 和 h 既无法被人眼也无法被机器区分,从而满足具有 ε‐界限的蜜罐加密特性,即对于极小的 ε,有 | (Y − ˜s) −(Y −h)| < ε 成立。最后,我们可以为我们的蜜罐隐写术构建伪算法:爱丽丝使用的算法1,以及鲍勃和Eve使用的算法2,如文中所示。

5. 结果
5.1 数据描述
图6‐(a)的顶部(爱因斯坦)、中部(罗马)和底部(莱娜)是本文使用的原始图像。我们用I Einstein 、I Rome 和I Lena 分别表示爱因斯坦、罗马和莱娜图像。每幅图像的大小为 128 × 128,即L 1 = 128 和L 2 = 128,且均为灰度图像,因为仅使用了真彩色图像的红色通道。
5.2 实验中使用的参数
在仿真中,我们将 f(xne( i )) 简化为高斯马尔可夫随机场(GMRF)的滑动平均滤波器,通过 f | ∑ j ∈ ne ( i ) x j + ε i | ne ( i ) = 1 | ne i | ∑ j ∈ ne ( i ) x j x i = 1 | ne i ε i ∼ N · 0 ρ 2 | · | (x) () 满足 () ,其中噪声(; ,),且为基数一个集合。在此模型中,为简化起见,我们将方程(7)中的 r ∈ θ和 ρ ∈ θ固定为 r= 1和 ρ= √1/|ne(i)| 。然后,我们所关注的条件后验分布由 p(xi|xne(i), Y θ) = N(xi; µi, σ 2 i)构成,其中 σi=( N+ |ne(i)|)−1/2且 µi=(N+|ne(i)|)−1(∑N n=1 y(n) i+∑j∈ne(i) xj)。
5.3 评估指标
有一个重要问题需要解决,以验证我们所提出的方法。由于这种蜜罐隐写术也继承了蜜罐加密的特性,因此对于一个 ε‐安全隐写系统,我们需要验证使用错误密钥或密码获得的图像与使用正确密钥/密码获得的图像是机器不可区分的。有多种基于图像之间相似性或差异的度量方法可用于此目的:Kullback‐Leibler距离(KLD)、峰值信噪比(PSNR)、均方根误差(RMSE)以及结构相似性(SSIM)[15, 14] 。相似性度量的详细信息在[16]中描述。从现在开始,我们设定 type ∈{KLD, P SNR, RMSE, SSIM}。基于这些度量指标,应评估两种不同的情况:
- Dt yp e(Y,s) 和 {Dt yp e(Y,h(j))} R j =1:这是公共图像 Y 与使用正确解密得到的解码后的隐写图像 s,以及使用 R错误解密得到的解码后的蜜罐图像 h(1:R) 之间的距离集合。
- {Dt yp e( s,h (j))} R j =1 和{Dt yp e( h ( i ) , h (j)) } R i, j =1,i 6 = j :这是解码图像之间距离的集合。
在该设定下,我们估算每个指标的p值以评估其可区分性。
5.4 基于视觉蜜罐加密的隐写术(蜜罐隐写术)
图6展示了通过三幅图像的蜜罐隐写术获得的若干输入和输出图像。图6‐(a)、(b)和(c)由发送方爱丽丝处理。其他子图可由两种不同类型的接收方获得:合法接收方鲍勃得到图 6‐(d),恶意接收方伊芙得到图6‐(e)。
 →(b)→(c)→(d) 使用正确密钥,以及 (a)→(b)→(c)→(e) 使用错误密钥。每一列为 (a) 公开图像Y,(b) 噪声载体图像c,(c) 噪声隐写图像s,(d) 正确解码的图像 ˜s,以及 (e) 错误解码的图像h)
→(b)→(c)→(d) 使用正确密钥,以及 (a)→(b)→(c)→(e) 使用错误密钥。每一列为 (a) 公开图像Y,(b) 噪声载体图像c,(c) 噪声隐写图像s,(d) 正确解码的图像 ˜s,以及 (e) 错误解码的图像h)
图6‐(a)中的三幅图像是用于构建DTE的公共干净图像Y,其推断出的条件目标后验分布为 p(xi|x ne(i), Y θ),对应于 i ∈{1, 2, · · ·, L}。如我们所见,本文使用了这些干净图像,尽管在实际中Y可能是含噪声的或随机的图像。为了构建 DTE,Y在爱丽丝和鲍勃之间共享,且无需私有共享。因此, Y是公共信息,甚至恶意用户Eve也可以访问它。图6‐(b)展示了通过使用我们的DTE解码随机图像得到的三幅载体图像。即,我们有c=Decode(DTE, r),其中c ∈ C且r ∈ R。这些图像用于嵌入隐藏消息m。经过隐写过程后,我们得到了图 6‐(c)中的隐写图像s,它们由载体图像c和消息m组成。图 6‐(d)和‐(e)分别表示使用正确密码和错误密码解密后的图像。肉眼观察,它们看起来似乎没有区别。为了进行更科学的度量,我们计算了四种不同的指标来测量s、 ˜s和之间的相似性距离h。表2显示了图像之间相似性距离及其p值, Dtype(Y ˜s) 与 {Dtype(Y, h(j))}200 j=1。从表中可以看出,所有p值均大于 0.05,这是假设检验中常用的标准显著性水平。也就是说,我们可以说隐写图像与公开图像之间的差异在 ε范围内,即 | (Y − ˜s) −(Y −h)| < ε。
| 方法 | IEinstein | IRome | ILena |
|---|---|---|---|
| DKLD(Y, s) | 0.036 | 0.056 | 0.041 |
| (p值) | (0.685) | (0.055) | (0.735) |
| DPSNR(Y, s) | 1.02 | 0.911 | 0.974 |
| (p值) | (0.935) | (0.485) | (0.55) |
| DRMSE(Y, s) | 24.38 | 31.31 | 27.05 |
| (p值) | (0.895) | (0.465) | (0.555) |
| DSSIM(Y, s) | 0.762 | 0.876 | 0.833 |
| (p值) | (0.85) | (0.41) | (0.52) |
然而,表2是蜜罐属性的间接度量。理论上,蜜罐加密由 |˜s − h| < ε定义。因此,我们计算了 ˜s和hs之间的距离,并将结果列于表3中。 ˜s和hs之间的平均距离接近分布的众数位置,这意味着预期的p值大于显著性水平0.05。因此,我们证明了|˜s −h| < ε,并得出结论:在实践中,我们提出的 VHE成为了蜜罐隐写术。
| 方法 | IEinstein | IRome | ILena |
|---|---|---|---|
| E[DKLD(s, h)] | 0.052 | 0.060 | 0.053 |
| (E[p值]) | (0.523) | (0.552) | (0.528) |
| E[DPSNR(s, h)] | 0.915 | 0.866 | 0.897 |
| (E[p值]) | (0.593) | (0.570) | (0.527) |
| E[DRMSE(s, h)] | 30.99 | 34.70 | 32.29 |
| (E[p值]) | (0.5924) | (0.568) | (0.526) |
| E[DSSIM(s, h)] | 0.584 | 0.807 | 0.716 |
| (E[p值]) | (0.597) | (0.557) | (0.530) |
5.5 蜜罐隐写术的安全性分析
如前所述,图3展示了隐写术的三种不同框架:1)不带加密模块的隐写术,2)在加密通道中的隐写术,以及3)我们提出的蜂蜜隐写术。与其他两种方法相比,我们提出的蜂蜜隐写术因其高安全性而表现出卓越的性能。从攻击者的角度来看,我们首先定义了四个功能
| 方法 | 攻击的时间复杂度 |
|---|---|
| 无加密模块的隐写术 | Tstego(n) |
| 在加密通道中的隐写术 | |Ψ|{Tgenerate(n)+ Tdecrypt(n)+ Trand(n)}+ Tstego(n) |
| 我们提出的蜂蜜隐写术 | |Ψ|{Tgenerate(n)+ Tdecrypt(n)+ Tstego(n)} |
表4:针对不同隐写术的攻击时间比较, n是图像大小的参数,|Ψ| 是可能的密码或密钥数量
用于计算经过时间的函数:(1) Tgenerate(n):从大小为 |Ψ|的密码生成密钥所消耗的时间;(2) Tdecrypt(n):解密时消耗的时间;(3) Trand(n):检查图像随机性时消耗的时间;(4) Tstego(n):使用隐写分析提取隐藏消息时消耗的时间。本文中,令 |Ψ| 表示可能密码的数量,即密码空间。通常情况下, Tgenerate(n)和 Tstego(n)远大于 Tdecrypt(n)和 Trand(n),因为在从密码生成密钥时通常会使用多次哈希操作,而隐写分析本身就是已知的耗时操作。我们简单假设 Trand << T generate n< Tdecrypt n n<< Tstego n ( ) ( ) ( ) ( )。基于此假设,在表4中比较了隐写分析识别隐写图像并提取隐藏消息所需的时间。如表所示,我们提出的蜂蜜隐写术由于所有解码图像都因不可区分性而需经过隐写分析处理,因此需要(|Ψ| −1)Tste g o(n)倍更多的执行时间。而在传统隐写算法中,这是不必要的,因为使用错误密码或密钥解密和解码出的所有图像都是随机的,只有使用正确密码或密钥解密出的图像例外。图7展示了对表4中执行时间复杂度的模拟结果。正如预期,对我们提出的方法进行攻击需要更长的执行时间,因此我们的方法更加安全。
6. 实现问题
6.1 不同 N 的影响
由于我们使用的是单张图像而非 N多张公开图像,爱丽丝和鲍勃应共享正确的 N值。如果爱丽丝和鲍勃的 N不同,则鲍勃将无法获得正确的数据。此外,我们通过改变 N对系统进行了仿真。如图8所示,解码后的图像越来越接近原始的伪造图像分布是通过更多的伪造图像构建的,但相邻像素的值是固定的。
6.2 用于蜜罐隐写术的简化DTE
根据公式(3)针对单张伪造图像和公式(6)针对多张伪造图像,假设曲率空间x为 d阶马尔可夫模型,以保证物理图像的平滑性和真实性。也就是说,p(xi|x1:i−1,Y) 可简化为 p(xi|x ne(i), Y),从而大幅减轻计算负担。然而,我们仍可通过假设 xi⊥xj之间的独立性来进一步简化建模,尽管 xj ∈ ne(i)以及 xi的先验可能遵循均匀分布。此时,使用多张伪造图像的目标分布变为 p(x|Y θ) =∏ L i=1[∏ N n=1 p(y (n) i |xi, θ)]×p(xi|θ) =∏ L i=1∏ N n=1 p(y (n) i |xi, θ)。在这种情况下,伪造图像是构建该分布时需要考虑的主要因素。
7. 结论
众所周知,传统蜜罐加密仅适用于二进制比特流和整数序列等有限领域。然而,还存在许多具有合成或语义结构的复杂数据类型,如基于自然语言的文本、图像、视频。本文提出了一种新型的蜜罐加密变体,可应用于此类复杂数据类型。所提出的方法在贝叶斯框架中设计,可用于创建一种新型隐写方案,该方案使得隐写分析具有高时间复杂度。通过使用这种新型隐写方案,该隐写术比任何传统隐写术都更安全。

















 331
331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









