



 本文详细介绍了目标检测的发展历程,从RCNN到Faster R-CNN再到SSD,解析了不同阶段算法的创新点和挑战。RCNN引入了选择性搜索和卷积神经网络,Fast R-CNN优化了网络结构,而Faster R-CNN则改善了候选区域的生成。SSD作为一阶段方法,通过多尺度特征图和先验框提升了检测效率。
本文详细介绍了目标检测的发展历程,从RCNN到Faster R-CNN再到SSD,解析了不同阶段算法的创新点和挑战。RCNN引入了选择性搜索和卷积神经网络,Fast R-CNN优化了网络结构,而Faster R-CNN则改善了候选区域的生成。SSD作为一阶段方法,通过多尺度特征图和先验框提升了检测效率。
什么是目标检测?
目标检测是图像识别中的一个应用方向,它的目的就是要去定位图片中存在物体的位置。然后在去判断这个物体是什么类型。
目标检测的三大步骤
(1)区域选择
从图片中列举出可能存在物体的n个子图。
(2)特征提取
从列举的子图中提取出图像特征
(3)分类器
常用的分类器与svm,adaboost
目标检测算法存在着几个发展的阶段,下面将一一介绍
第一阶段:rcnn
在区域选择阶段,采用selective search或edge box的方式来获取到待预测的区域。相对于传统的穷举或是滑动窗口来说,selectIve search在算法的复杂对上要简单很多。selective search是根据图片的纹理,颜色,大小来筛选出带待识别的子图的。
selective search大概会选出大概2000个候选框。通过拉升变形使的子图处于同一规格。但是2000个候选框还是太多了。
所以在rcnn论文中,作者将候选框与groundtruth重叠度大于0.5的设置为正例(不是背景),小于0.5的设置为反例(背景)。最后随机选取32个正例和96个反例。
在特征提取阶段,rcnn采用卷积神经网络来提取固定长度的特征。原作者采用的是AlexNet网络。
在分类阶段,采用svm进行分类,原作者为每一类都训练了一个svm分类器。
使用rcnn算法进行目标检测时所遇到的问题?
a. 当我们提取候选区域的时候,可能会存在重叠度很大的两个候选区域。但其实,我们只需要一个就好了。
这个时候我们需要通过极大值抑制来解决这种情况。
非极大值抑制说的是,当存在重叠度大于一定阈值的区域时,会抛弃评分较低的那个区域。
b. selective search选出来的候选框P和人工选出来的候选框G存在差距,也就是selective search选出来的P框不准确。怎么解决?
通过bounding-box回归的方式,来矫正候选框的位置。试验所得,当Iou大于0.6的时候,位置矫正是有作用的。如果P离G太远,位置矫正是不起作用的。bounding-boxd单独训练。
第二阶段:fast-rcnn
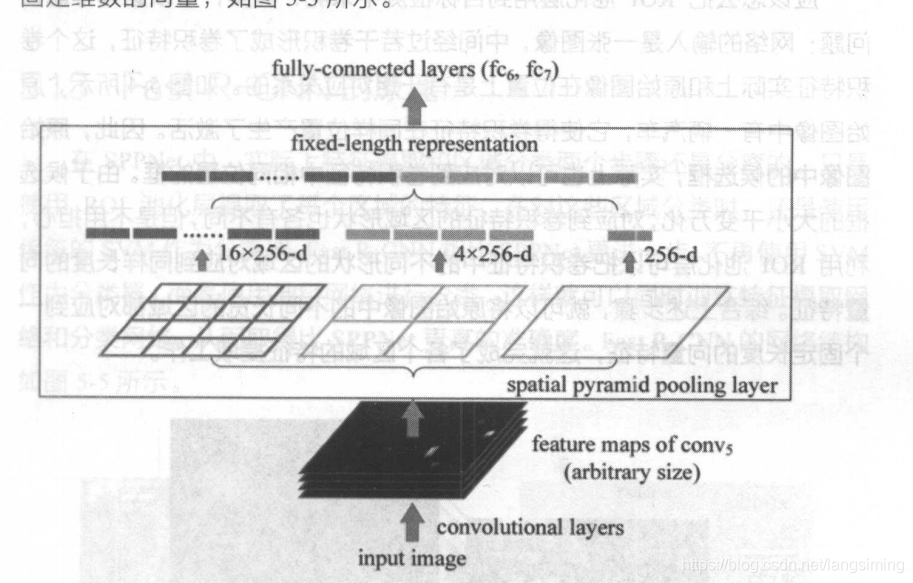
在介绍fast-rcnn之前,先介绍一下sppnet算法。sppnet的作用在于,它可以使输入图片的大小不固定。如下图所示,我们可以看到,sppnet算法是于卷积层之后,全连接层之前的。sppnet的引入大大提高了rcnn网络的运行速度。
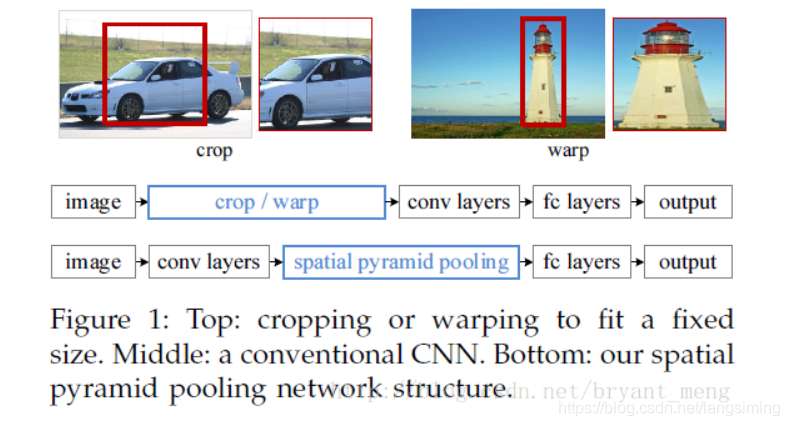
sppnet原理:
对卷积后的矩阵先进行4*4等分取(不能等分时取整)出每一块的极大值,再进行2*2等分取出每一块的极大值,再进行1*1等分取出每一块的极大值。加入卷积的通道数是C,那么将得到16C+4C+1C=21C。
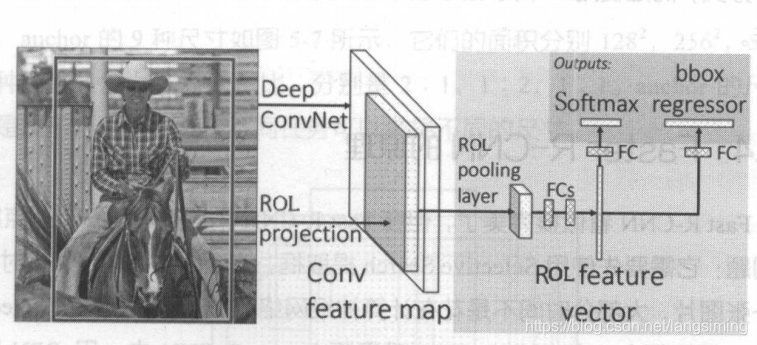
下面开始介绍fast-rcnn
fast-rcnn相对rcnn的改进点如下:
(1)引入sppnet中的roi池化
(2)将bounding-box加入到rcnn网络当中
(3)用softmax代替svm用于分类
第三阶段 faster rcnn
faster rcnn改进了proposal region的提取方式,使用rpn网络代替了selective search,并且将一直分离的region proposal和cnn合并到了一直,大大提高了获取候选区域的位置的速度和精确率。
下面简单介绍一下faster-rcnn的流程
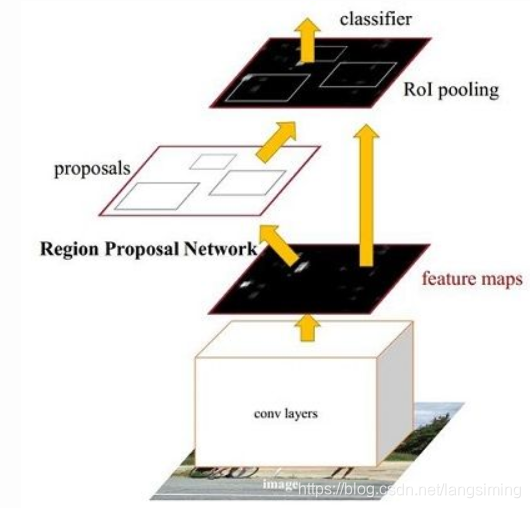
第一步,卷积提取特征;
第二步,使用rnp网络获取到候选框
第三步,使用roi池化得到所有候选区域的特征图
第四步,先判断图片的类别,然后在利用bouding box regression优化回归参数
更多详细内容可以参考https://www.cnblogs.com/chaofn/p/9310912.html
第四阶段
SSD,SSD相对于前面几种方法而言属于1阶段方法,前面几种方法数据2阶段方法。
SSD的特点如下:
1. 采用多尺度特征图,大的特征度用来检测小的物体,小的特征图用来检测大的物体。
2. 采用卷积的方式进行检测
3. 设置先先验框,每一个单元格都会有多个先验框。
SSD实现的流程图如下:
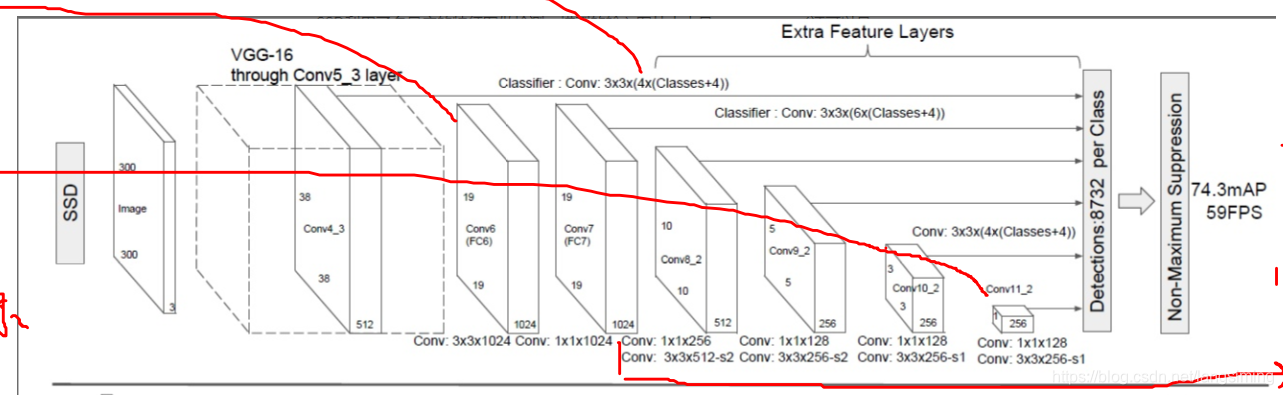
ssd的流程实际就是vgg16的流程,不同的从第4层开始,它不仅仅是简单地做一个卷积和池化的工作,它还需要进行目标检测和先验框回归的工作。
先验框的计算方式如下
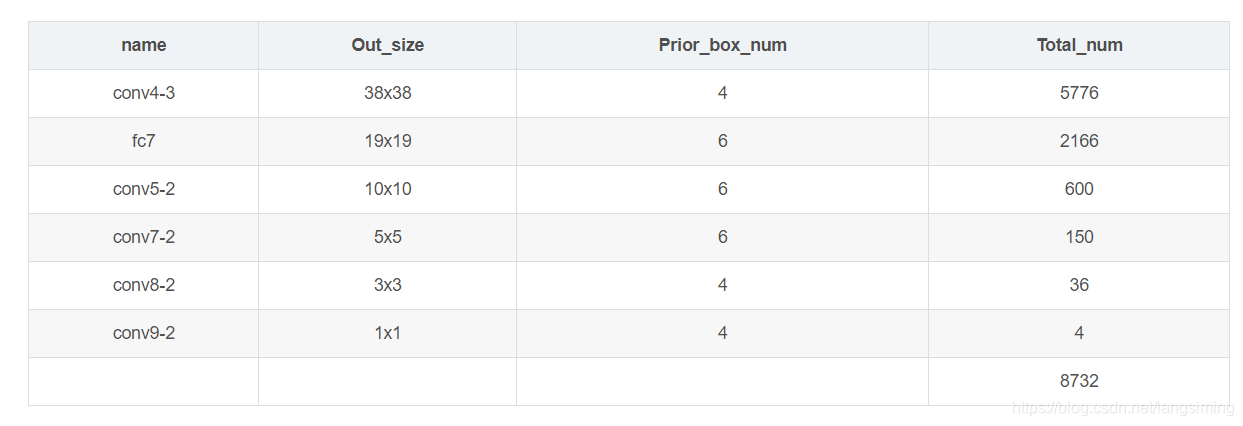
一个像素点上怎样获取到4个先验框?
1. 先以 min_size为宽高生成一个框。
2. 如果存在max_size则用sqrt(min_size_ * max_size_),生成一个框。
3. 然后根据 aspect_ratio,再去生成。如上面的配置文件,aspect_ratio=2,那么会自动的再添加一个aspect_ratiod = 1/2。
如果是6个框则是,1,2,3,1/2,1/3
每个卷积层上的先验框大小如何来确定?
原图像大小乘上一个固定的比例,这个比例随着卷积的进行再逐渐变大。
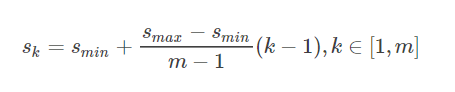
其中smin=0.2,smax=0.9,m=5。那么比例序列0.2,0.37,0.54,0.71,0.88,然后统一乘上300就是先验框的大小。
下面看看ssd的损失函数是如何弄的?
ssd的损失函数是由分类损失和框回归加权相加得到的。
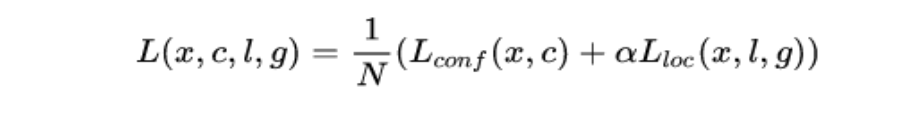
其中位置误差的函数定义如下:
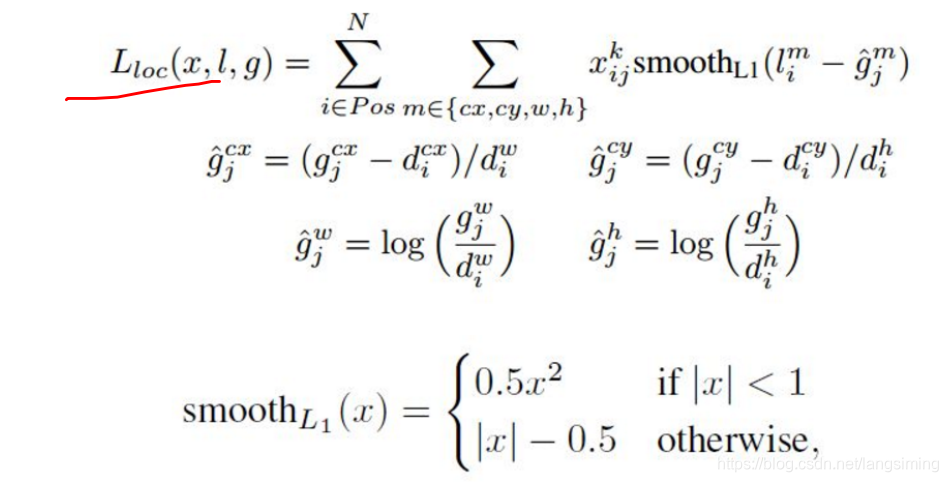
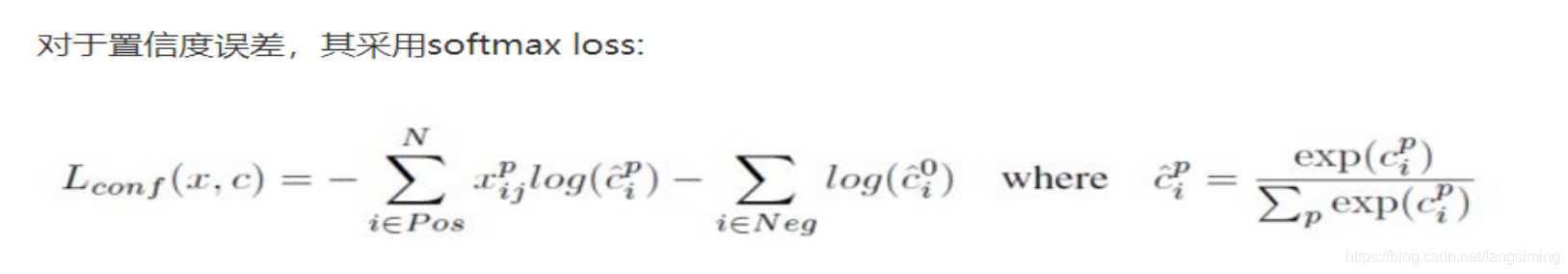

















 3922
3922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









