





目前,流行的大型语言模型训练时的框架为Transformer和Pytorch,但是,在模型的演变历史当中,采用了各式各样的类神经网络框架。
01 Transformer 运行机制
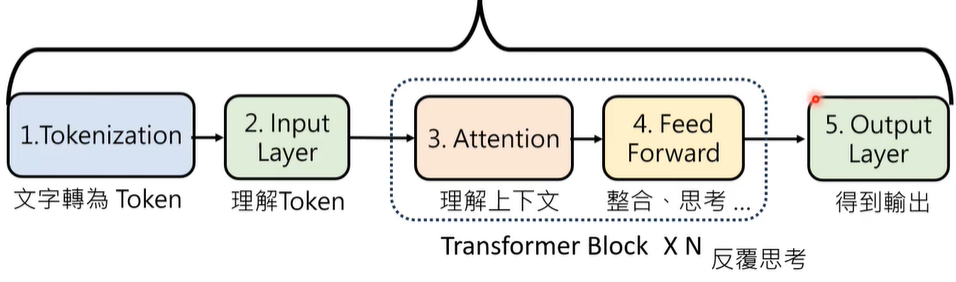
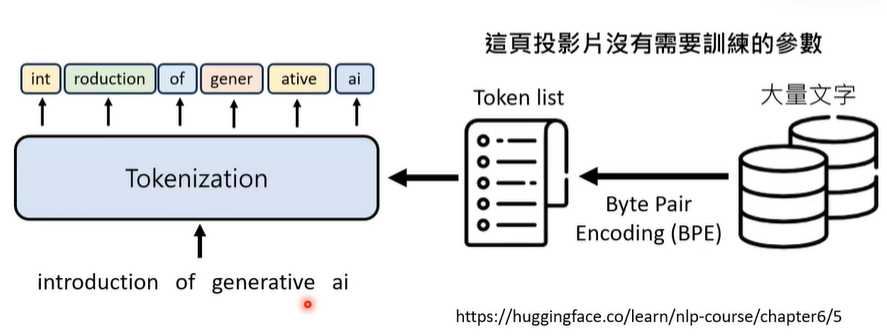
① Tokenization:语言模型以token为单位对文字进行切割。

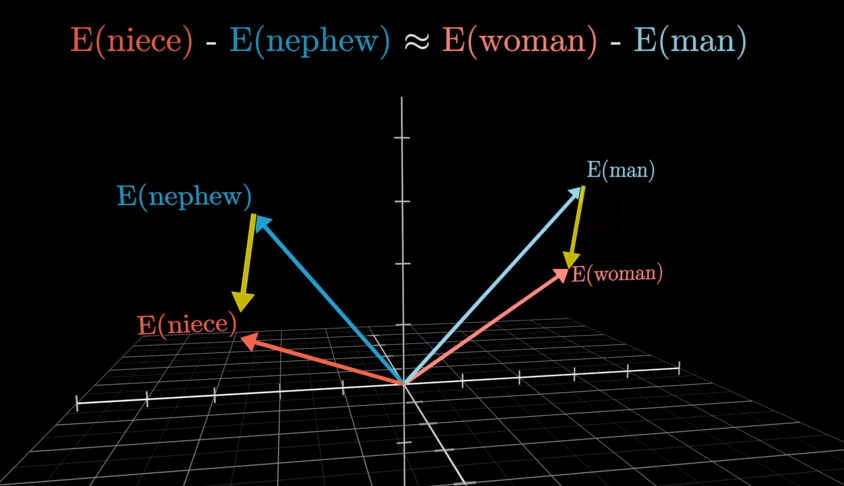
② Embedding:理解token和语义
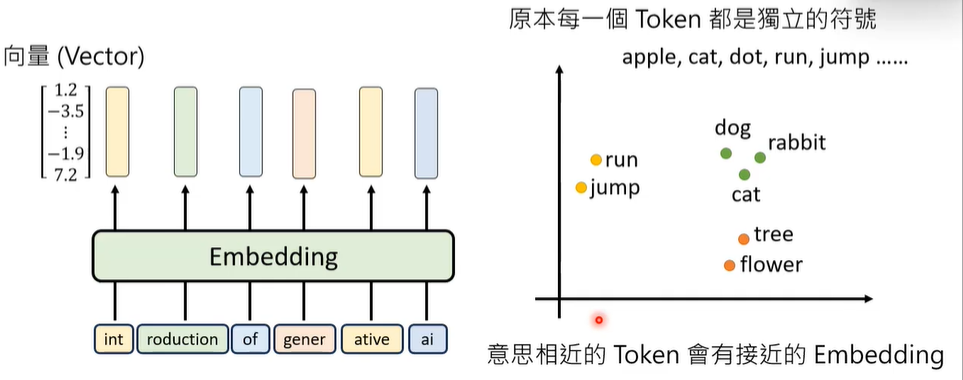
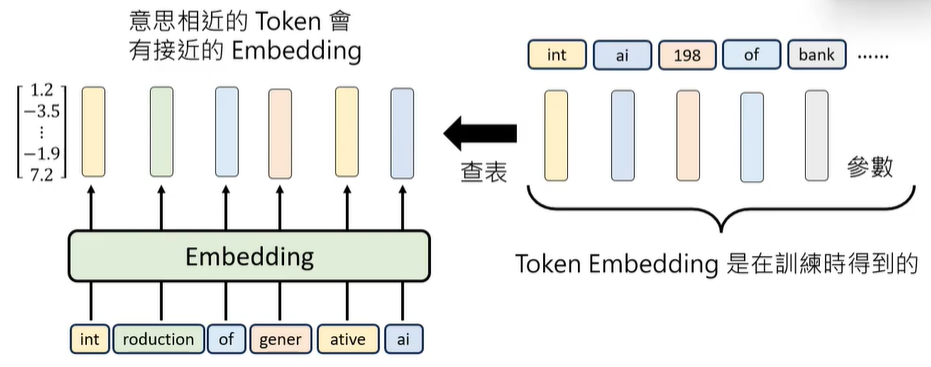
第一步训练出来的参数转化为第二阶段的初始向量,生成向量参照表。

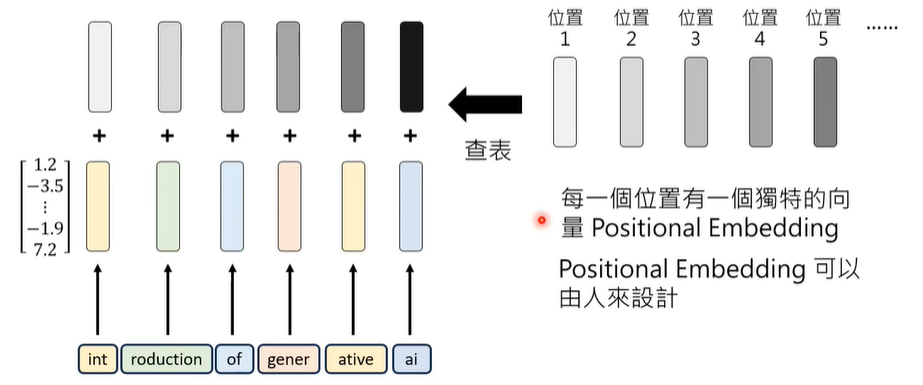
但是,仅仅拥有向量参照表,没有参考上下文,会无法区分词汇在不同语境下的不同含义,因此,引入人工标注的位置向量。
③ Attention
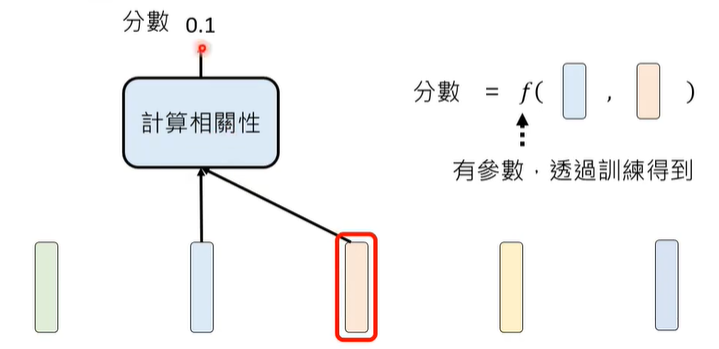
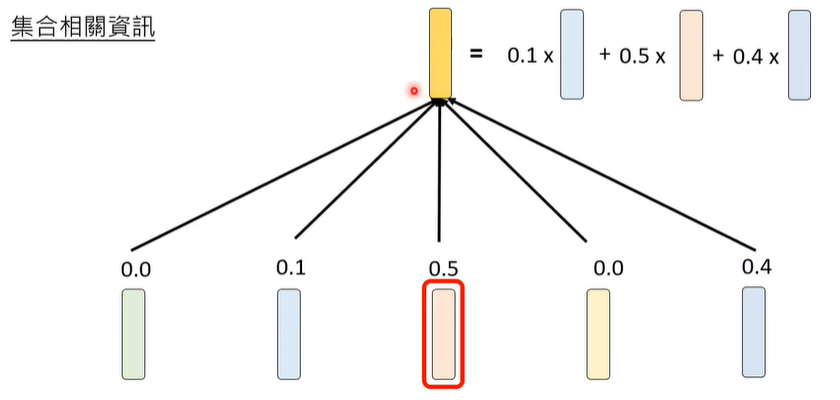
Attention要做的第一件事情,是计算两个token之间的相关性(Attention Weight),如何计算,这里面也含有大量的参数,也是需要学习的,最终,注意向量是所有向量*所有参数的增加。
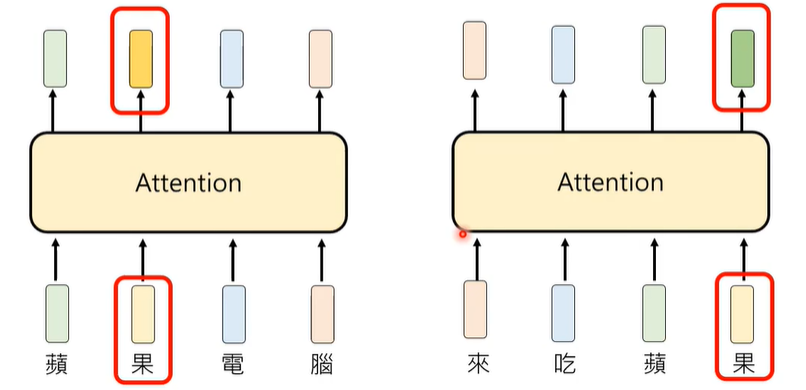
事实上,我们在计算某一个token的attention weight时,不会去管它右边的token,只会管它这个句子左边的token,这种Attention我们称之为Causal Attention。
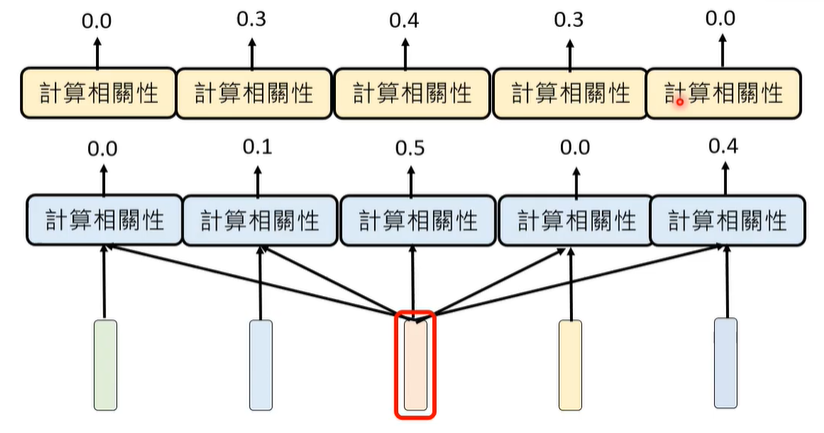
还有一种Attention,叫做Multi-head Attention,即有很多个模组,都会计算相关性。

④ Feed Forward
得到每一个注意向量,最终采用Feed Forward将所有的注意向量整合起来。关于Feed Forward,这里面同样还有大量的参数和复杂的学习过程。
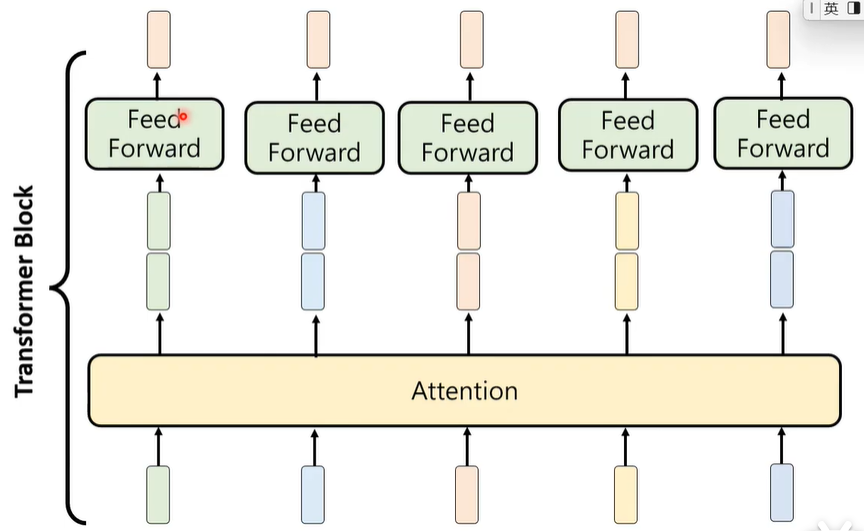
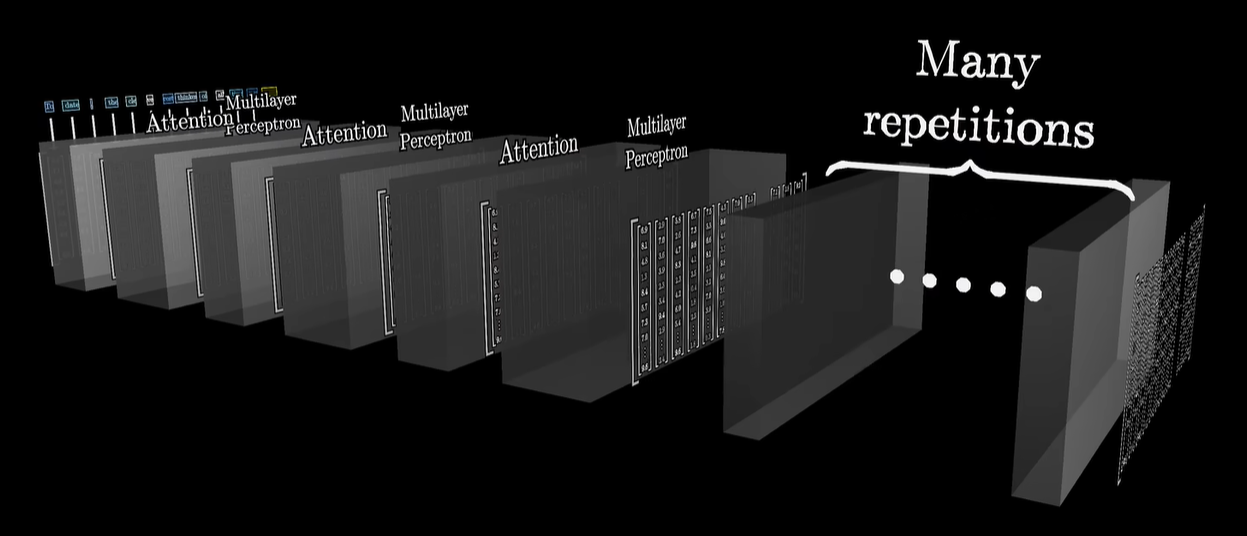
以上这些加起来,构成一个Transformer Block,其是Transformer的基本单位,一个Transformer里面,有很多个这样的基本单位。

⑤ Output Layer
在经历了很多个Transformer Block之后,在最后一个Transformer Block里,输出句尾向量,进入到Output Layer层次,里面含有Linear Transform和Softmax,会得到一个几率分布表。
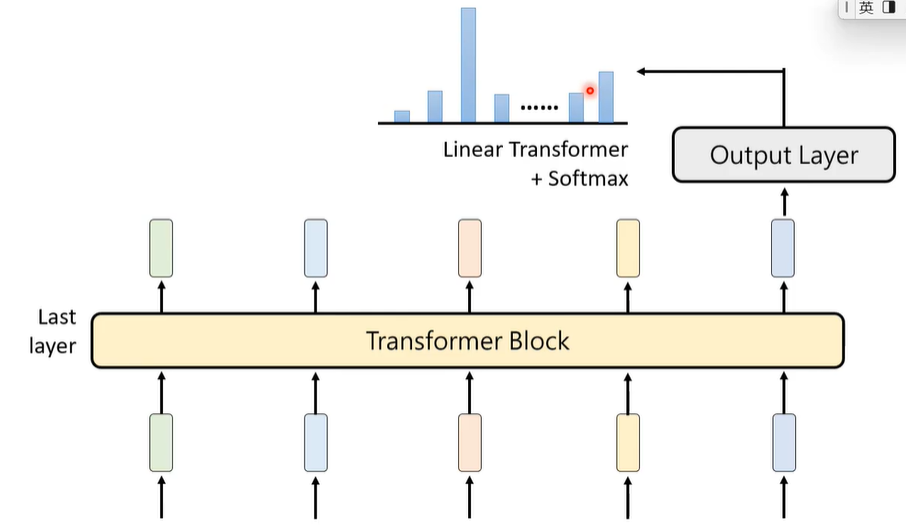
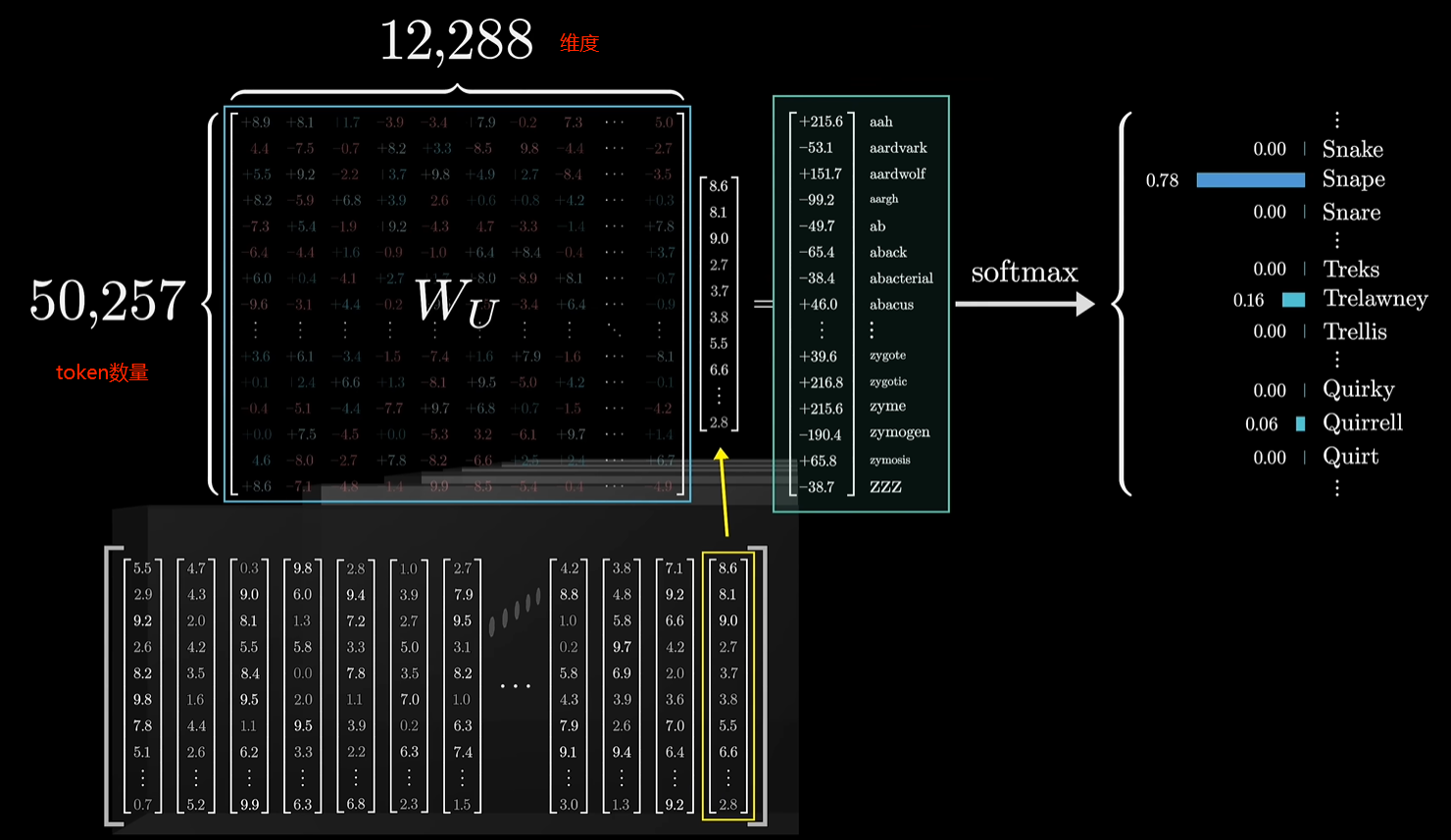
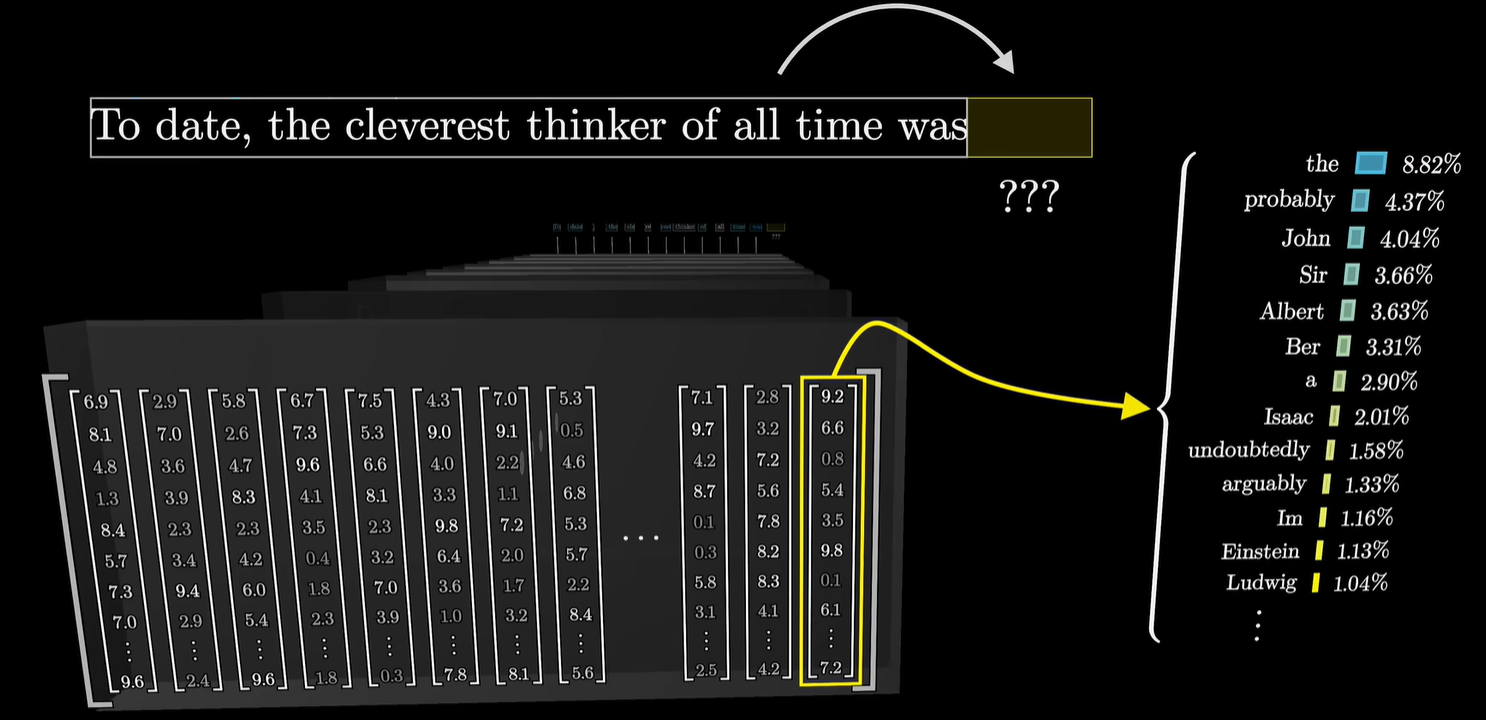
模型只通过最后一层的最后一个向量计算概率表格,相当于只通过最后一个词汇预测下一个词汇是什么,这听起来非常的荒谬,但是,模型中间经过那么多层向量矩阵的运算,目的就是让这最后一个向量包含远超单个词汇本身的信息,也就是将上下文信息包络进来。
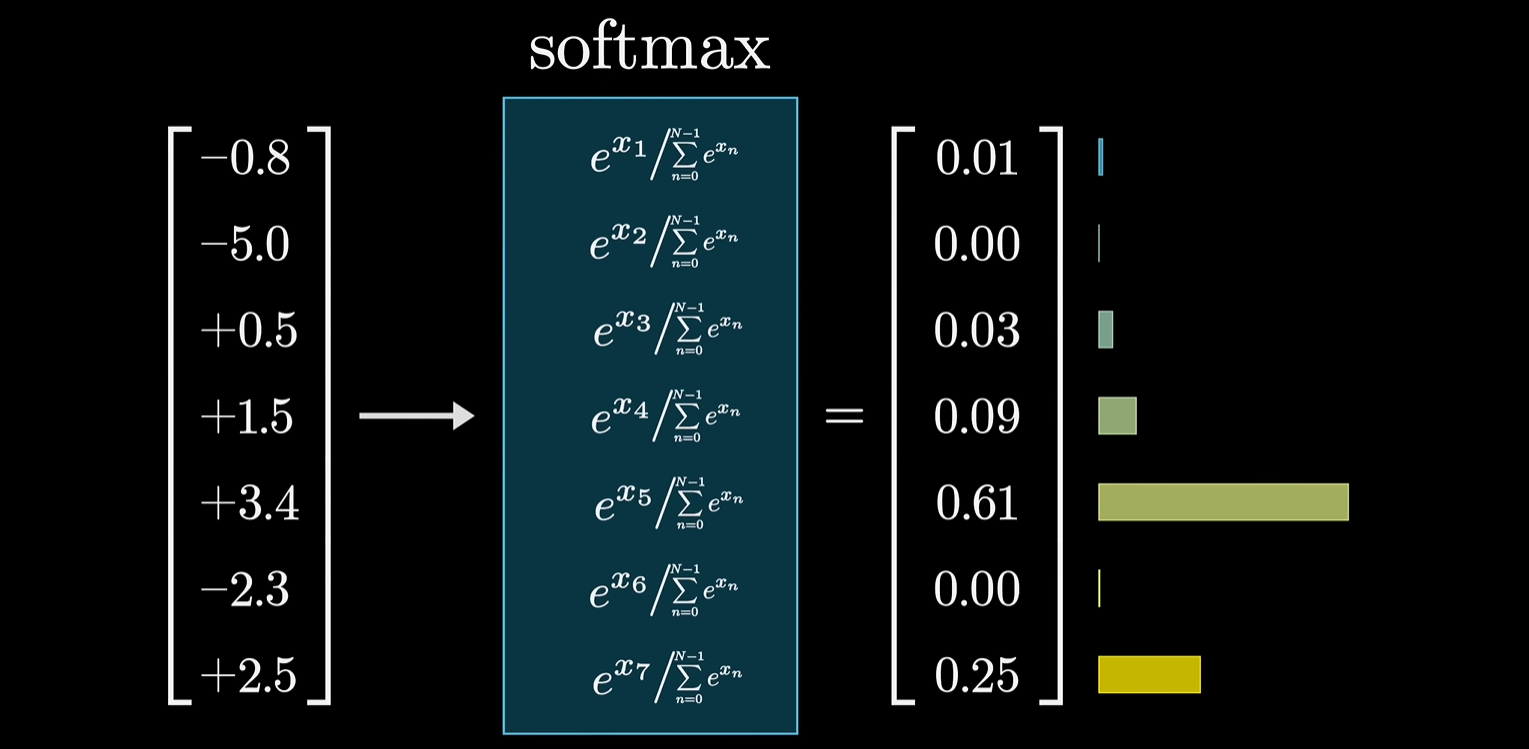
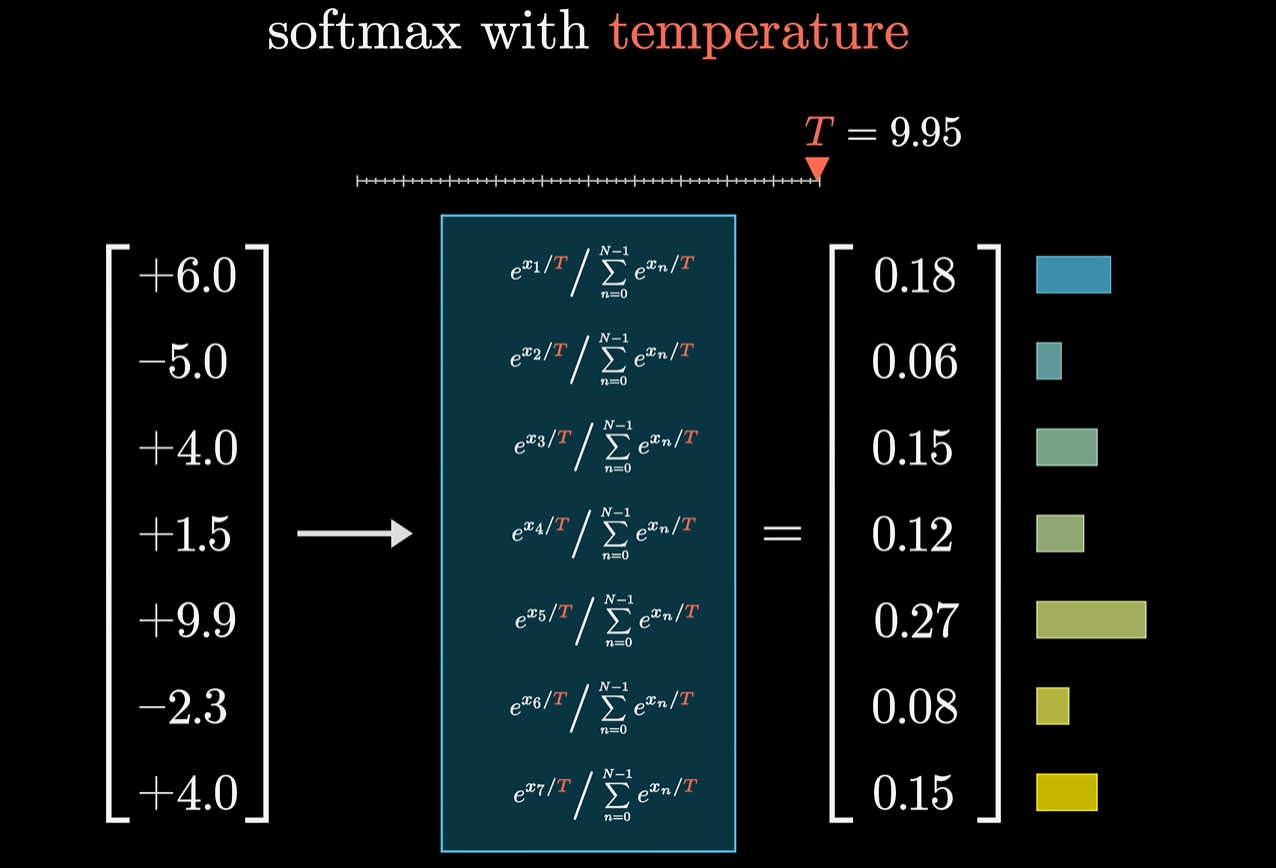
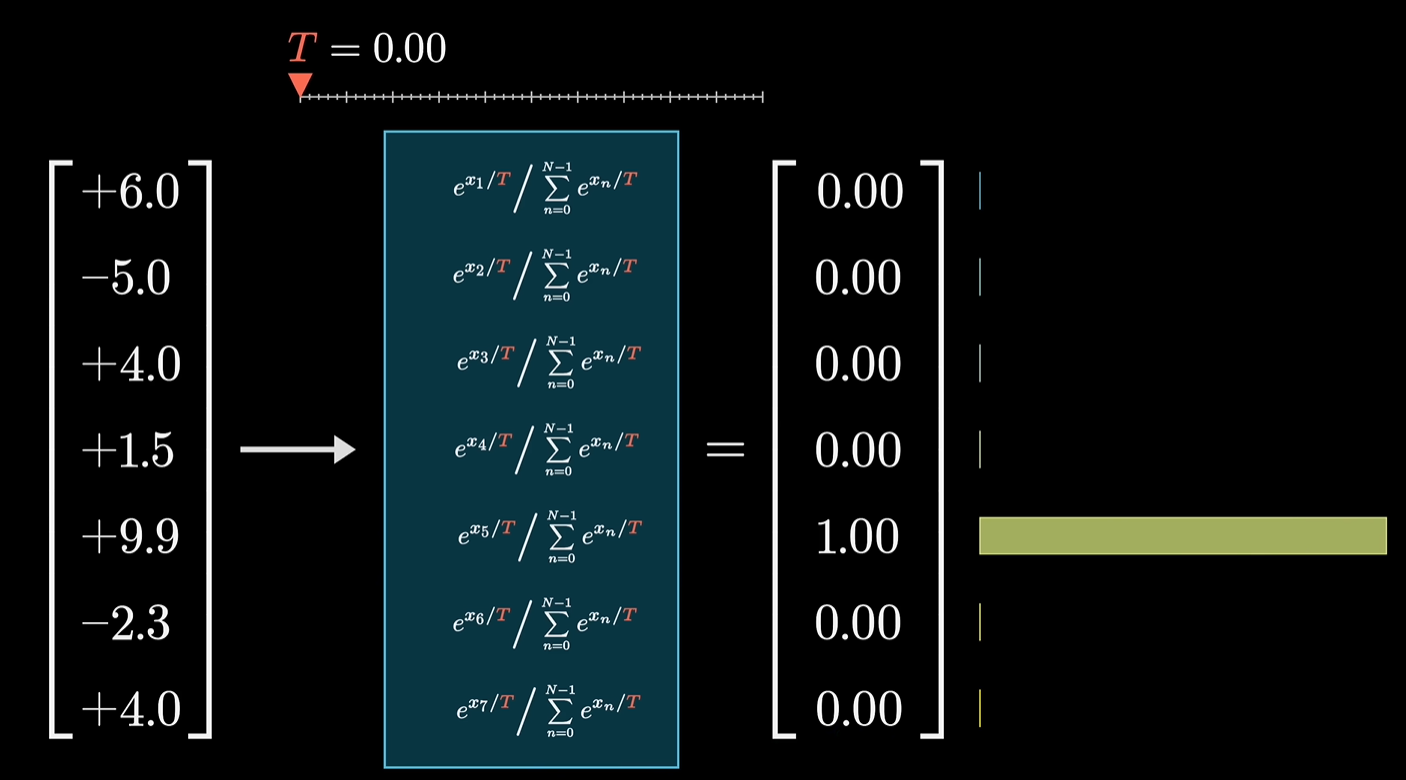
02 语言模型如何产生答案
文字接龙游戏
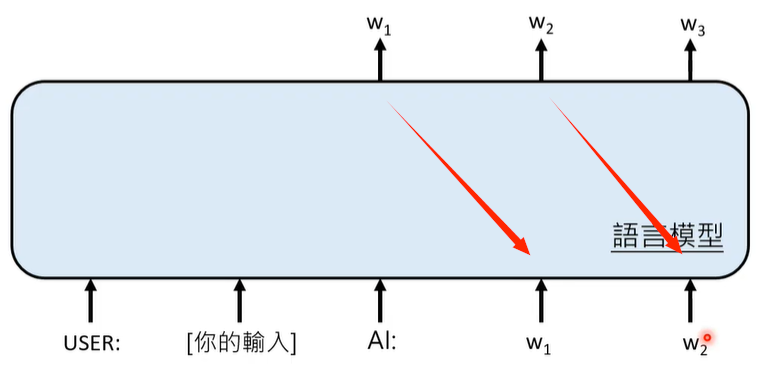
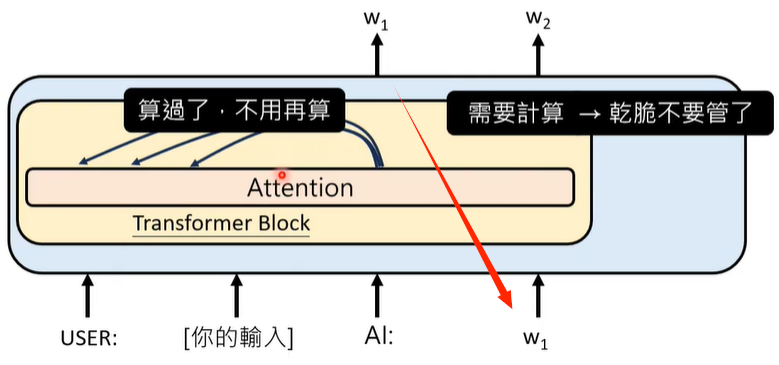
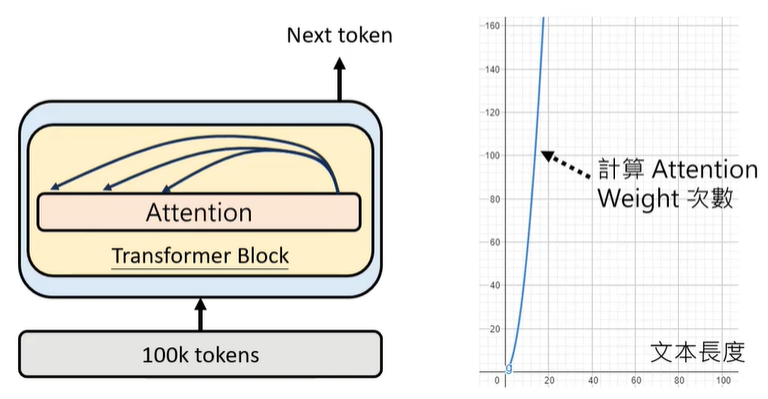
输入超长的文字,对模型来说是困难的挑战,模型计算Attention Weight的次数随用户输入文本长度的增加而指数级增加,因此需要耗费大量的算力。
一些研究方向

03 Transformer 能做什么?
Sequence-to-sequence (Seq2Seq), Input a sequence, output a sequence. And the output length is determined by model.
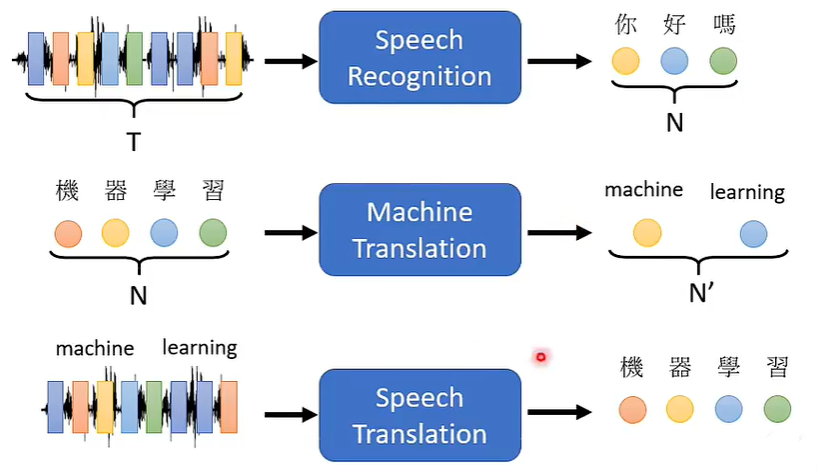
Transformer能做语音识别、机器翻译、语音翻译等等。
04 一些训练资料
① Seq2Seq for Chat
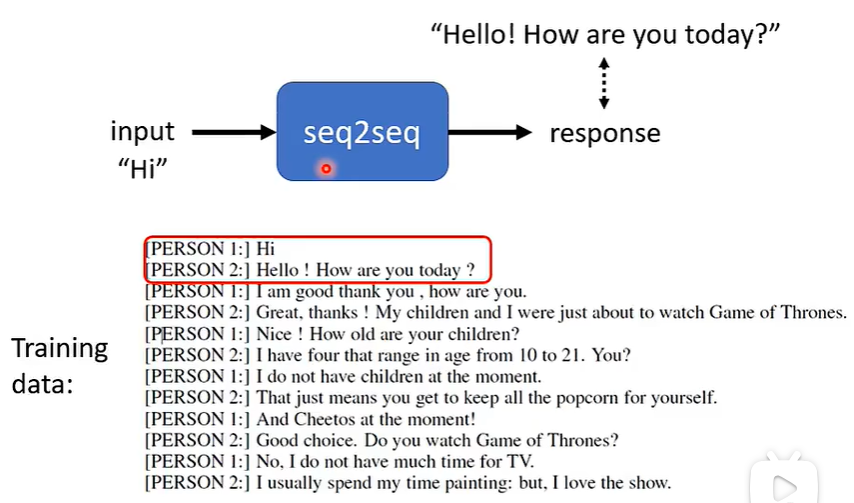
② Question Answering (QA)

QA can be done by seq2seq
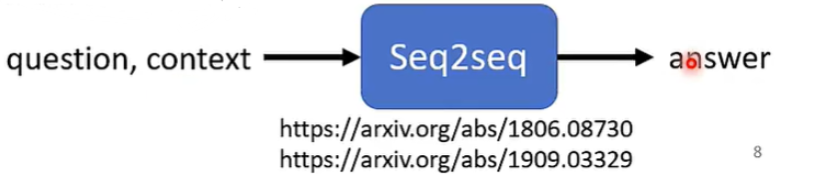
但是,什么问题都用Seq2Seq,不一定会得到优秀的特制化模型,还是要针对性地提供训练材料。
③ 文法剖析
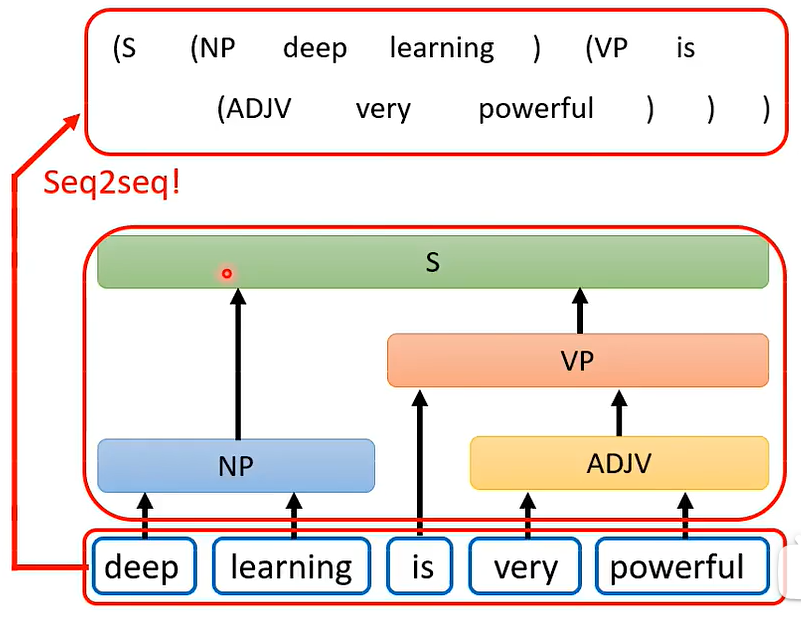
④ Seq2seq for Multi-label Classification 多标签分类

⑤ Seq2seq for Object Detection 目标检测
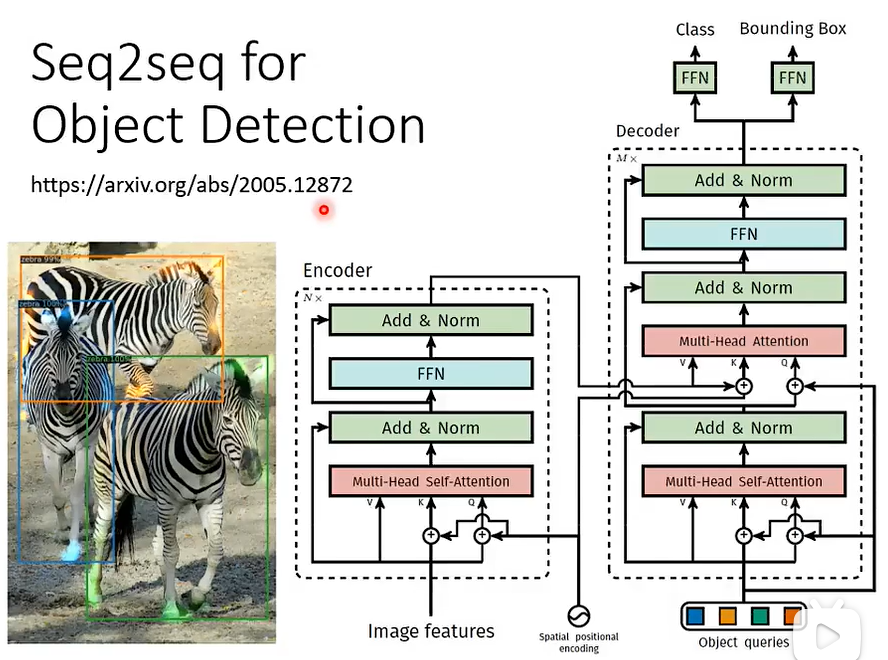
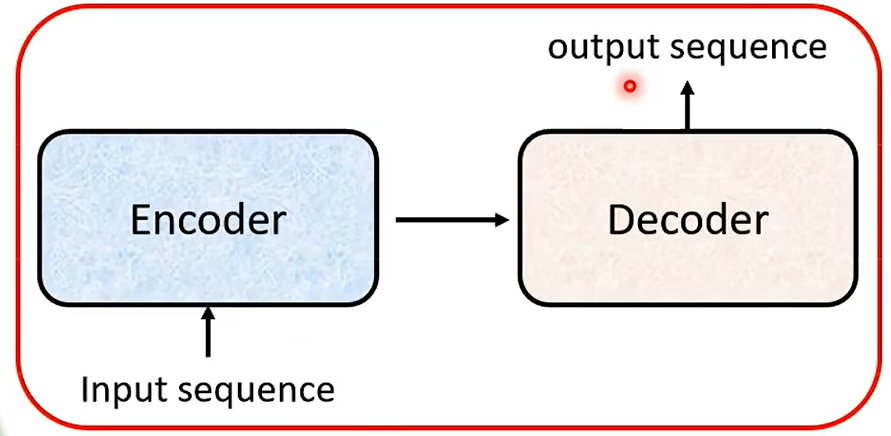
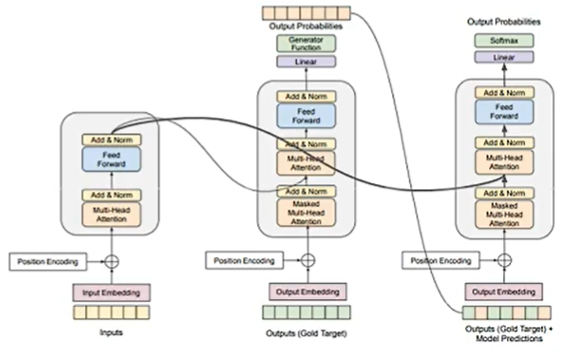
05 Encoder And Decoder
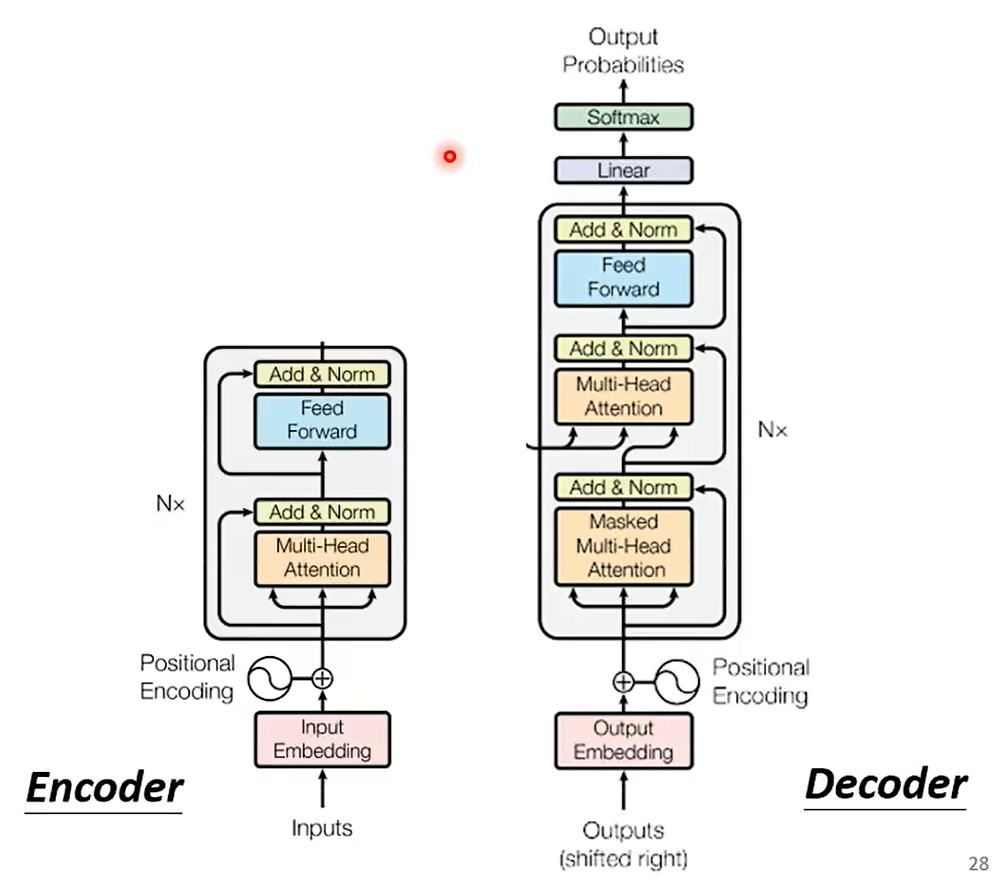
Masked什么意思?

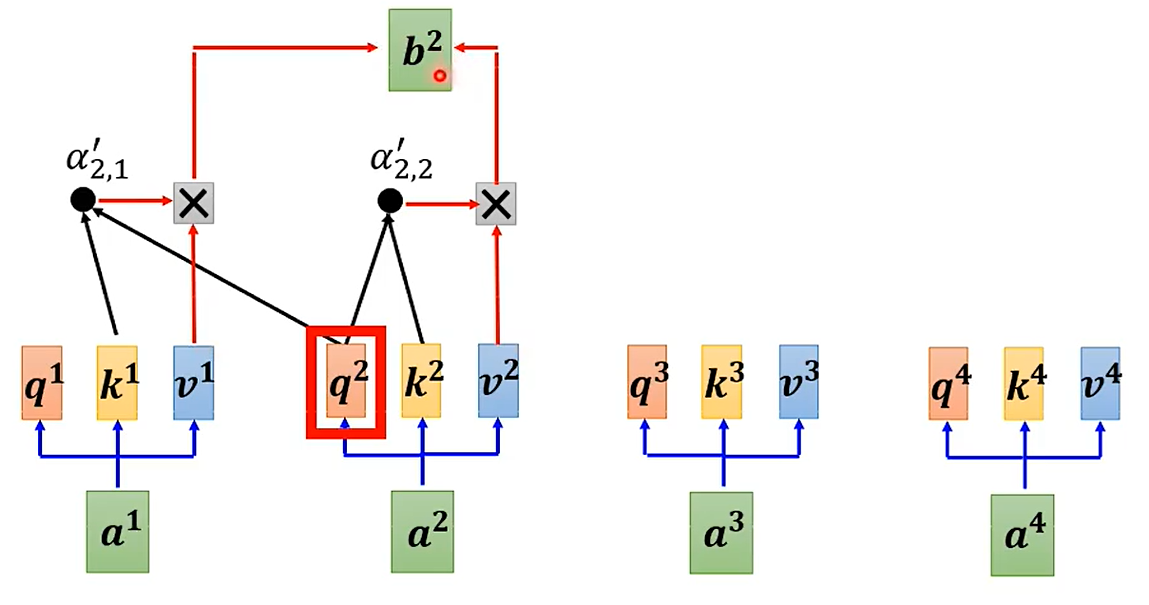
事实上,a1、a2、a3、a4是先后顺序产生的,在利用a2的时候,无法考虑a3、a4,因为这俩还没有产生。
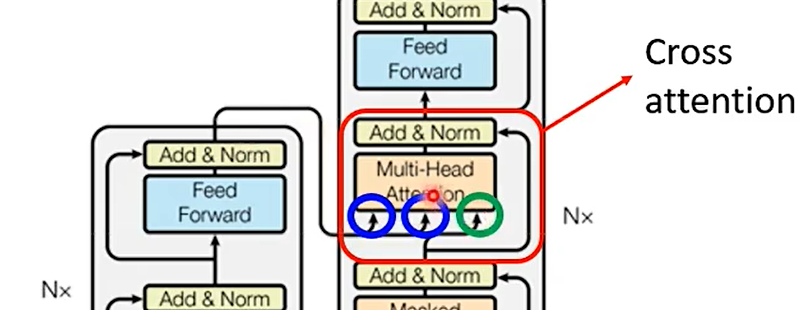
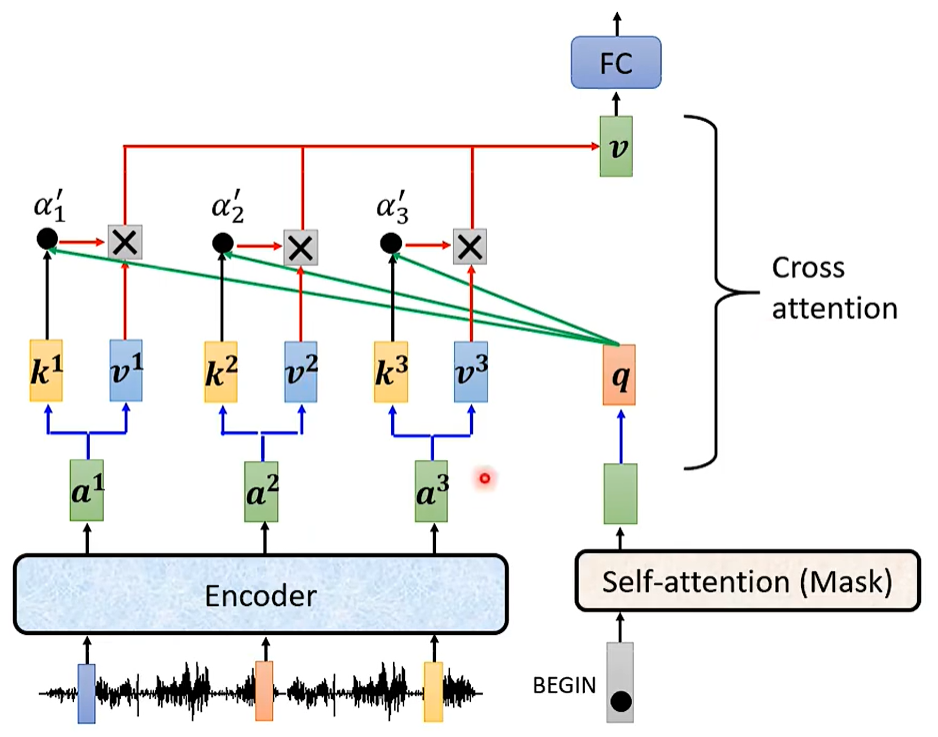
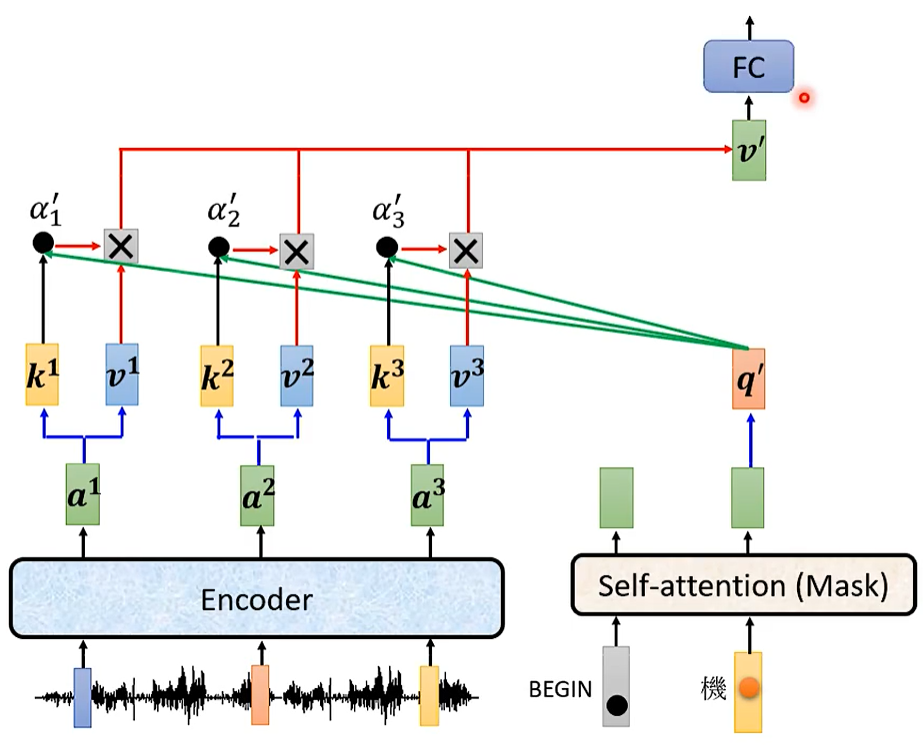
Cross Attention
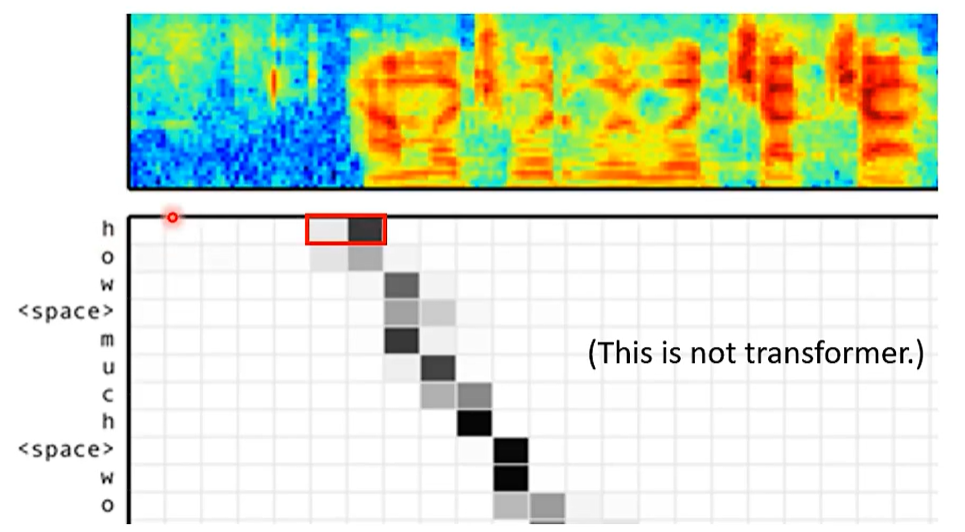
Listen, attend and spell: A neural network for large vocabulary conversational speech recognition.
为什么decoder一定要利用encoder最后的输出呢?
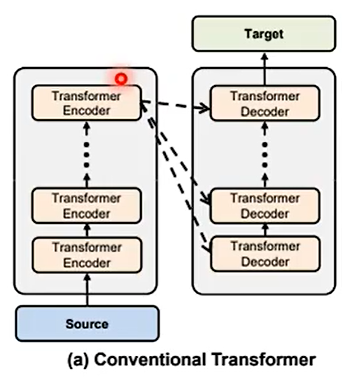
当然可以不,你可以自己做研究,尝试decoder用encoder中间的输出,这也是一个好的研究方向呢!
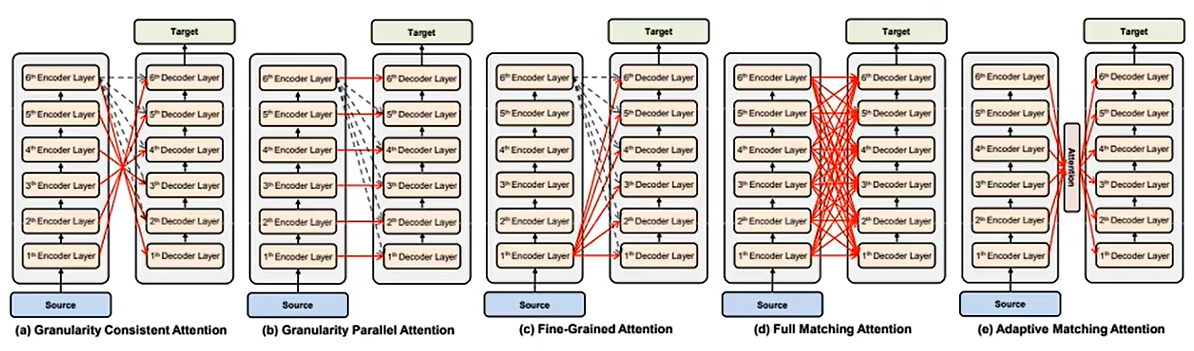
06 Encoder
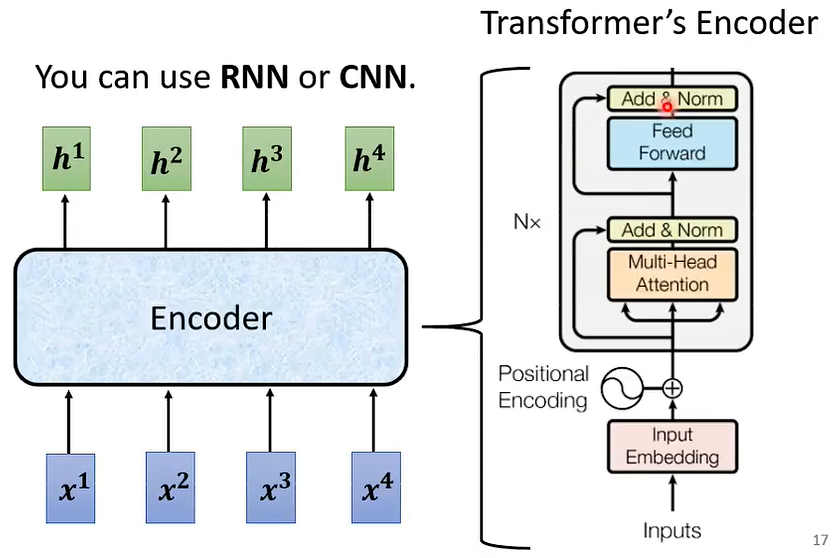
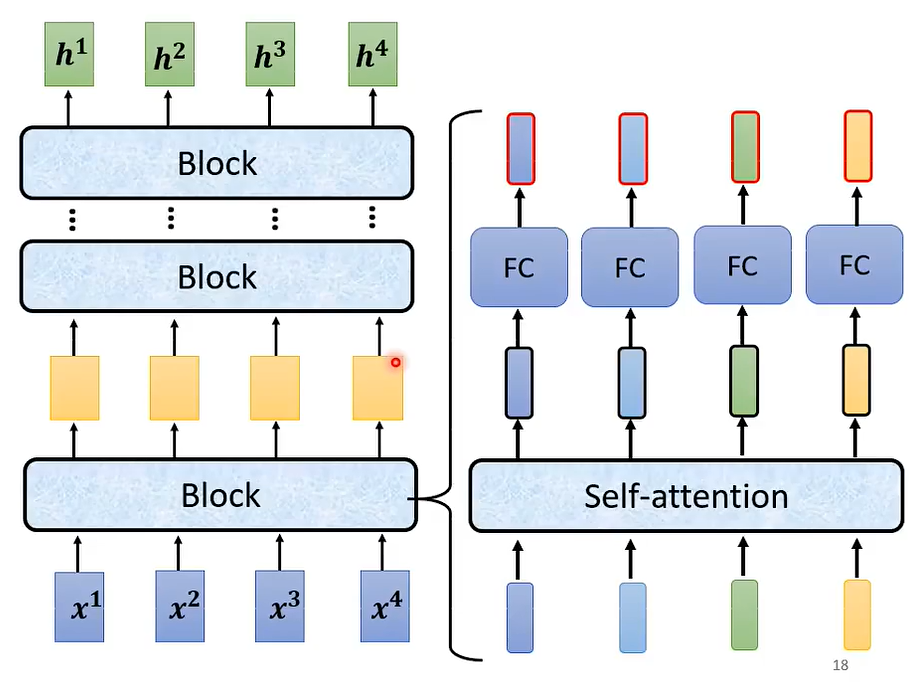
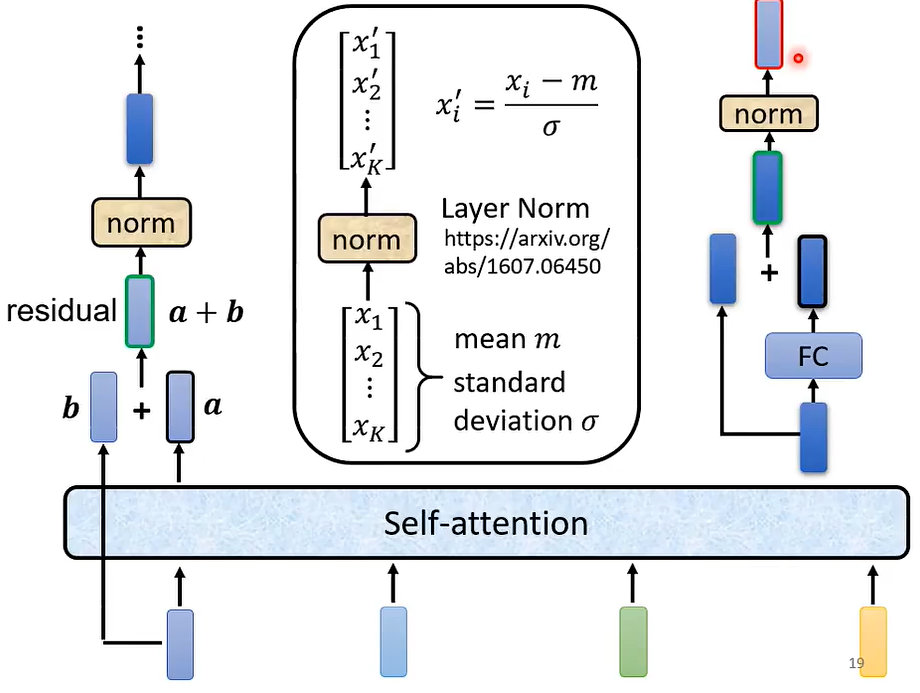
为什么encoder要这样设计呢?
当然可以别样设计,只要效果有所进步,我们可以不断尝试新的架构,新的方案。
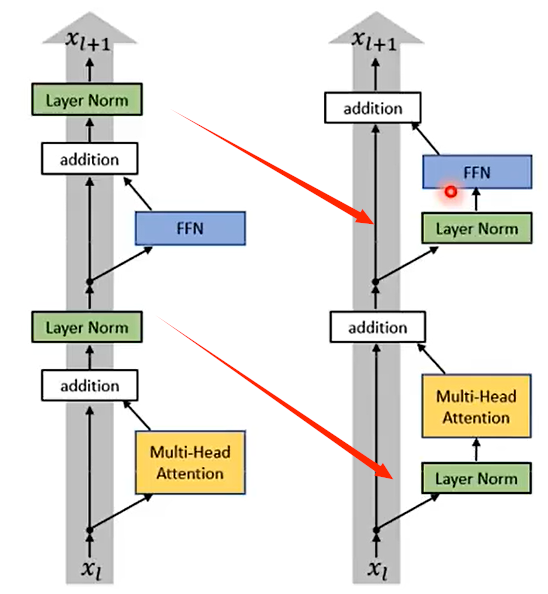
07 Decoder
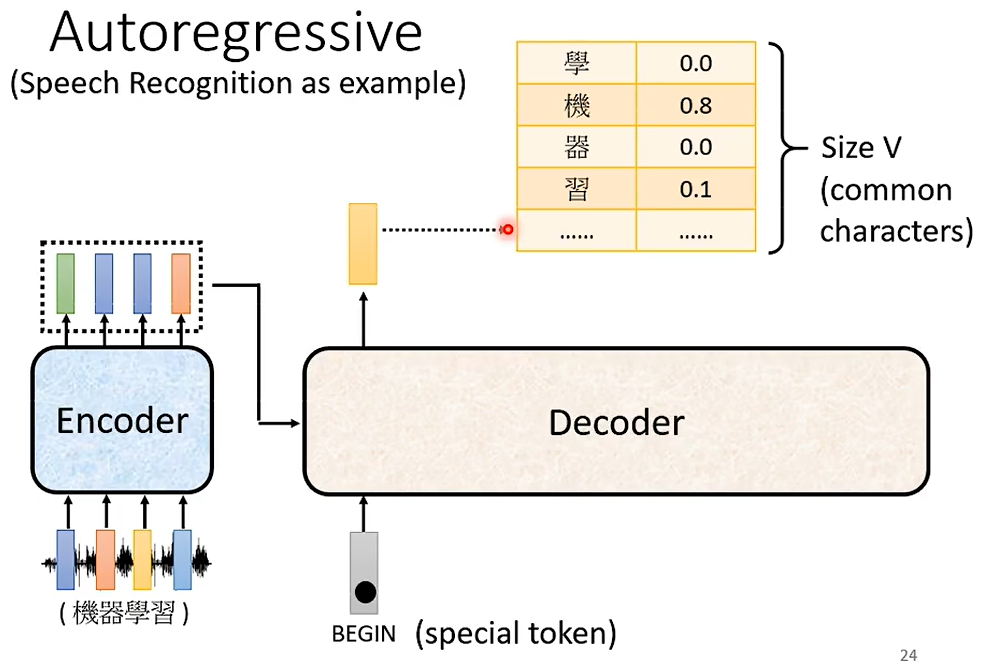
Speech Recognition as example 自回归
先想好token的单位是什么,decoder输出的向量长度是跟你穷举 的单位数量长度是一样的,分数最高的单位作为输出,当自己的输出当作自己的输入,如此反复迭代。
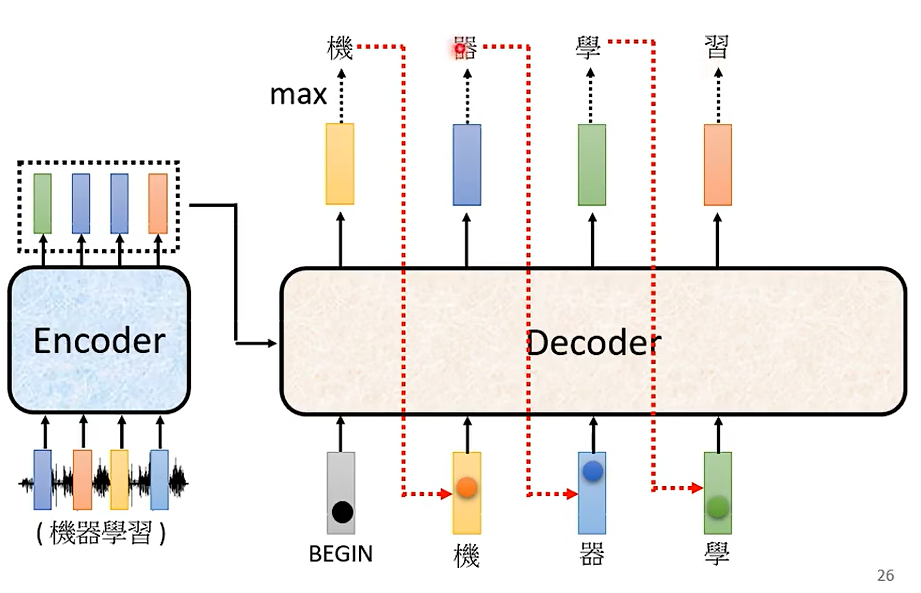
我们如何才能让Decoder停下来呢,需要引入一个“断”这个符号,也就是END,END的几率在最后的哪个向量里几率是最大的。
08 Decoder-Non-Autoregressive(NAT) 非自回归
AT v.s.NAT
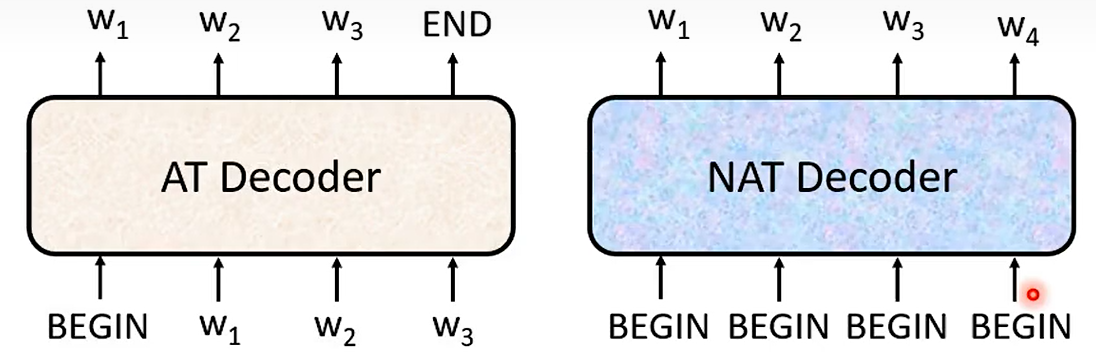
How to decide the output length for NAT decoder?
- Another predictor for output length
- Output a very long sequence, ignore tokens after END
Advantage: parallel, controllable output length
NAT is usually worse than AT(why?Multi-modality 多模态)
09 Training
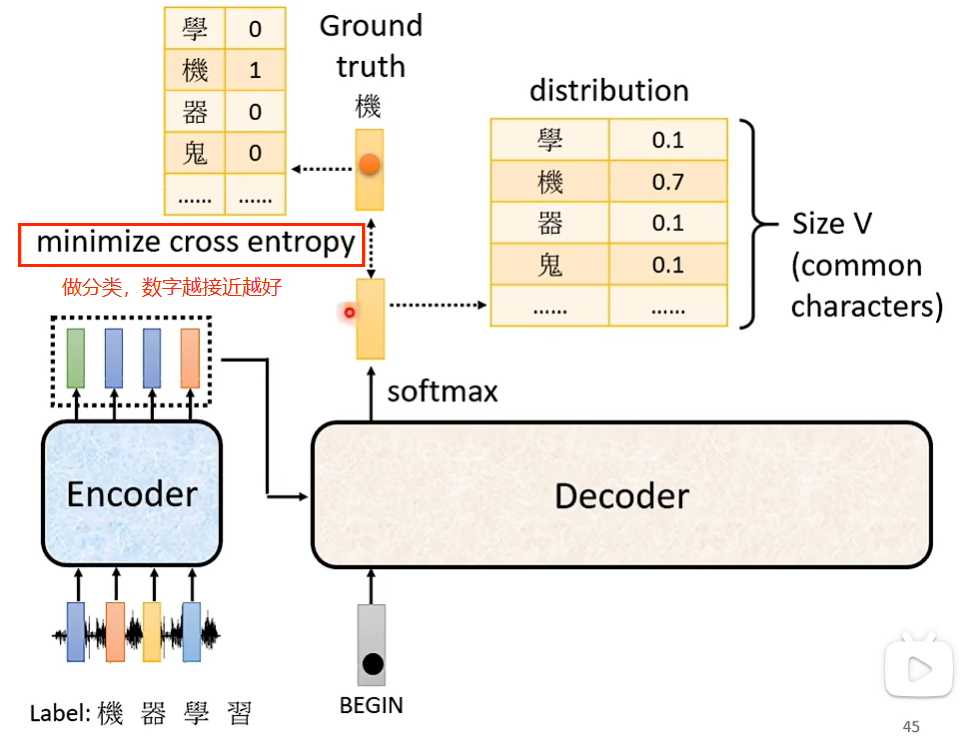
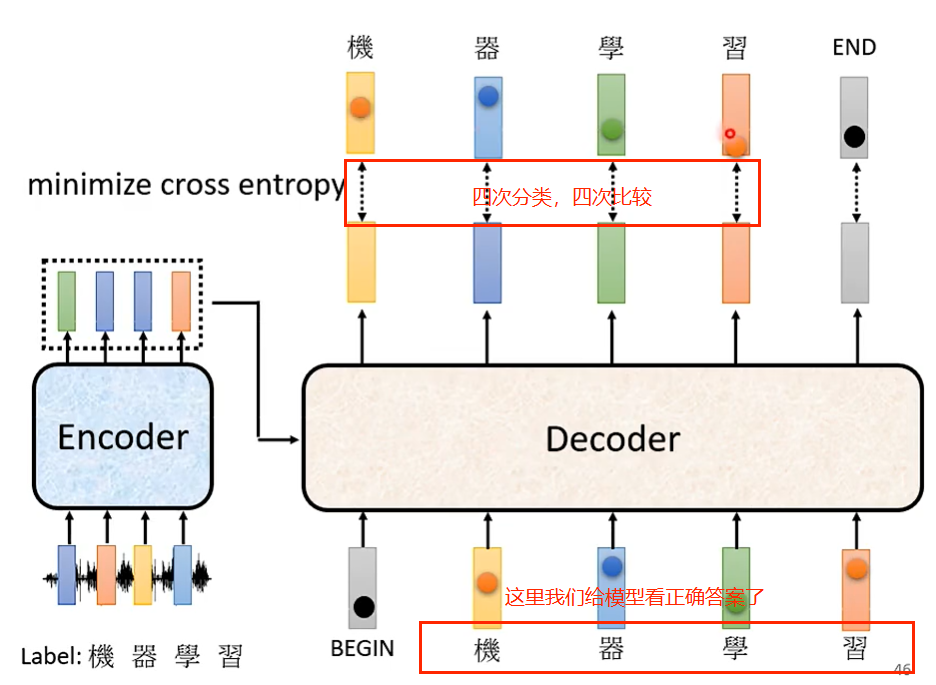
cross-entropy 交叉熵
exposure bias 曝光偏差
ground truth 地面实况
Teacher Forcing: using the ground truth as input.
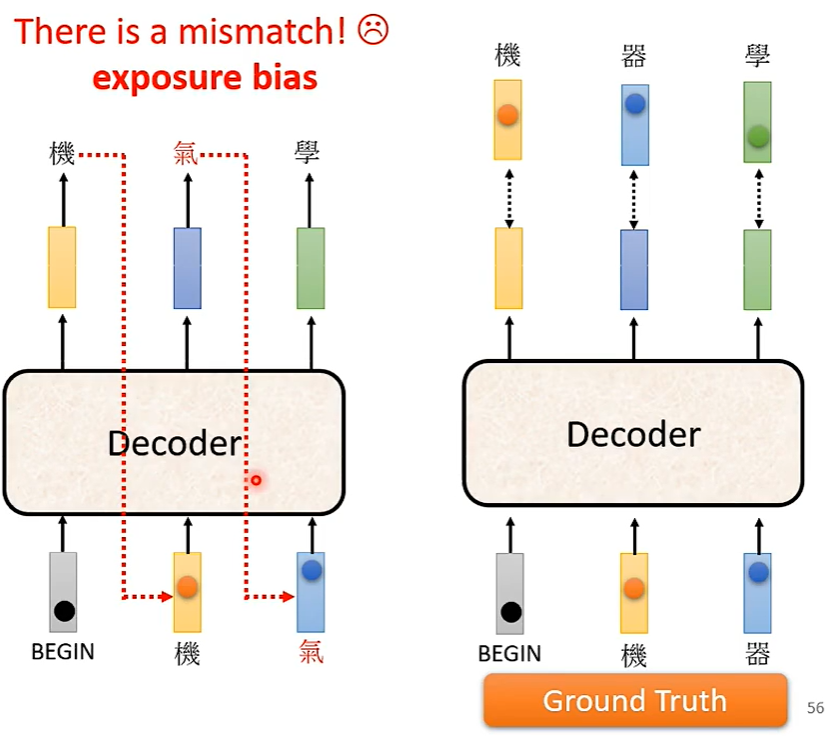
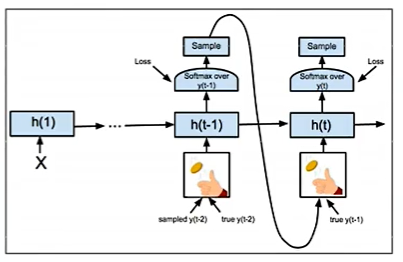
大模型在训练的时候看的是正确答案,那么在测试时,没有正确答案,可能会造成一步错步步错。如何解决呢,我们可以在训练的时候看一些错误答案,它在测试时可能会表现更好,这个招数叫做 Scheduled Sampling.
10 Tips
① Chat-bot

② Summarization
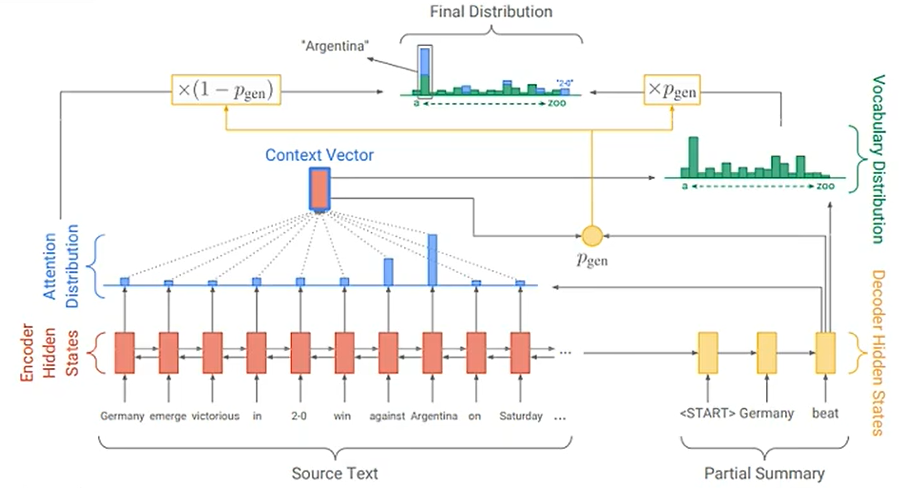
我们可以通过训练大量的文章,获取模型复述句子或词组的能力,从而帮助我们有效回答和撰写摘要。
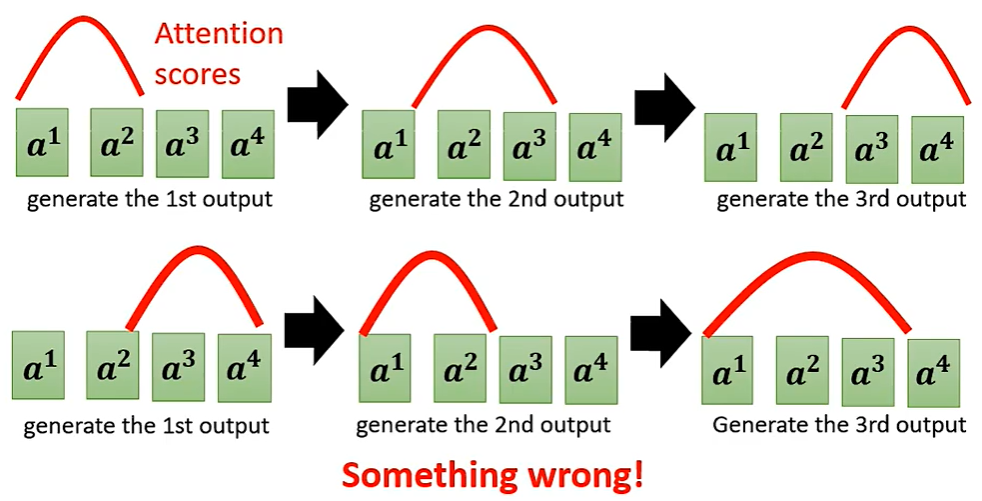
③ Guided Attention
TTS as example
In some tasks, input and output are monotonically aligned 单调对齐. For example, speech recognition,TTS,etc.
④ Beam Search
束搜索:一种启发式搜索算法,通过扩展有限集合中最有前途的节点来探索图形。
Assume here are only two tokens.(V = 2)
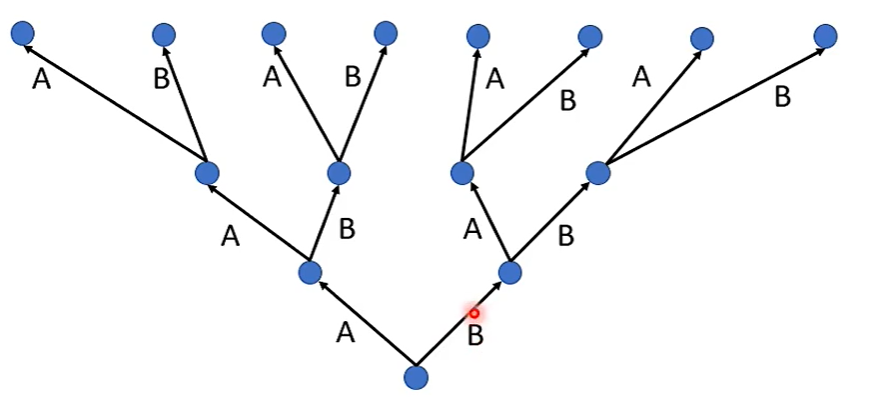
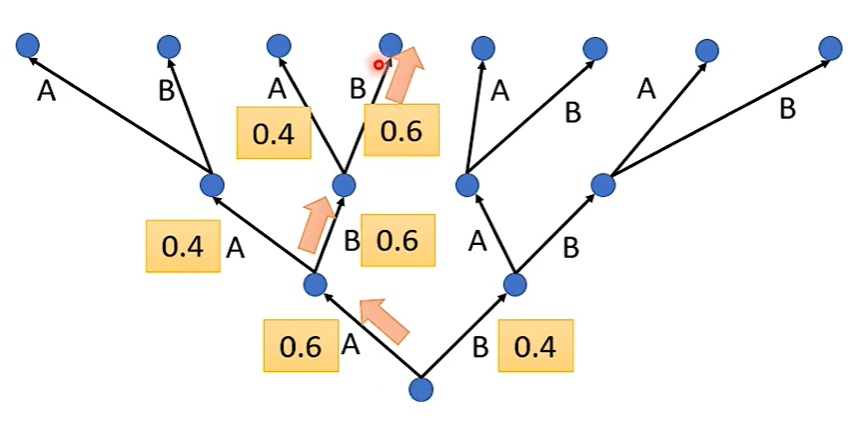
The red path is Greedy Decoding. 贪婪的解码
局部最优解和全局最优解之间的博弈。
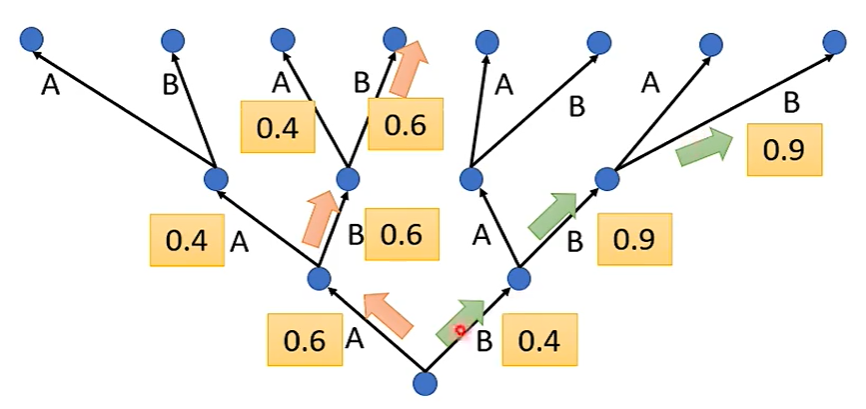
The green path is the best one.
也有人说,Beam Search 是很烂的东西,其可能会输出重复的话,此时,需要加入随机性的因素,找出所谓的全局最优解。

Randomness is needed for decoder when generating sequence in some tasks (e.g. , sentence completion, TTS)
Accept that nothing is perfect. True beauty lies in the cracks of imperfection.
⑤ Optimizing Evaluation Metrics 评测指标?
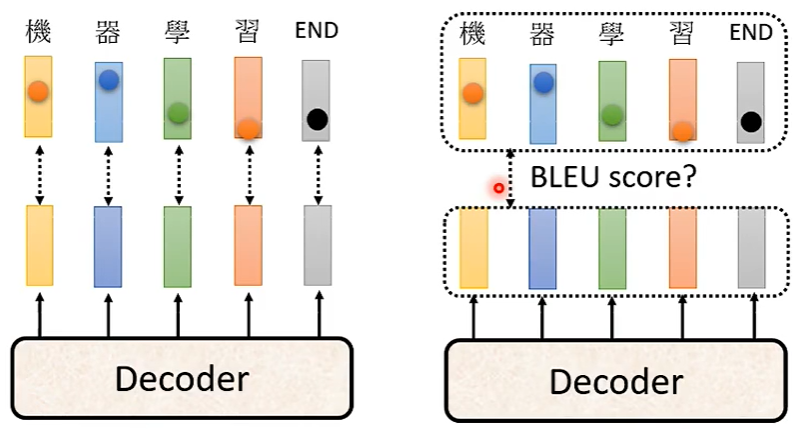
Lose 就是 Blue Score 加一个负号,When you don’t know how to optimize, just use reinforcement learning (RL) !

















 6204
6204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









