



续接:https://blog.youkuaiyun.com/lanfeng_x/article/details/154123754?spm=1001.2014.3001.5501
源码获取:https://github.com/oybk8/OCR
2.1带UI的中文OCR识别
import cv2
import pytesseract
import tkinter as tk
from tkinter import filedialog, scrolledtext
import os,sys
def resource_path(p):
# 若程序是打包后的exe,sys._MEIPASS指向运行时的临时根目录;否则用当前脚本目录
base = getattr(sys, "_MEIPASS", os.path.dirname(os.path.abspath(__file__)))
return os.path.join(base, p) # 拼接资源路径
pytesseract.pytesseract.tesseract_cmd = resource_path('tesseract.exe')
# pytesseract.pytesseract.tesseract_cmd = 'C:\\Program Files\\Tesseract-OCR\\tesseract.exe'
try:
from tkinterdnd2 import DND_FILES, TkinterDnD
TKDND_AVAILABLE = True
except ImportError:
TKDND_AVAILABLE = False
print("警告: tkinterdnd2 未安装,拖拽功能将不可用")
print("请安装: pip install tkinterdnd2")
class OCRApp:
def __init__(self, root):
self.root = root
self.root.title("中文OCR识别工具")
self.root.geometry("1000x600")
# 创建左右分栏
self.left_frame = tk.Frame(root, width=500, height=600, bd=2, relief=tk.SUNKEN)
self.right_frame = tk.Frame(root, width=500, height=600, bd=2, relief=tk.SUNKEN)
self.left_frame.pack(side=tk.LEFT, fill=tk.BOTH, expand=True, padx=5, pady=5)
self.right_frame.pack(side=tk.RIGHT, fill=tk.BOTH, expand=True, padx=5, pady=5)
# 左侧:图片显示与操作区
self.left_title = tk.Label(
self.left_frame,
text="拖拽图片到下方区域或点击选择",
font=("微软雅黑", 12)
)
self.left_title.pack(pady=10)
# 图片显示区域
self.image_label = tk.Label(
self.left_frame,
bg="#f0f0f0",
bd=1,
relief=tk.SOLID,
text="请拖拽图片到此处或使用选择按钮",
wraplength=400
)
self.image_label.pack(fill=tk.BOTH, expand=True, padx=10, pady=10)
# 初始化拖拽功能(如果可用)
if TKDND_AVAILABLE:
self.setup_drag_drop()
else:
self.image_label.config(text="拖拽功能不可用\n请使用选择图片按钮")
# 按钮框架
self.button_frame = tk.Frame(self.left_frame)
self.button_frame.pack(pady=10)
self.select_btn = tk.Button(
self.button_frame,
text="选择图片",
command=self.select_image,
font=("微软雅黑", 10),
width=12,
height=1
)
self.select_btn.pack(side=tk.LEFT, padx=5)
self.clear_btn = tk.Button(
self.button_frame,
text="清空结果",
command=self.clear_results,
font=("微软雅黑", 10),
width=12,
height=1
)
self.clear_btn.pack(side=tk.LEFT, padx=5)
# 右侧:识别结果区
self.right_title = tk.Label(
self.right_frame,
text="识别结果",
font=("微软雅黑", 12)
)
self.right_title.pack(pady=10)
self.result_text = scrolledtext.ScrolledText(
self.right_frame,
font=("微软雅黑", 10),
wrap=tk.WORD
)
self.result_text.pack(fill=tk.BOTH, expand=True, padx=10, pady=10)
# 状态栏
self.status_var = tk.StringVar()
self.status_var.set("就绪")
self.status_bar = tk.Label(
root,
textvariable=self.status_var,
relief=tk.SUNKEN,
anchor=tk.W
)
self.status_bar.pack(side=tk.BOTTOM, fill=tk.X)
self.current_image = None
def setup_drag_drop(self):
"""设置拖拽功能"""
try:
# 新版 tkinterdnd2 使用方法
self.root.drop_target_register(DND_FILES)
self.root.dnd_bind('<<Drop>>', self.on_drop)
# 同时为图片标签设置拖拽
self.image_label.drop_target_register(DND_FILES)
self.image_label.dnd_bind('<<Drop>>', self.on_drop)
except Exception as e:
print(f"拖拽功能初始化失败: {e}")
self.status_var.set("拖拽功能初始化失败")
def on_drop(self, event):
"""处理拖拽事件"""
if not TKDND_AVAILABLE:
return
try:
# 处理不同版本的拖拽数据格式
if hasattr(event, 'data'):
file_path = event.data
else:
file_path = event.data
# 清理文件路径(去除花括号等)
file_path = file_path.strip('{}').replace('\\', '/')
# 支持多个文件,只处理第一个
if '\n' in file_path:
file_path = file_path.split('\n')[0]
self.status_var.set(f"处理文件: {os.path.basename(file_path)}")
self.process_image(file_path)
except Exception as e:
error_msg = f"拖拽失败:{str(e)}"
self.result_text.delete(1.0, tk.END)
self.result_text.insert(tk.END, error_msg)
self.status_var.set("处理失败")
def select_image(self):
"""文件选择按钮"""
file_path = filedialog.askopenfilename(
title="选择图片",
filetypes=[
("图片文件", "*.png *.jpg *.jpeg *.bmp *.tiff"),
("所有文件", "*.*")
]
)
if file_path:
self.status_var.set(f"处理文件: {os.path.basename(file_path)}")
self.process_image(file_path)
def clear_results(self):
"""清空结果"""
self.result_text.delete(1.0, tk.END)
self.image_label.config(image='', text="请拖拽图片到此处或使用选择按钮")
if hasattr(self.image_label, 'image'):
self.image_label.image = None
self.status_var.set("已清空")
def process_image(self, file_path):
"""图片处理与OCR识别"""
try:
# 验证文件存在
if not os.path.isfile(file_path):
raise Exception("文件不存在")
# 验证文件格式
valid_extensions = ('.png', '.jpg', '.jpeg', '.bmp', '.tiff')
if not file_path.lower().endswith(valid_extensions):
raise Exception(f"不支持的图片格式,支持: {', '.join(valid_extensions)}")
# 读取图片
cv_img = cv2.imread(file_path)
if cv_img is None:
raise Exception("无法读取图片,请检查文件是否损坏")
# 预处理图片
rgb_img = cv2.cvtColor(cv_img, cv2.COLOR_BGR2RGB)
gray = cv2.cvtColor(rgb_img, cv2.COLOR_RGB2GRAY)
# 可选:图像增强
# gray = cv2.medianBlur(gray, 3) # 中值滤波去噪
# 缩放图片用于显示
display_img = self.resize_image_for_display(gray, max_width=450, max_height=500)
# 转换为Tkinter格式并显示
tk_img = self.cv2_to_tkinter(display_img)
self.image_label.config(image=tk_img, text="")
self.image_label.image = tk_img
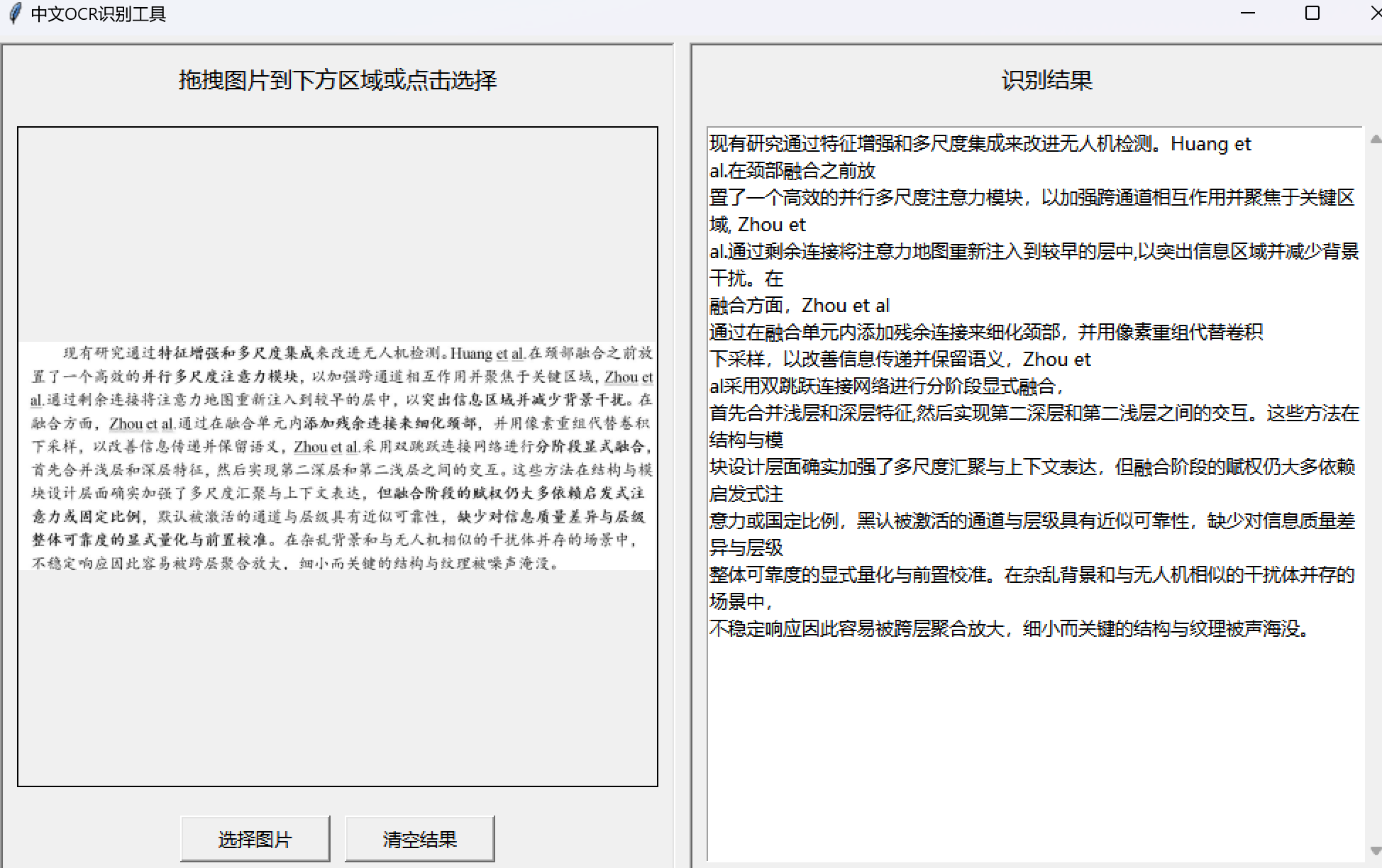
# OCR识别
self.status_var.set("正在识别文字...")
self.root.update()
# 使用中文识别
langs = {
'chi_sim': '简体中文',
'eng': '英文'
}
combined_lang = '+'.join(langs.keys())
# custom_config = r'--oem 3 --psm 6 -c tessedit_char_whitelist=0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz.,!?;:()[]{}@#$%^&*+-/=<>|\\_~`\"\' 中文'
text = pytesseract.image_to_string(
gray,
# config=testdata_dir_config,
lang=combined_lang,
)
# 显示结果
self.result_text.delete(1.0, tk.END)
if text.strip():
self.result_text.insert(tk.END, text)
self.status_var.set(f"识别完成 - 共 {len(text)} 字符")
else:
self.result_text.insert(tk.END, "未识别到文本")
self.status_var.set("未识别到文本")
except Exception as e:
error_msg = f"处理失败:{str(e)}"
self.result_text.delete(1.0, tk.END)
self.result_text.insert(tk.END, error_msg)
self.status_var.set("处理失败")
print(f"错误详情: {e}")
def resize_image_for_display(self, image, max_width=450, max_height=500):
"""调整图片大小用于显示"""
h, w = image.shape[:2]
# 计算缩放比例
scale = min(max_width / w, max_height / h, 1.0) # 不超过原图大小
if scale < 1.0:
new_width = int(w * scale)
new_height = int(h * scale)
resized = cv2.resize(image, (new_width, new_height), interpolation=cv2.INTER_AREA)
return resized
else:
return image
def cv2_to_tkinter(self, cv_image):
"""将OpenCV图像转换为Tkinter PhotoImage"""
# 确保是RGB格式
if len(cv_image.shape) == 3 and cv_image.shape[2] == 3:
rgb_image = cv_image
else:
rgb_image = cv2.cvtColor(cv_image, cv2.COLOR_BGR2RGB)
# 转换为PhotoImage
h, w = rgb_image.shape[:2]
photo = tk.PhotoImage(width=w, height=h)
# 逐像素设置(对于大图片可能较慢,但兼容性更好)
data = f"P6 {w} {h} 255 ".encode() + rgb_image.tobytes()
photo.put(data, (0, 0, w-1, h-1))
return photo
def main():
"""主函数"""
try:
if TKDND_AVAILABLE:
root = TkinterDnD.Tk() # 支持拖拽的窗口
else:
root = tk.Tk() # 普通窗口
app = OCRApp(root)
root.mainloop()
except Exception as e:
print(f"程序启动失败: {e}")
if sys.stdin and sys.stdin.isatty():
try: input("按回车键退出...")
except EOFError: pass
if __name__ == "__main__":
main()2.2 安装依赖pyinstaller,打包
pip install pyinstaller
pyinstaller -F -w .\OCR.py --additional-hooks-dir hooks --add-binary "C:\Program Files\Tesseract-OCR\*;." --add-data "C:\Program Files\Tesseract-OCR\tessdata;tessdata"
2.3迁移到新环境上部署运行
上述完成之后,直接运行OCR.exe即可


















 2030
2030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









