






关于使用DMA提高SPI传输速率
笔者最近在做用SPI接口来与一块TFTLCD显示屏通信,发现使用SPI刷屏的速度肉眼可见,然后通过分析上网查阅最后做到了一些提速。
一、SPI通信
-
关于原理这里就不过多赘述了,这位博主写的十分详细,大家可以参考。
单片机外设篇——SPI协议我这里直接附一份代码:
void spi_init(void)
{
SPI_DMA_Config();
SPI_InitTypeDef SPI_InitStructure;
/* 使能SPI 时钟 */
RCC_APB1PeriphClockCmd(LCD_RCC_APBPeriph_SPI ,ENABLE);
/* SPI配置 */
SPI_InitStructure.SPI_Direction = SPI_Direction_2Lines_FullDuplex;
SPI_InitStructure.SPI_Mode = SPI_Mode_Master;
SPI_InitStructure.SPI_DataSize = SPI_DataSize_8b;
SPI_InitStructure.SPI_CPOL = SPI_CPOL_High;
SPI_InitStructure.SPI_CPHA = SPI_CPHA_2Edge;
SPI_InitStructure.SPI_NSS = SPI_NSS_Soft;
SPI_InitStructure.SPI_BaudRatePrescaler = SPI_BaudRatePrescaler_2;
SPI_InitStructure.SPI_FirstBit = SPI_FirstBit_MSB;
SPI_InitStructure.SPI_CRCPolynomial = 7;
SPI_Init(LCD_SPI, &SPI_InitStructure);
SPI2->CR2 |= 1<<1 ; //发送缓冲区DMA使能
SPI2->CR2 |= 1<<0 ; //接收缓冲区DMA使能
/* 使能SPI */
SPI_Cmd(LCD_SPI, ENABLE);
SPI_CS(0); //禁止片选
}
二、SPI时钟
- SPI2挂载在APB1上,所以它的输入频率最高就是APB1的频率为36MHz,再有SPI分频器最小分频2分频得到输出频率为18MHz,通常SPI配置为8位传输,因此传输一个字节的频率应该在2.25MHz左右,这一点通过示波器也可以验证,如下图:
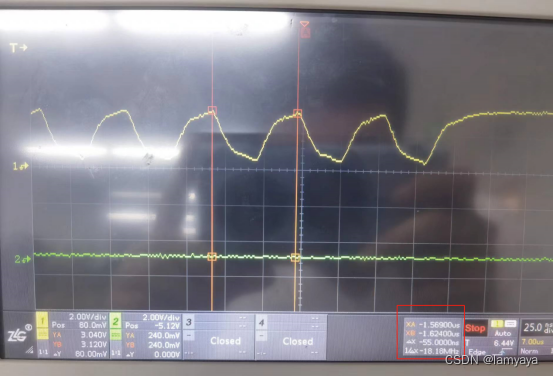
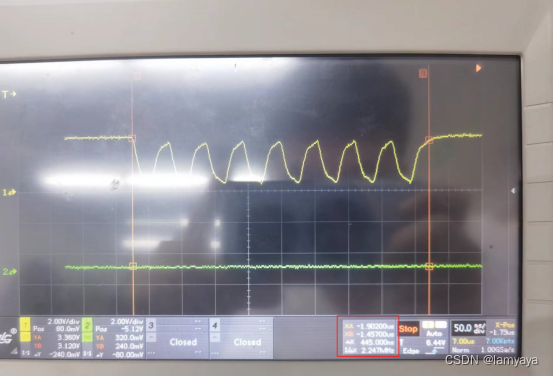
- 这里可以看到每一位传输的频约在18MHz,传输一个字节的频率在2.25MHz
- 这里也参考了一位博主针对SPI时钟的分析:
STM32硬件SPI时钟频率与时钟解析(基于逻辑分析仪的抓包试验)
三、传输速率较慢问题分析
- 从示波器来看,SPI时钟是没有问题的那么问题在哪里?
从示波器上传输两个字节的波形来看,会发现SPI每传输完一个字节就要等待一段时间,且这段时间约为传输时间的十倍。结合代码可以看出,我们的时间都浪费在等待标志位上了。
while(SPI_I2S_GetFlagStatus(LCD_SPI, SPI_I2S_FLAG_TXE) == RESET);
/* Send byte through the SPI2 peripheral */
SPI_I2S_SendData(LCD_SPI, byte);
/* Wait to receive a byte */
while(SPI_I2S_GetFlagStatus(LCD_SPI, SPI_I2S_FLAG_RXNE) == RESET);
/* Return the byte read from the SPI bus */
return SPI_I2S_ReceiveData(LCD_SPI);
- 在SPI每发送完一个字节后,CPU总线都要进入等待,等待SPI发送缓冲区为空的标志位,同样接受的时候也要等待(如果只是单工只发可以不用等待收),但这个等待的过程必须有,不然无法进行传输的。
四、问题解决
- 上网找了一下发现,使用SPI+DMA可以提高传输速度,简单介绍一下DMA:直接存储器存取(DMA)用来提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。无须CPU干预,数据可以通过DMA快速地移动,这就节省了CPU的资源来做其他操作。
- 两个DMA控制器有12个通道(DMA1有7个通道, DMA2有5个通道),每个通道专门用来管理来自于一个或多个外设对存储器访问的请求。还有一个仲裁器来协调各个DMA请求的优先权。
- 这里我们的SPI2用到了DMA1的通道4(SPI_RX)和通道5(SPI_TX),将DMA加入之后发现等待时间降低了不到一半,说明DMA确实还是有用的:
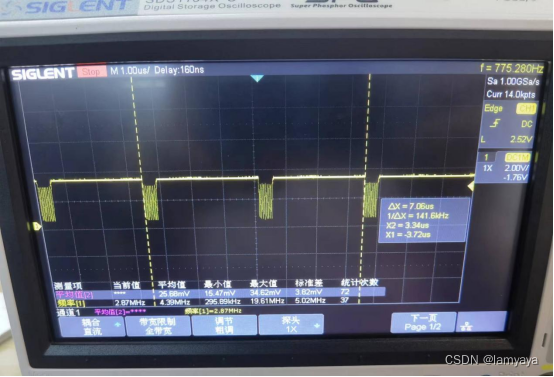
- 到这里并没有结束,在此基础上,如果我们将SPI配置为单工只发的模式,同样DMA也可以只配置DMA1_Channel5,在此基础上还可以进一步缩短传输时间:
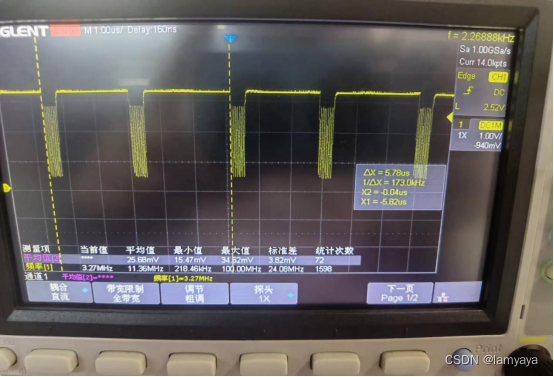
- 至此还有优化的空间吗?
是的,我们的DMA发送同样使用查询来判断是否发送完成,这里我们可以配置为中断清除标志位,结果如下:
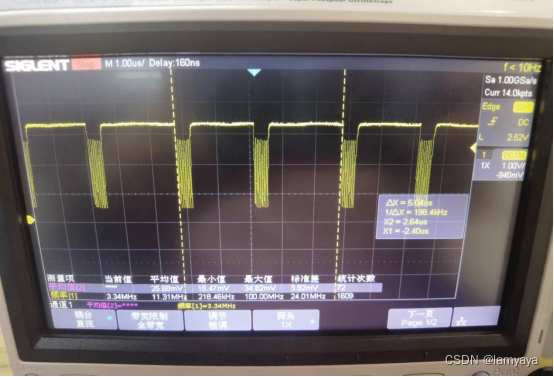
- 虽然在一个像素点(两个字节)上只提升了0.8us,但体现在刷屏上就可以提升61ms。至此针对SPI传输速率的优化就完成了,目前刷屏时间在387ms。这里附一下配置DMA及中断的代码
/* 配置中断源:DMA1_Channel5 */
NVIC_InitStructure.NVIC_IRQChannel = DMA1_Channel5_IRQn;
NVIC_InitStructure.NVIC_IRQChannelPreemptionPriority = 0;
NVIC_InitStructure.NVIC_IRQChannelSubPriority = 0;
NVIC_InitStructure.NVIC_IRQChannelCmd = ENABLE;
//DMA1_Channel5发送完成中断服务函数
void DMA1_Channel5_IRQHandler()
{
DMA1->IFCR = 0xF0000 ;
}
void SPI_DMA_Config(void)
{
RCC->AHBENR|=1<<0;
/*------------------配置SPI2_TX_DMA通道Channel5---------------------*/
DMA1_Channel5->CCR &= ~( 1<<14 ) ; //非存储器到存储器模式
DMA1_Channel5->CCR |= 3<<12 ; //通道优先级中等
DMA1_Channel5->CCR &= ~( 3<<10 ) ; //存储器数据宽度8bit
DMA1_Channel5->CCR &= ~( 3<<8 ) ; //外设数据宽度8bit
DMA1_Channel5->CCR &= ~( 1<<7 ) ; //存储器地址不增量模式
DMA1_Channel5->CCR &= ~( 1<<6 ) ; //不执行外设地址增量模式
DMA1_Channel5->CCR &= ~( 1<<5 ) ; //不执行循环操作
DMA1_Channel5->CCR |= 1<<4 ; //从存储器读
DMA1_Channel5->CCR &= ~( 1<<1 ) ; //使能传输中断
DMA1->IFCR = 0xF0000 ; //清除中断标志位
DMA1_Channel5->CNDTR &= 0x0000 ; //传输数量寄存器清零
DMA1_Channel5->CNDTR = buffer_size ; //传输数量设置为buffersize个,每传输一个8bit数据会减1
DMA1_Channel5->CPAR = SPI2_DR_Addr ; //设置外设地址,注意PSIZE
DMA1_Channel5->CMAR = (u32)SPI2_TX_Buff ; //设置DMA存储器地址,注意MSIZE
}
//DMA发送
void DMA_Send(u32 cmar, u32 buffersize)
{
DMA1_Channel5->CCR &= ~(1 << 0) ; //关闭DMA通道5
DMA1_Channel5->CNDTR = buffersize; //重置传输数据量
DMA1_Channel5->CMAR = cmar; //重置存储器地址
DMA1_Channel5->CCR |= 3 << 0 ; //开启DMA通道5,使能发送完成中断;
}
五、其他问题
- 配置SPI+DMA之后,刷屏是没有问题的,但是在按键切换的时候就出现了花屏的问题,思考了一下,按键切换刷屏是在按键中断中执行的,说明这个时候中断出了问题,通过上网查找之后,发现了这么一句话:**同一抢占优先级下,高响应优先级不能打断低响应优先级。**意思就是说,抢占优先级相同的两个中断不能嵌套,所以我更改了按键中断的抢占优先级,至此我们的整个优化问题就完美解决了。
- 但是这个问题也说明了一件事情,不能在中断里面做过多的操作,通过配置中断优先级是可以解决这个问题,但本质上还是不要把刷屏这种操作放在中断里,会容易导致卡在中断里出不来。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









