







目录
目录
三、参考书籍
一、理论知识
1、什么是KNN?
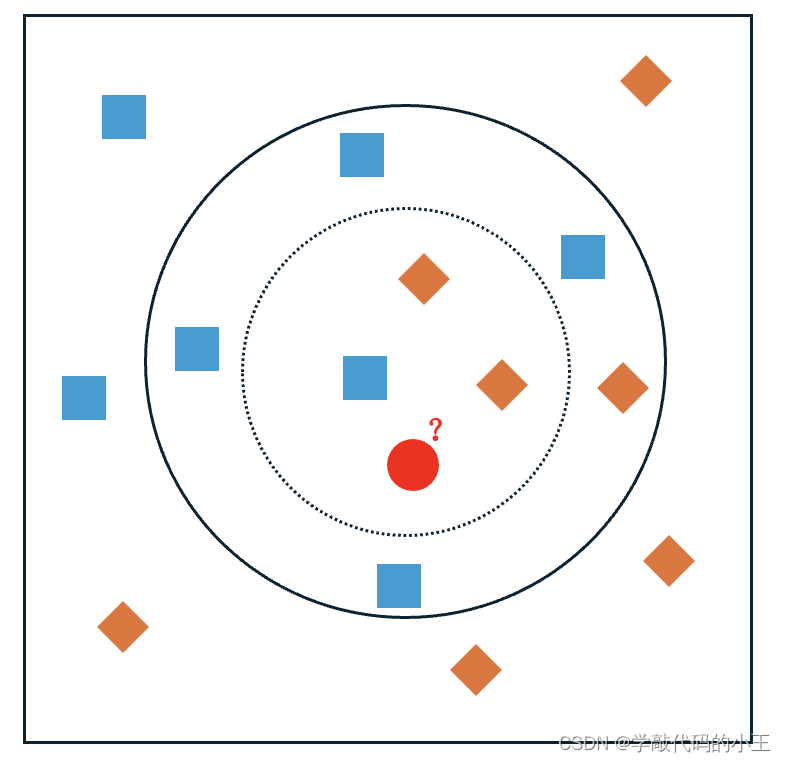
K—最近邻近算法(K- Nearest Neighbor, KNN):假设在一平面(图1)内,存在两种已知的样本数据(训练数据)类型,我们把蓝色的方块定义为A类样本数据,把橙色的菱形定义为B类样本数据。然而,在图1中,我们可以发现还存在一个红色的圆形(待预测的数据),我们怎么样才能知道它到底是属于A类(蓝色方块)还是B类(橙色菱形)呢?
KNN算法可以很好的解决这个问题,其核心思想就是可以通过选择周围的k个“邻居”,在k个最邻近的样本数据中选择所占比例最高的类别赋予预测数据。
具体来说,假设k=3(虚线圆圈),A类数据所占比例为1/3,B类数据所占比例为2/3,所以红色的圆形被赋予为B类;假设k=8(实线圆圈),A类数据所占比例为5/8,B类数据所占比例为3/8,所以红色的圆形被赋予为A类。
|
|
| 图1 KNN算法 |
2、KNN算法的计算逻辑
从上面的例子,我们可以简单的总结KNN算法的计算逻辑:
- 计算训练数据与测试数据中每一个样本的距离(因为开始时,我们不知道哪些训练数据会成为最近的邻居,只有在计算出所有可能的距离之后,才能确定哪些是最近的k个邻居);
- 选取距离测试数据最近的k个训练数据样本,作为“邻居”;
- 选择所占比例最高的类别赋予测试数据。
因此,可以发现有两个因素可以直接决定KNN算法的准确性:
- k值(“邻居”数量)的选择
- 训练数据和测试数据中样本之间的距离
3、距离度量(重点)
在这里,对于k值(“邻居”数量)的选择先不展开赘述,主要探讨如何计算训练数据和测试数据中样本之间的距离。
3.1 曼哈顿距离(Manhattan Distance)
对于一个二维平面,假设有两个点和
。这两点之间的曼哈顿距离为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









