







第七章 数值计算与优化
第5节 爬坡探险:掌握基于梯度的优化之道
在AI领域,梯度下降是最基础且广泛应用的优化方法之一。无论是深度学习中的反向传播算法,还是传统机器学习中的损失函数最优化,梯度优化方法几乎无处不在。通过梯度下降,模型能够高效地从初始参数状态收敛到最优解。因此,理解基于梯度的优化方法及其应用至关重要。本节将通过三个具体的AI应用案例来详细阐述梯度下降的工作原理与实现,帮助读者更好地掌握这一核心技术。
案例 1: 简单线性回归中的梯度下降优化
案例描述
在机器学习中,线性回归模型是最简单的模型之一,其目标是通过拟合一条直线来预测数据的趋势。通过梯度下降优化方法,我们可以最小化损失函数——均方误差(MSE),以找到最佳的回归参数。
案例分析

算法步骤

Python代码实现
import numpy as np
import matplotlib.pyplot as plt
# 模拟生成样本数据
np.random.seed(0)
X = np.random.rand(100, 1) * 10 # 输入特征,100个样本
Y = 2.5 * X + 1.5 + np.random.randn(100, 1) * 2 # 真实标签,加入噪声
# 初始化参数
w = np.random.randn(1)
b = np.random.randn(1)
learning_rate = 0.01
epochs = 1000
N = len(X)
# 梯度下降
for epoch in range(epochs):
# 计算预测值
Y_pred = w * X + b
# 计算损失函数
loss = np.mean((Y_pred - Y) ** 2)
# 计算梯度
dw = -2 * np.mean(X * (Y - Y_pred))
db = -2 * np.mean(Y - Y_pred)
# 更新参数
w -= learning_rate * dw
b -= learning_rate * db
# 每100次输出一次损失
if epoch % 100 == 0:
print(f"Epoch {epoch}, Loss: {loss}")
# 绘制结果
plt.scatter(X, Y, color='blue', label='Data')
plt.plot(X, w * X + b, color='red', label='Fitted Line')
plt.legend()
plt.show()
代码详解
- 数据生成:我们用
np.random.rand()生成100个随机样本作为输入特征 X,并通过一个简单的线性方程加上噪声生成标签 Y。 - 初始化:我们随机初始化了参数 w 和 b,并设定了学习率和迭代次数。
- 梯度计算:在每一次迭代中,我们计算了损失函数的梯度,并用梯度下降公式更新参数。
- 损失监控:每100次迭代输出一次当前的损失,方便监控优化过程。
案例 2: 神经网络中的反向传播优化
案例描述
在神经网络中,梯度下降的应用非常广泛。网络通过反向传播算法(Backpropagation)将误差从输出层传递到输入层,以调整网络的权重和偏置。我们将在这个案例中,利用梯度下降优化一个简单的前馈神经网络(Feedforward Neural Network)来解决分类问题。
案例分析
假设我们有一个两层的神经网络,输入层包含2个神经元,输出层包含1个神经元。我们使用Sigmoid激活函数,损失函数使用交叉熵损失(Cross-Entropy Loss)。
网络的前向传播和反向传播步骤如下:
- 前向传播:计算每一层的加权和、激活值。
- 反向传播:计算损失函数相对于每一层权重和偏置的梯度。
- 更新权重:使用梯度下降更新权重和偏置。
损失函数为:
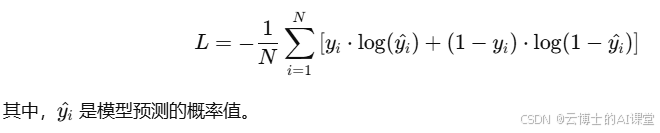
算法步骤
- 初始化神经网络的权重和偏置。
- 前向传播计算每一层的输出。
- 计算交叉熵损失。
- 反向传播,计算损失相对于每个权重和偏置的梯度。
- 使用梯度下降更新权重和偏置。
- 重复步骤2-5,直到收敛。
Python代码实现
import numpy as np
import matplotlib.pyplot as plt
# Sigmoid 激活函数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# Sigmoid 的导数
def sigmoid_derivative(x):
return x * (1 - x)
# 模拟数据
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]]) # 输入数据
Y = np.array([[0], [1], [1], [0]]) # XOR问题的标签
# 初始化权重和偏置
np.random.seed(0)
weights_input_hidden = np.random.rand(2, 4) # 输入层到隐藏层的权重
weights_hidden_output = np.random.rand(4, 1) # 隐藏层到输出层的权重
bias_hidden = np.random.rand(1, 4) # 隐藏层偏置
bias_output = np.random.rand(1, 1) # 输出层偏置
learning_rate = 0.1
epochs = 10000
# 梯度下降
for epoch in range(epochs):
# 前向传播
hidden_input = np.dot(X, weights_input_hidden) + bias_hidden
hidden_output = sigmoid(hidden_input)
output_input = np.dot(hidden_output, weights_hidden_output) + bias_output
output = sigmoid(output_input)
# 计算损失(交叉熵)
loss = np.mean(-(Y * np.log(output) + (1 - Y) * np.log(1 - output)))
# 反向传播
output_error = Y - output
output_delta = output_error * sigmoid_derivative(output)
hidden_error = output_delta.dot(weights_hidden_output.T)
hidden_delta = hidden_error * sigmoid_derivative(hidden_output)
# 更新权重和偏置
weights_hidden_output += hidden_output.T.dot(output_delta) * learning_rate
bias_output += np.sum(output_delta, axis=0, keepdims=True) * learning_rate
weights_input_hidden += X.T.dot(hidden_delta) * learning_rate
bias_hidden += np.sum(hidden_delta, axis=0, keepdims=True) * learning_rate
# 每1000次输出一次损失
if epoch % 1000 == 0:
print(f"Epoch {epoch}, Loss: {loss}")
# 绘制结果
plt.plot(Y, label="True Output")
plt.plot(output, label="Predicted Output")
plt.legend()
plt.show()
代码详解
- 激活函数与导数:使用Sigmoid激活函数,它的导数被用来计算梯度。Sigmoid函数的形式是:
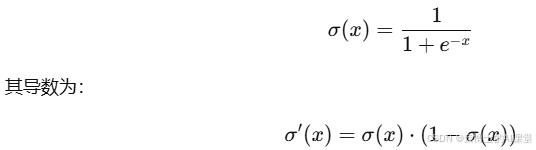
- 前向传播:我们计算输入到隐藏层的加权和并应用Sigmoid函数得到隐藏层的输出。然后,计算隐藏层到输出层的加权和,并通过Sigmoid函数得到最终输出。
- 损失函数:我们使用交叉熵损失函数来衡量预测值与真实标签之间的差异。
- 反向传播:计算输出误差并通过Sigmoid的导数得到输出层的梯度。然后,反向传播误差到隐藏层,并计算相应的梯度。
- 梯度更新:使用计算得到的梯度,通过梯度下降法更新权重和偏置。
案例 3: 深度学习中的Adam优化器
案例描述
虽然梯度下降法简单有效,但在实际应用中,尤其是在深度学习中,梯度下降可能存在收敛慢或停滞不前的情况。为了解决这些问题,Adam(Adaptive Moment Estimation)优化器应运而生。Adam结合了动量法(Momentum)和RMSProp的优点,能够自适应地调整学习率,从而加速模型的收敛过程。
案例分析
Adam优化器通过对每个参数的梯度进行加权平均和二阶矩估计,调整学习率,从而提升梯度下降的效率。具体来说,Adam使用以下更新规则:
- 一阶矩估计(动量):计算梯度的一阶矩(即梯度的加权平均)。
- 二阶矩估计(RMSProp):计算梯度的二阶矩(即梯度平方的加权平均)。
- 偏差校正:为了抵消初始化时一阶矩和二阶矩的偏差,Adam引入了偏差校正步骤。
Adam的更新规则如下:

算法步骤
- 初始化一阶矩 m0 和二阶矩 v0 为零。
- 计算每个参数的梯度 g_t。
- 更新一阶矩和二阶矩的估计。
- 对一阶矩和二阶矩进行偏差校正。
- 更新参数,使用偏差校正后的矩估计来调整每个参数的学习率。
- 重复步骤2-5,直到收敛。
Python代码实现
import numpy as np
# Adam优化器
class AdamOptimizer:
def __init__(self, learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8):
self.learning_rate = learning_rate
self.beta1 = beta1
self.beta2 = beta2
self.epsilon = epsilon
self.m = None
self.v = None
self.t = 0
def update(self, grad, params):
if self.m is None:
self.m = np.zeros_like(grad)
self.v = np.zeros_like(grad)
self.t += 1
self.m = self.beta1 * self.m + (1 - self.beta1) * grad
self.v = self.beta2 * self.v + (1 - self.beta2) * (grad ** 2)
m_hat = self.m / (1 - self.beta1 ** self.t)
v_hat = self.v / (1 - self.beta2 ** self.t)
params -= self.learning_rate * m_hat / (np.sqrt(v_hat) + self.epsilon)
return params
# 示例:使用Adam优化器优化一个简单的损失函数
def simple_loss_function(w):
return w**2 + 5*w + 10 # 一个简单的二次函数
# 梯度计算
def grad_loss(w):
return 2*w + 5 # 二次函数的梯度
# 初始化参数
w = np.random.randn(1) # 初始参数
adam = AdamOptimizer(learning_rate=0.1)
# 训练过程
epochs = 1000
loss_history = []
for epoch in range(epochs):
grad = grad_loss(w)
w = adam.update(grad, w)
# 计算并记录损失
loss = simple_loss_function(w)
loss_history.append(loss)
# 每100次输出一次损失
if epoch % 100 == 0:
print(f"Epoch {epoch}, Loss: {loss}")
# 绘制损失变化
import matplotlib.pyplot as plt
plt.plot(loss_history)
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Loss over Epochs using Adam Optimizer')
plt.show()
代码详解
- Adam优化器:我们实现了一个简单的
AdamOptimizer类,该类用于更新参数。Adam使用一阶和二阶矩的估计来调整每个参数的学习率,并且包含偏差校正以避免初期不稳定。 - 损失函数与梯度:这里的损失函数是一个简单的二次函数 f(w) = w^2 + 5w + 10,其梯度是 ∇f(w)=2w+5。
- 训练过程:每次迭代,我们计算梯度并使用Adam优化器更新参数,记录每次更新后的损失。
- 绘图:最后绘制损失随迭代次数变化的图形,可以直观地看到Adam优化器在优化过程中的效果。
小结
本节通过三个实际应用案例详细阐述了基于梯度的优化方法及其变种:简单线性回归中的梯度下降、神经网络中的反向传播优化、以及深度学习中的Adam优化器。通过这些案例,读者能够更好地理解梯度下降法、其变种以及如何在实际问题中应用它们。希望这些示例能帮助你在AI应用中高效地使用这些优化技术。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









