




 Pytorch 自动管理GPU显存,当张量不再被引用时会释放,但Nvidia-smi可能不显示。通过`torch.cuda.empty_cache()`可强制清空缓存,实现显存完全释放。了解这一机制对于优化模型训练过程中的显存使用至关重要。
Pytorch 自动管理GPU显存,当张量不再被引用时会释放,但Nvidia-smi可能不显示。通过`torch.cuda.empty_cache()`可强制清空缓存,实现显存完全释放。了解这一机制对于优化模型训练过程中的显存使用至关重要。
Pytorch已经可以自动回收我们不用的显存,类似于python的引用机制,当某一内存内的数据不再有任何变量引用时,这部分的内存便会被释放。但有一点需要注意,当我们有一部分显存不再使用的时候,这部分释放的显存通过Nvidia-smi命令是看不到的,举个例子:
device = torch.device('cuda:0')
# 定义两个tensor
dummy_tensor_4 = torch.randn(120, 3, 512, 512).float().to(device) # 120*3*512*512*4/1000/1000 = 377.48M
dummy_tensor_5 = torch.randn(80, 3, 512, 512).float().to(device) # 80*3*512*512*4/1000/1000 = 251.64M
# 然后释放
dummy_tensor_4 = dummy_tensor_4.cpu()
dummy_tensor_2 = dummy_tensor_2.cpu()
# 这里虽然将上面的显存释放了,但是我们通过Nvidia-smi命令看到显存依然在占用
torch.cuda.empty_cache()
# 只有执行完上面这句,显存才会在Nvidia-smi中释放
Pytorch的开发者也对此进行说明了,这部分释放后的显存可以用,只不过不在Nvidia-smi中显示罢了。
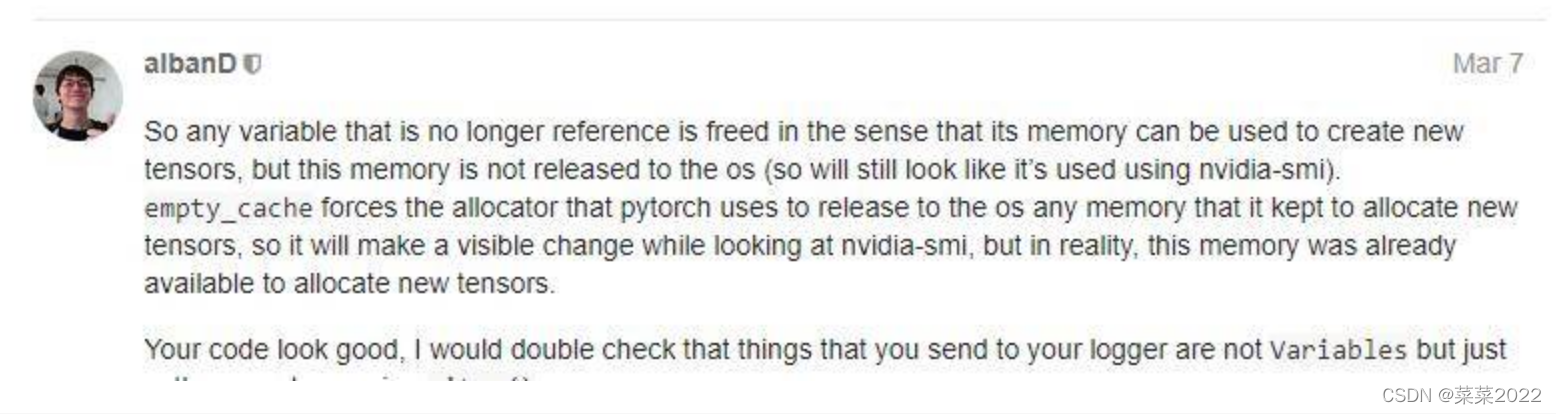
转载:


















 2080
2080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









