




在阅读《基于存算一体集成芯片的大模型专用硬件架构》论文后,对存算一体技术有了新的认识,梳理文章内容如下。本文分析了大模型在参数规模和系统算力需求上的指数级增长趋势,介绍了存算一体集成芯片的优势,包括缓解带宽瓶颈、实现高并行度数据流和多样化的存算一体技术分类。探讨了通过轻量化-存内压缩的协同设计,展示了存算一体架构在带宽需求、功耗和面积效率等方面的优势。总体而言,存算一体集成芯片为大模型的推理提供了一种高效、节能且具有潜力的硬件解决方案,供大家学习参考。
一、引言
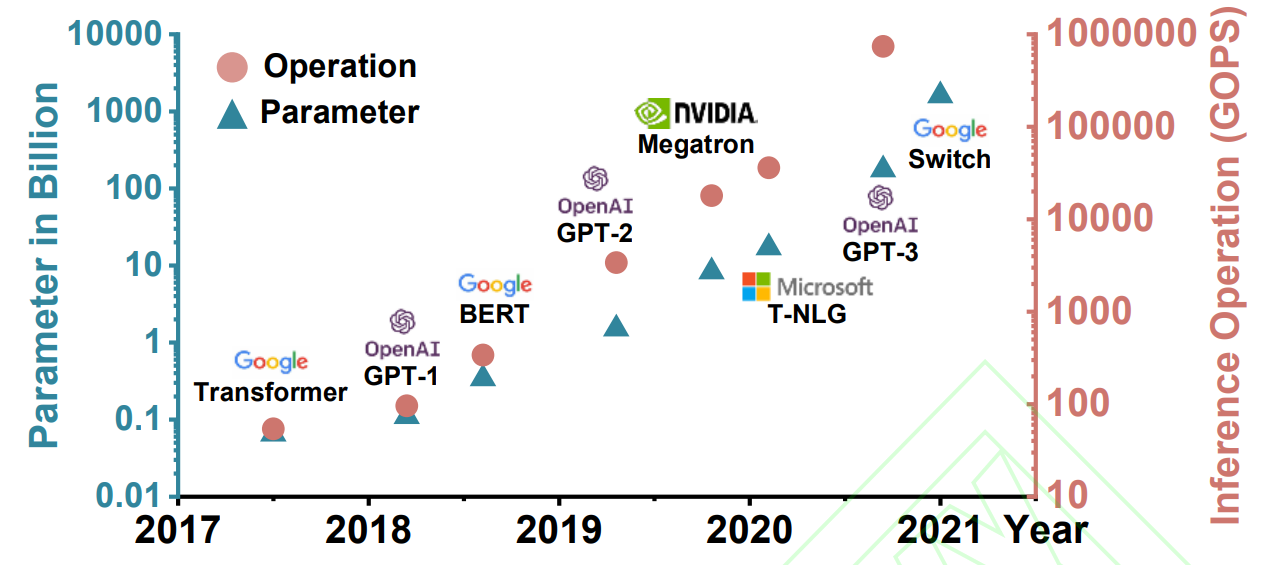
在当今人工智能领域,大模型如同一座座不断崛起的巨型灯塔,照亮了技术发展的新路径,但同时也给传统硬件架构带来了前所未有的挑战。以 ChatGPT 为代表的人工智能大模型,其参数规模和系统算力需求呈指数级迅猛增长。从模型尺寸来看,每两年便增长 240 倍,相应的算力需求更是近乎疯狂地增长近 750 倍。这种爆发式增长使得传统硬件架构逐渐不堪重负。
二、大模型对数据中心的挑战
(一)集成芯片技术
当前,能够支持大型模型的数据中心和超级计算机普遍采用以 xPU+主机内存缓冲器(HBM)集成芯片为核心的高性能处理器芯片系统。这些大算力芯片具备 P 级算力和 100 GB 级存储性能,例如 Nvidia H100 图形处理器(GPU)拥有 2 PFLOPS(每秒执行一千万亿浮点运算)的算力,AMD Instinct MI300 拥有 383 TFLOPS(每秒执行一兆浮点运算)的算力,华为昇腾 910 B 则具备 256 TFLOPS 算力等。然而,传统的超大规模和超大面积的单芯片 SoC 方案已经面临着诸多问题,包括利用率低、良率低、验证复杂度高以及设计成本激增等。同时,集成电路制造已经达到了光刻掩膜版的最大面积上限,而 30.48 cm(12 寸)晶圆的掩膜也在光刻机的要求下存在上限,最大芯片设计面积为 858 mm²。在这种背景下,单芯片 SoC 的算力进一步扩充空间受到限制,潜在的良率问题和面积限制使得算力的提升变得更加困难。自 2023 年起,美国进一步加强了针对中国芯片产业的出口限制,对总处理性能和算力密度超过规定的芯片实施了更加严格的管制。

为了缩小智能计算和处理器芯片技术上的差距,采用微纳架构工艺将多个芯片(粒)集成已经成为克服单芯片制造最大面积极限和芯片电路规模瓶颈的重要手段。不同于单芯片方案,集成芯片方案通过使用先进封装技术将多个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 693
693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











