




文档处理中不可避免的遇到表格,关于表格的处理问题,整理如下,供各位参考。
问题描述
RAG中,对上传文档完成版式处理后进行切片,切片前如果识别文档元素是表格,那么则需要对表格进行处理。一般而言,表格处理分成三个部分:
- TD任务,Table Detection,表格识别
- TSR任务,Table Structure Recognition,表格结构识别
- TCD任务,Table Content Recognition,表格内容识别
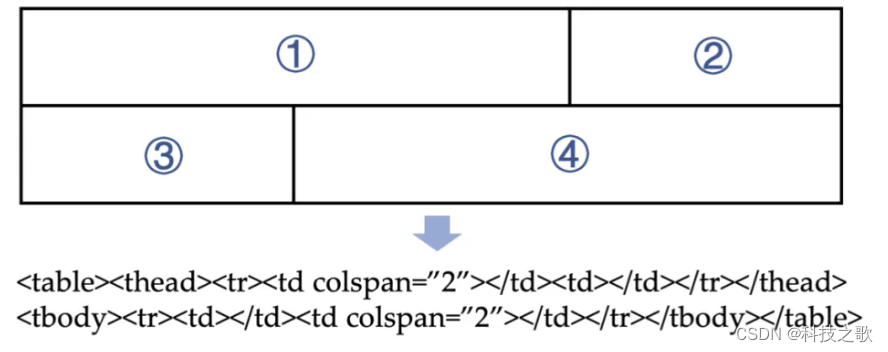
表格检测任务是识别文档中的表格元素;表格结构识别则是理解表格的布局和结构;而表格内容识别则是提取表格中的具体数据。这些任务共同构成了表格处理的完整流程。目前主要的思路是通过识别到表格,将表格转化为结构化文本信息,比如HTML或者Markdown,再利用LLM对结构化文本的泛化能力进行分析和处理。
然而,在现实世界的一些场景中,获取高质量的文本表格表示可能比较困难,而表格图像则更容易获取。因此,如何直接使用直观的视觉信息来理解表格是一个关键且迫切的挑战。

多模态表格理解的思路
多模态表格理解指的是结合文本、图像等多种模态信息来理解表格内容。在文本表格表示难以获取的情况下,如何利用直观的视觉信息来理解表格是一个很好的研究方向。为了解决多模态表格理解问题,构建了一个名为MMTab的大规模数据集,涵盖了广泛的表格图像、指令和任任务,为多模态表格理解提供了丰富的实验场景。MMTab数据集的设计思路和数据构造方式,为研究者提供了新的视角和工具,以应对多模态表格理解中的各种挑战。
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2035
2035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











