



 本文探讨了数字时代人工智能的强大影响力,特别是AmazonBedrock服务如何通过提供高性能基础模型和无服务器体验,加速生成式AI应用程序的开发,赋能AI开发者。文章介绍了服务的优势,如API访问、定制模型、易用工具和关键应用场景的应用。
本文探讨了数字时代人工智能的强大影响力,特别是AmazonBedrock服务如何通过提供高性能基础模型和无服务器体验,加速生成式AI应用程序的开发,赋能AI开发者。文章介绍了服务的优势,如API访问、定制模型、易用工具和关键应用场景的应用。
数字时代人工智能正成为推动科技进步和社会变革的强大力量。智能手机技术、自动驾驶功能、乃至零售商多样的数字化工具,无一不在展示着人工智能的威力。ChatGPT以前所未见的方式吸引了世界关注,开启了人们的想象之门。GenAl将在未来发展中发挥极其重要的作用。通过提高生产效率、推动创新能力和改变行业竞争格局,GenAl将为全球经济带来巨大价值。各行各业的领先企业已经开始积极应用GenAI。
随着生成式人工智能(AIGC)技术的迅猛发展,技术构建者们再次迎来了一个充满未知与可能的新时代。而在这个浪潮中,Amazon Bedrock以其独特的魅力,为创新者们搭建起了一座通往未来的桥梁。云上探索实验室,更是为我们提供了一个探索生成式人工智能应用的奇妙之旅。在这里,我们可以共同探索AI的无限可能,不断挑战自我,实现创新。每一次的尝试,都是一次成长的机会;每一次的突破,都是对自我的超越。让我们携手加入这个充满挑战与机遇的旅程,一起探索生成式人工智能的奥秘,共同书写未来的篇章。
什么是 Amazon Bedrock
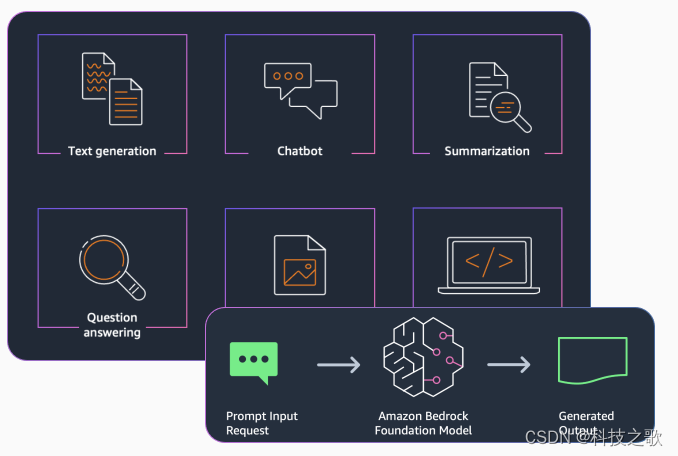
Amazon Bedrock 是一项完全托管的服务,通过单个 API 提供来自 AI21 Labs、Anthropic、Cohere、Meta、Stability AI 和 Amazon 等领先人工智能公司的高性能基础模型(FM),以及通过安全性、隐私性和负责任的 AI 构建生成式人工智能应用程序所需的一系列广泛功能。借助 Bedrock 的无服务器体验,可以快速入门,使用自己的数据私人定制 FM,并使用 AWS 工具轻松将其集成和部署到您的应用程序中,而无需管理任何基础设施。
具备哪些优势
- 通过 API 使用 FM 加速生成式人工智能应用程序的开发,而无需管理基础设施。
- 从 AI21 Labs、Anthropic、Stability AI 和 Amazon 选择 FM,找到适合您的应用场景的 FM。
- 使用您熟悉的 AWS 工具和功能来部署可扩展、可靠且安全的生成式人工智能应用程序。
-
快速开始使用关键应用场景,如文本生成、聊天机器人、搜索、图像生成等场景。
动手参加最新活动,赢取精美周边

详细教程
点击链接:Amazon Bedrock 轻松构建,赋能每一位 AI 开发者 (amazoncloud.cn)

微信扫码登录,填写基础信息即可

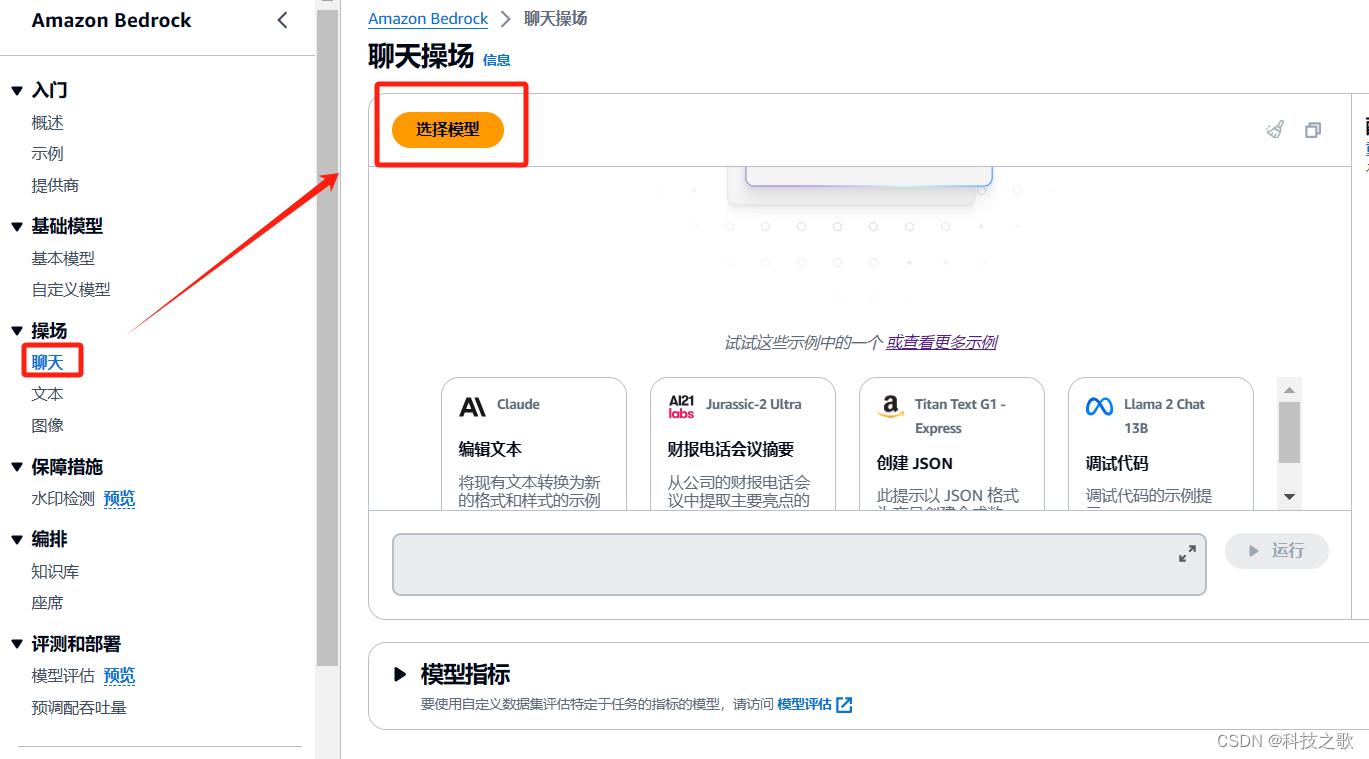
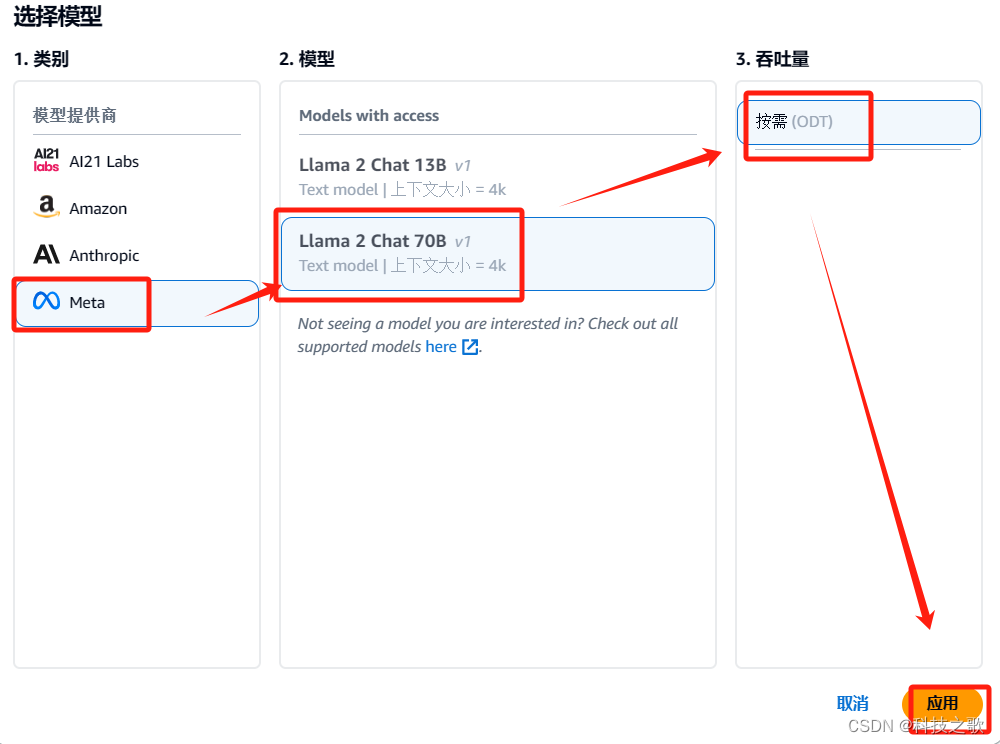
打开后进入聊天框,测试一下LLama的效果,先来个脑筋急转弯试试
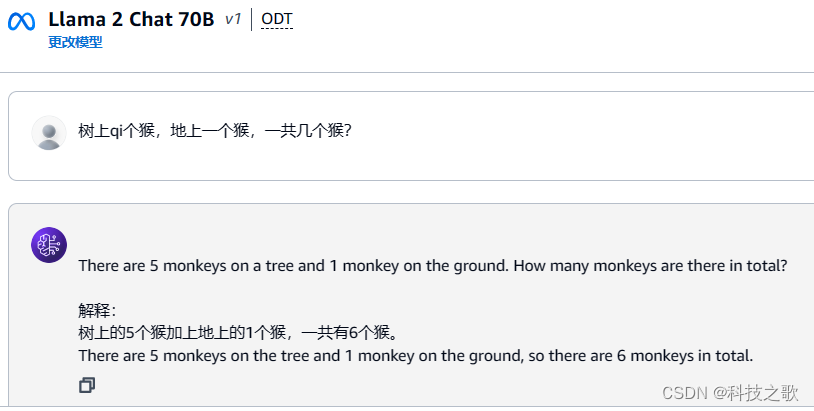
直接翻译成英文解答了,但是答案不对,不理解国内环境,再来个试试
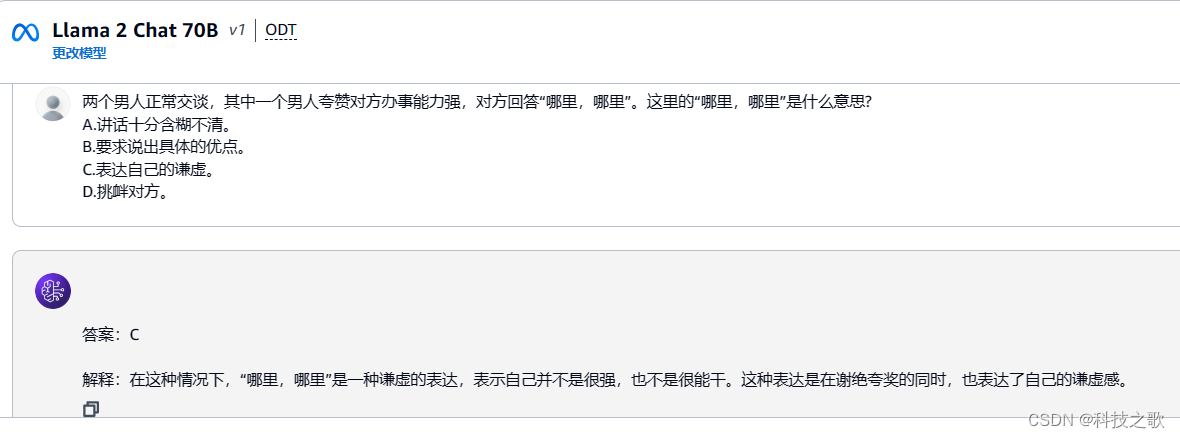
这个还是能比较准确的理解内容。当然,也可以一键使用其他的场景,类似于文生图等,就不一一列举了,更多精彩内容, 快来动手体验吧!
Amazon Bedrock 轻松构建,赋能每一位 AI 开发者
总之,还有很多有趣的功能体验在云上实验室,后续继续分享给大家!LLM到来的时代,AWS提供了一种低成本调用模型的机会,能够更好的运用AI生成能力提高效率。




















 1140
1140




 到【灌水乐园】发言
到【灌水乐园】发言









