



李老师主要介绍了两种”说法“,但实际上是一个意思。这里先概括性总结一遍防止后面不知道在说什么。
第一种说法:“神经元 + 感受野 + 权值共享”的视角
-
Neuron(神经元):每个神经元不再连接整张图片,而是只看图像中的一小块区域,称为 Receptive Field(感受野)。
-
参数共享:所有看相同大小区域的神经元,共用同一组参数(也就是一组权重和 bias)。
-
这种结构就大幅减少了参数数量,使得模型更有效且不容易过拟合。
-
每个感受野产生一个特征响应,整张图由多个神经元覆盖不同区域共同提取特征
-
通过局部观察 + 权重共享,神经元可以“扫描”整张图寻找相同的图案。
第二种说法:“Filter 卷积核滑动”的视角
-
把 CNN 看成有一堆 Filter(卷积核)。
-
每个 Filter 是一个小尺寸的 Tensor(如 3×3×3),它在整张图片上滑动,与图像对应区域做 内积运算(卷积)。
-
每个 Filter 提取一种特定的特征,滑动后得到一张新的图,称为 Feature Map。
-
多个 Filter → 多个 Feature Map,构成输出的多通道图像。
-
每个 Filter 就是一组共享参数,滑动这个 Filter 就相当于不同位置的神经元使用相同参数进行计算。
现在先说第一种 ,以图像分类为例
第一个版本
1、图像处理与目标
图像输入大小通常需要假设是固定的大小(不知道现在的机器学习还需不需要,发展太快而我半路出家orz)。
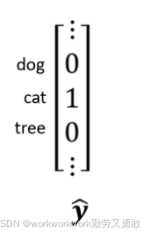
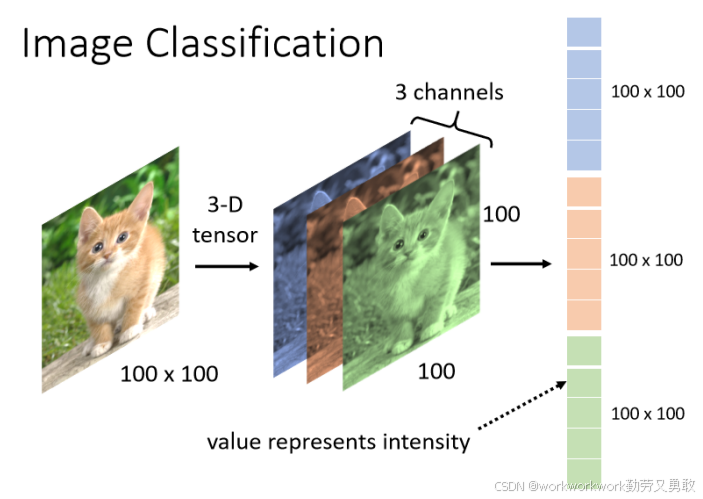
然后需要图片怎么变成一个输入的向量呢,对于计算机来说,一张彩色图片就是三个色域的叠加,RGB就是图像的“通道”(Channel),把RGB拆开它其实是一个三维的“张量” Tensor,其中一维代表图片的宽,另外一维代表图片的高,还有一维代表图片的Channel 的数目。
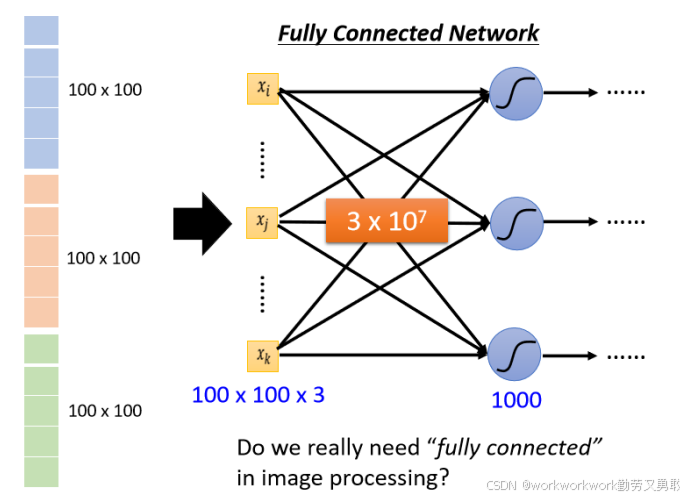
所以有什么办法来简化这个步骤?
2、感受野 Receptive Field
有时并不需要看整张图来感受事物,通过捕捉图像中有意义的局部结构或特征(Pattern)就行,比如看到鸟嘴这个 Pattern、看到眼睛这个 Pattern、看到鸟爪这个 Pattern —— 组合起来判断是一只鸟。
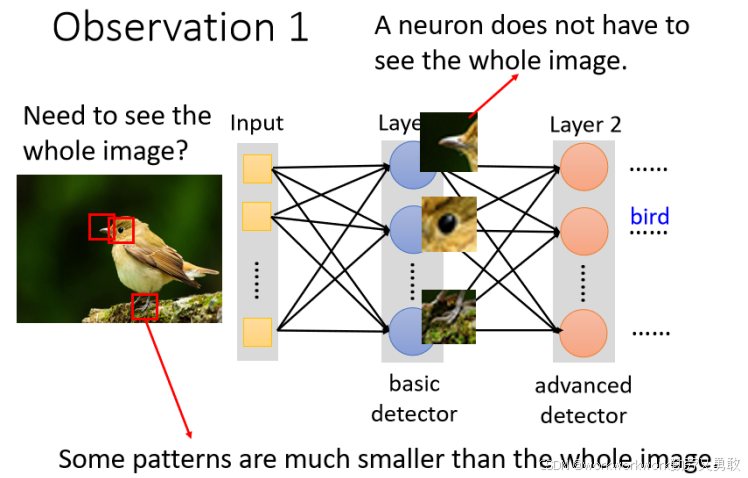
感受野就是人为划分一个区域给神经元,
例如:
-
神经元 A 的感受野是图片左上角的 3×3×3 区域;
-
神经元 B 的感受野是图片右下角的另一个 3×3×3 区域;
-
不同神经元“负责”的区域不同,它只考虑自己的 Receptive Field(彼此间可重叠)。
具体来说 :
-
在感受野范围内(比如 3×3×3):
-
把这个局部的 3D Patch 拉直成一个向量(长度为 27)
-
-
神经元对这 27 个输入值乘上各自的权重,加上 bias
-
结果送入激活函数(如 ReLU)
-
输出值作为下一层的输入
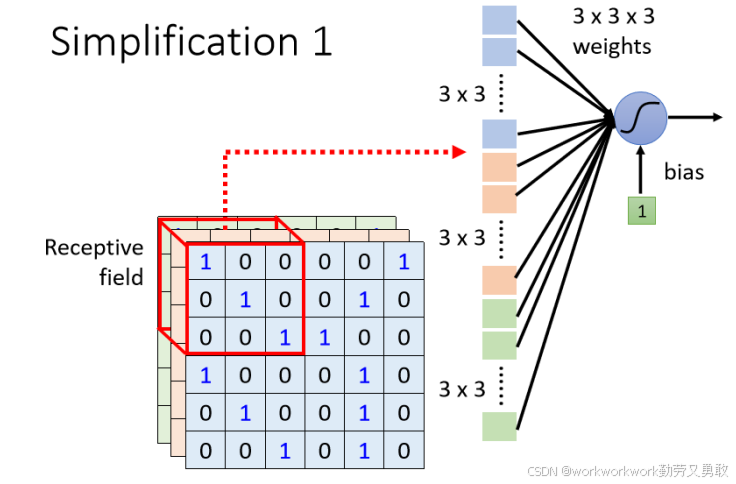
其他设计细节:
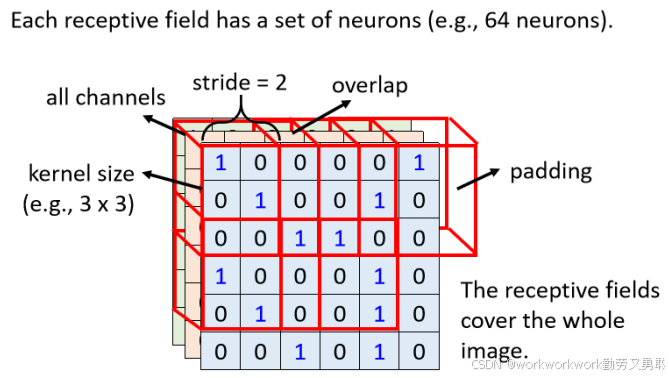
Stride(步长):感受野在图像上滑动的距离,常设为 1 或 2,步长越小,感受野之间的重叠越多,在水平和垂直方向上都有。
Padding(补边):为了让边缘也能被处理,感受野滑动到图像边界时可能会超出图像尺寸,常见处理方式是补 0(Zero Padding)
Kernel Size(感受野大小):一般是 3×3(非常常见),大 kernel(如 7×7 或 11×11)可以侦测更大范围的 Pattern,但也增加计算量。
PS:至于小的size会不会不能捕捉跨度较大的特征,比如鸟嘴大小是7x7的? 并不会!通过多层叠加的方式,CNN可以逐层提取更大范围、更抽象的特征。后续会着重讲一讲。
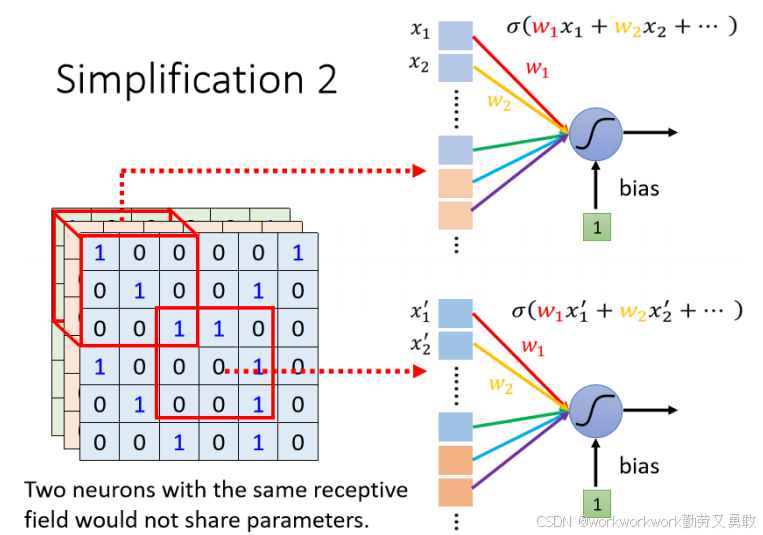
3 、权值共享
需要注意到,相同的特征可能出现在不同位置,比如:鸟嘴这个 Pattern,可能出现在图像的左上角、正中央或右下角——它的形状没变,只是位置不同。
这说明:
-
同一个物体的特征(如“鸟嘴”)可以在图像的任何位置出现;
-
若每个位置都用不同的神经元参数来识别同一个特征 → 太浪费;
-
不如让“识别鸟嘴的能力”在所有位置通用。
所谓参数共享,就是不同位置的神经元使用同一组权重来识别相同的特征。
换句话说:
-
我们不为每个位置单独训练一套识别“鸟嘴”的参数;
-
而是训练 一组卷积核(Filter),给所有感受野共用,它在图像上滑动,重复使用这组参数,去识别整个图中的该特征。不论“鸟嘴”或者“鸟爪”出现在哪,只要图像局部结构匹配,它就能被识别出来。
-
这就像一个侦测器在图上滑动,每个感受野都有被不停问:“这个地方是鸟嘴吗?这个地方是鸟爪吗?这个地方是“鸟尾”嘛,,,,,,,”
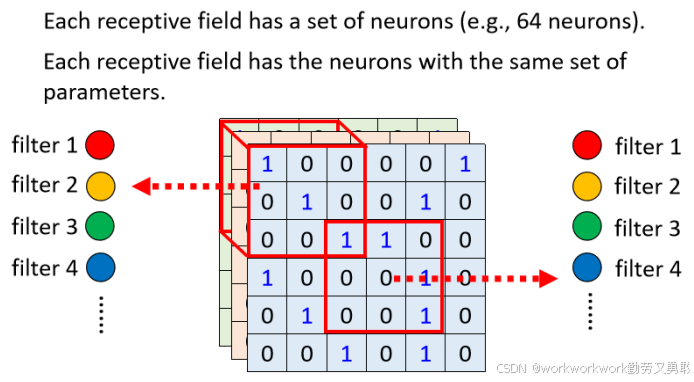
第二个版本
以卷积核滑动的视角来解释整个卷积过程。
-
Filter 是一个小尺寸的 Tensor,形状通常是:
-
3×3×Channel3 \times 3 \times \text{Channel}3×3×Channel
-
比如 RGB 图像 → 通常是 3×3×33 \times 3 \times 33×3×3
-
-
Filter 中的数值就是 CNN 要学习的参数(weight)
-
你可以把 Filter 理解为一个“特征侦测器”——它专门用来找图像中的某种模式(Pattern)
1、卷积运算过程
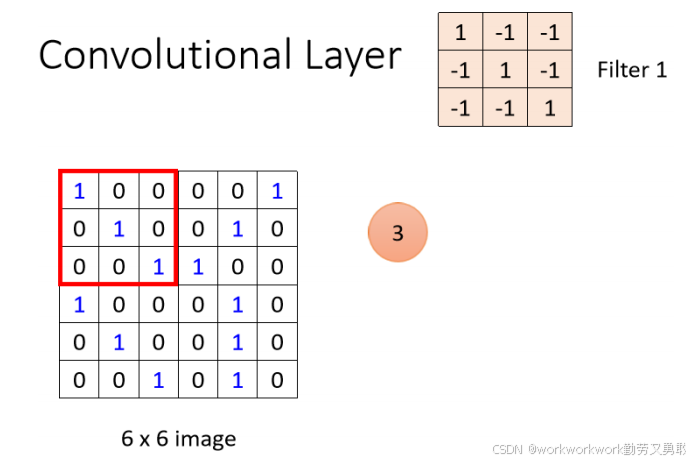
将 第一个Filter 放在图像左上角,覆盖一个 3×3×Channel 的小区域,比如这个Filter 1里的参数代表鸟嘴。这里我们假设Channel是1,如果Channel是3记得每层图片都要做一遍后面的操作。
对这个区域与 Filter 做逐元素乘法并求和(inner product),注意不是矩阵乘法,就是相同位置的相乘再相加。
得到一个数字,表示这一块区域与 Filter 的“匹配程度”,此处为3,代表这块区域和鸟嘴挺像的
然后 Filter 向右滑动(步长stride=1),重复操作
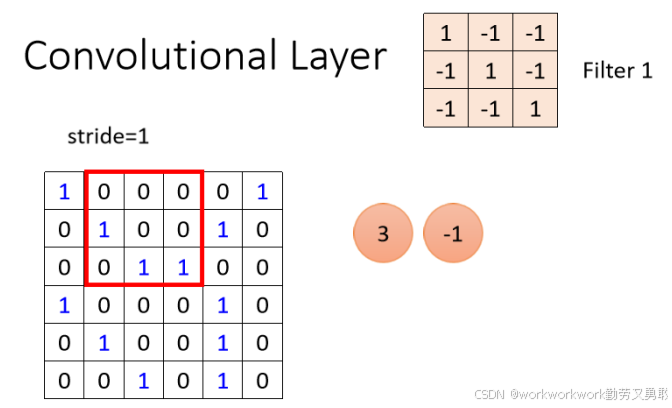
横向滑完一行 → 向下滑动,继续处理下一行
整张图滑完,得到一组数据:
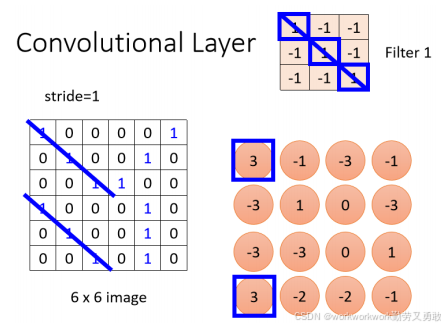
然后对第二个Filter从左上角开始扫起,重复Filter 1的操作得到Filter 2的数据,下图用蓝色的表示
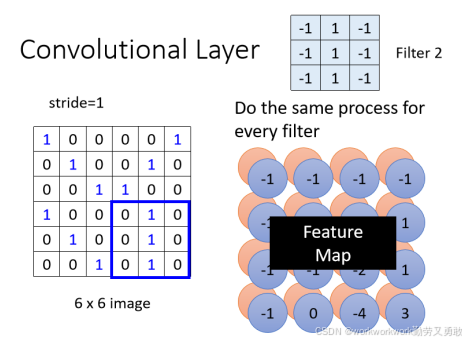
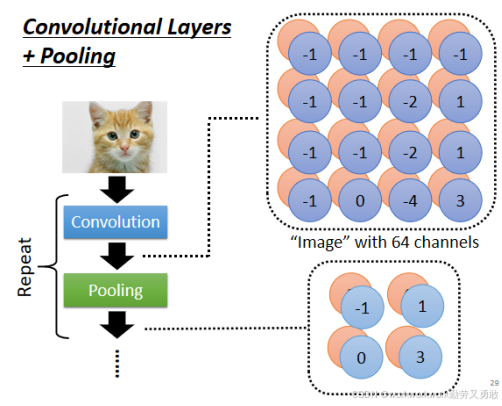
所有Filter滑完,得到一个新的 2D 特征图(Feature Map)
第二层卷积原理还是一样的,只是 Filter 不再处理原始图片,而是处理上一层的 Feature Map,如果Filter有64组,那图中特征图就是4*4*64,这个 Feature Map就可以看成是一个Channel等于64的一张新的图片,就这样一直卷下去
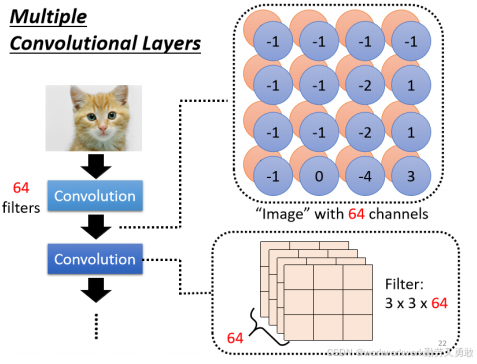
2、卷积为什么可以不用大核
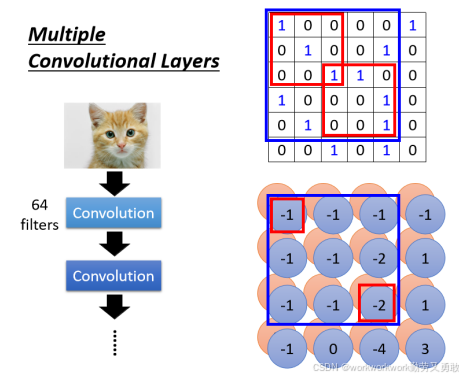
以第二层卷积为例,如果卷积核一样是3*3
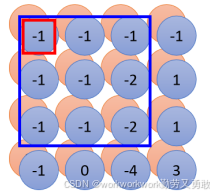
在原来的图像上,由于步长为1,它考虑的其实是一个5*5的范围:
池化 pooling
Pooling 是一种下采样(Subsampling)操作,用于降低特征图的空间尺寸,减少参数和计算量,同时保留重要信息。
比如一张图片,去掉偶数行和列的像素可能不影响你认出那张图。常见的有Max Pooling(最大池化、Average Pooling(平均池化)、Global Pooling(全局池化)。
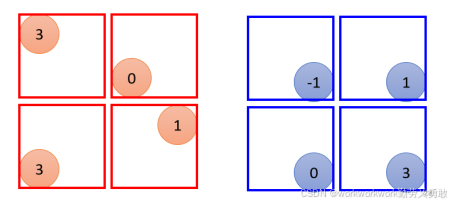
例如Max Pooling:
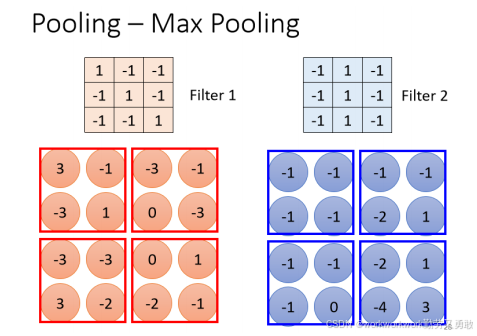
-
每个区域中取 最大值。
-
用于提取最显著的激活值,保留强烈响应的特征。
-
比如这个例子里2x2一组,选最大的,就变成这个样子:
当然不是所有东西都适合池化, 比如不能把棋盘的奇数行和偶数列去掉还认为它是原来的局势,Pooling 的本质是 压缩信息、增强泛化,适合大多数图像任务。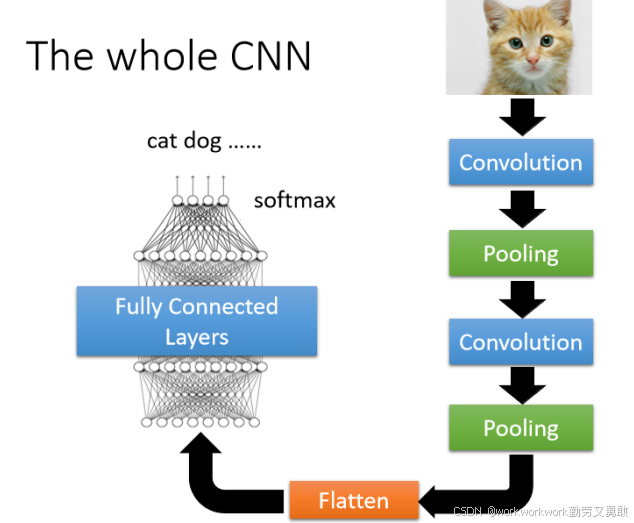
现代 CNN 结构(如 ResNet, Vision Transformer)很多都倾向于用 stride=2 的卷积代替 pooling
更好地保留空间信息,更灵活地学习下采样方式。
CNN的局限性
-
对缩放、旋转等几何变化不具备鲁棒性。(现在好像也有很多方法解决这个问题,不过我还只是初学就不多想了....)
-
需要通过 数据增强(Data Augmentation) 增强泛化能力。

















 1695
1695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









