



个人学习笔记,如有错误欢迎指正,也欢迎交流,其他笔记见个人空间
GAN 的训练难点
-
训练不稳定:Discriminator和Generator需要“棋逢对手” ,否则可能无法获取有用的梯度;
-
超参数敏感:训练非常依赖学习率、batch size、初始化等;
-
模式坍塌(Mode Collapse):Generator 只生成一种样式的图像,缺乏多样性;
-
特别难训练文本生成:梯度无法直接传导至离散输出(token),常需强化学习(如SeqGAN)配合。
典型 GAN 架构和改进版本
1. DCGAN(Deep Convolutional GAN)
-
使用卷积结构替代全连接层;
-
对图像生成效果显著提升。
2. WGAN(Wasserstein GAN)
-
使用 Wasserstein 距离代替 JS 散度;
-
优化过程更稳定,避免梯度消失。
3. Conditional GAN(cGAN)
-
允许给定条件(如类别标签、文字说明)生成特定样式图像;
-
应用于文本生成图像(Text-to-Image)、图像风格转换等。
4. Sequence GAN、ScratchGAN
-
解决离散序列(如文本)生成的难题;
-
使用强化学习+GAN,从头训练文字生成网络。
多样性问题与风险
1. Mode Collapse(模式坍塌)
-
Generator 总是生成几乎相同的图像;
-
容易“骗过”分类器,但不具备多样性;

2.Mode Dropping(模式遗漏)
-
Generator 忽略某些真实分布中的子类别(如图中右边的星星);
-
多样性看似正常,但实际“偏科”严重(如肤色单一);
-
更难检测,常常漏掉数据的“长尾”。

GAN的生成效果评估
一、评估生成器好坏的难点
GAN 的 Generator 训练完成后,我们需要判断它生成的图像到底“好不好”。但这不是一件简单的事,原因包括:
-
人眼判断不客观:早期的 GAN 论文几乎都是靠“放几张图让人看”,没有量化指标;
-
缺乏统一标准:不同任务、不同应用场景对“好”的定义也不同;
-
可能只是“背”住了训练数据(记忆式生成,Memory GAN),而非创造新样本。
二、几种常见评估方法
1. 视觉分类器分布评估法(直觉质量评估)
-
使用预训练好的 图像分类器(如 InceptionNet) 来判断生成图像的“可识别度”。
-
给一张生成图
y,分类器输出概率分布P(c|y)。 -
越集中的分布表示分类器越“有信心”,图像更清晰,质量可能越高;
-
若分布很均匀(混乱),说明图像可能是“四不像”。
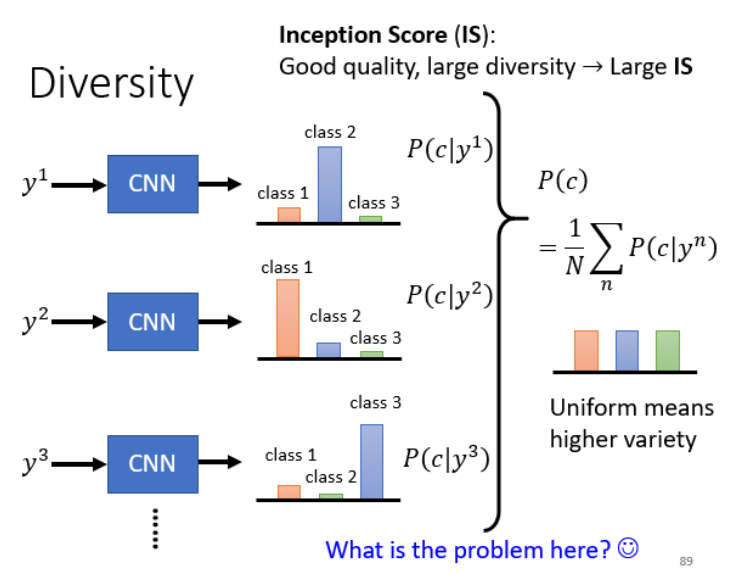
2. 代表图像质量的指标:Inception Score (IS)
-
同时衡量了“图像清晰度”与“类别多样性”。注意它和分类器评估方法并不冲突,视觉分类器的评估方法看的是单张图片丢进分类器后的输出分布是否集中。IS看的是所有生成图像整体的分类分布是否均匀。两者评估的范围不同,不能混为一谈
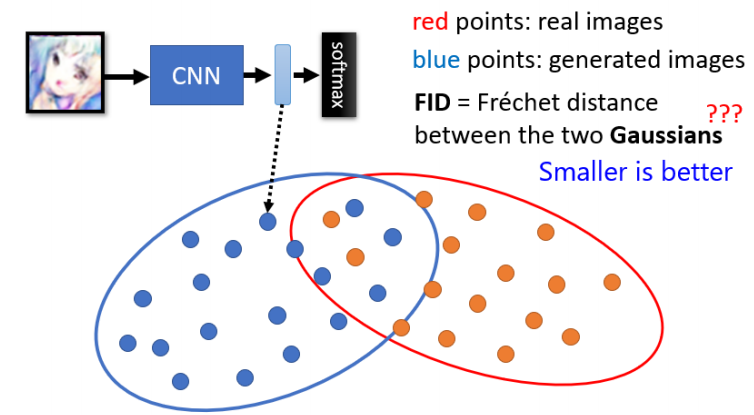
3.Fréchet Inception Distance(FID):
-
使用 Inception 的特征向量(非最终分类,进入 Softmax 之前的 Hidden Layer 的输出),视为高维高斯分布;
-
比较真实图像与生成图像特征分布的差异;
-
FID越小越好;
-
更稳定,也考虑多样性;
-
缺点:高斯假设、计算量大。
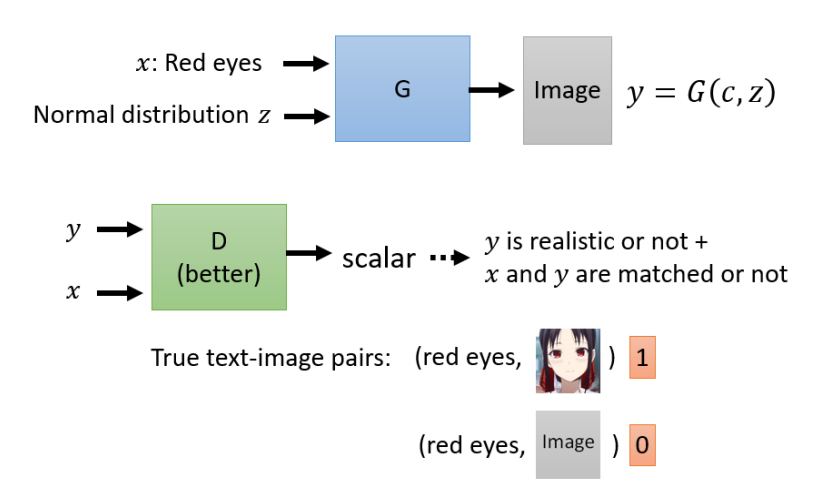
Conditional GAN 的应用与训练
1. 文本到图像(文生图)
-
文字描述作为 Condition 输入;
-
需标签配对数据(如“红头发+绿眼睛”);
-
训练 Discriminator 判断图片与文字是否匹配(注意需要成对的资料)。至于不成对的资料的机器学习,比如转换文件格式、转换文字语气等可以使用Cycle GAN,这里就不多写了感觉对我这个方向没啥用
2. 图像到图像(图生图)
-
如黑白图上色、素描转实景、白天变夜晚等;
-
可结合 Supervised Loss + GAN Loss;
3. 声音到图像(Sound-to-Image)
-
输入狗叫声 => 生成狗图;
-
利用视频数据对齐声音与图像,训练 cGAN;
-
示例:溪水声变成瀑布,快艇声带动水花强度变化。

















 1364
1364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









