 Ray分布式并行框架:Dataset与TaskPool、ActorPool策略
Ray分布式并行框架:Dataset与TaskPool、ActorPool策略





 Ray是一个高性能的分布式并行框架,其核心数据结构Dataset和DatasetPipeline用于数据处理。DatasetPipeline采用item->block->window的三维数据布局,支持动态调整并行度。Ray提供TaskPool和ActorPool两种计算策略,TaskPool缓存执行逻辑,ActorPool动态调整资源。用户还可以自定义执行策略以适应硬件资源。
Ray是一个高性能的分布式并行框架,其核心数据结构Dataset和DatasetPipeline用于数据处理。DatasetPipeline采用item->block->window的三维数据布局,支持动态调整并行度。Ray提供TaskPool和ActorPool两种计算策略,TaskPool缓存执行逻辑,ActorPool动态调整资源。用户还可以自定义执行策略以适应硬件资源。
Ray是一个高性能的分布式并行框架,在实现上充分利用了系统库concurrent。data模块提供了部署深度学习数据集的接口,其中Dataset和DatasetPipeline是一对核心数据结构。Dataset是一个“distributed data collection”,DatasetPipeline实现Dataset中ExecutionPlan的流水执行。
DatasetPipeline定义了三维的数据排布格式,item->block->window,item对应于每一个数据条目。通过Dataset.repartition可以调整整个数据集被划分为多少个block,Dataset.window中参数blocks_per_window可以指定window中包含多少个block,值得注意的是这两个功能的实现都采用了“更加均衡”的策略,因此可能划分的结果并不一定符合预期。
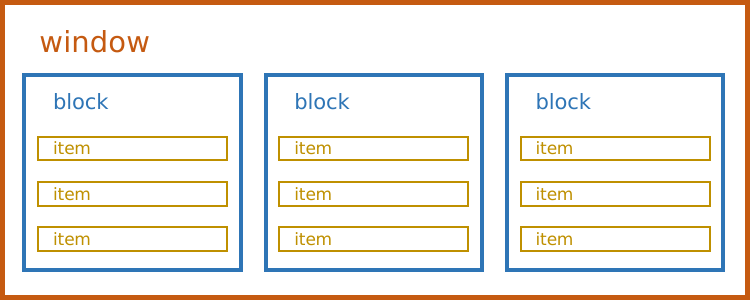
这种分层结构是框架实现并行的基础,
同一个block中itmes的执行是串行的,按照batchsize为步长依次迭代
同一个window中blocks的执行和参数相关,在通过map/map_batches将操作方法应用于数据集时,可以通过remote_args将计算所需的资源数传入,这个参数将和总的计算资源共同决定block之间的并行度,例如在ray.init(num_cpus=8)时申请了8核计算资源,而在pipe.map(test_func, num_cpus=2)指定了计算需要2核,那么在一个window中将同时有四个block并行执行。
window之间将采用流水线的执行方式,依次执行

在实际的计算中,Ray定义了两种计算策略,
task pool
Task Pool是一种常用的并行策略,在很多语言中都有特定的解释。总的来说,task pool就是pool of tasks,相似或关联的任务集合。可以类比于Thead Pool形象化地理解,但本质上还有很多不同,例如C#中task有返回值,而thread无法直接返回。
在这里,TaskPoolStrategy会cache住执行逻辑,创建N个进程(N由上面说过的方式来决定),同时这些进程在不同的window之间共用。
map_block = cached_remote_fn(_map_block_nosplit).options(
**dict(remote_args, num_returns=2)
)
all_refs = [
map_block.remote(b, block_fn, m.input_files, fn, *fn_args, **fn_kwargs)
for b, m in blocks
]actor pool
Actor Pool是actor compute model的一种具体(简化)实现,它定义了一个自动调节大小的actor池,池子的大小由min和max限定。首先根据min创建一组Blockworker,然后向其中派发任务并等待信号,当计算资源池不足时将补充一个新的Worker用于执行。由于actor pool是在“动态”地申请资源,因此在不同的window执行时会不断地创建新的进程。
workers = [
BlockWorker.remote(*fn_constructor_args, **fn_constructor_kwargs)
for _ in range(self.min_size)
]
try:
while ...:
ready, _ ray.wait(list(tasks.keys()), ...)
if not ready:
if len(workers) < max_size and ...:
w = BlockWorker.remote(*fn_constructor_args, **fn_constructor_kwargs)
workers.append(w)
tasks[w.ready.remote()] = w
...ComputeStrategy
除了预定好的两种执行策略,Ray也可以根据硬件资源的布局,自定义执行策略

















 453
453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









