



可用性‐安全性评估
1 引言
由于采用以用户为中心的方法来改善人机交互,以及对计算机相关的隐私和安全性问题日益关注,研究人员和科学家提出了许多融合可用性安全的设计技术 [11,15]。这些技术被用于构建旨在平衡可用性与安全性的软件系统。然而,如果我们仔细审视当前可用的软件系统,往往会发现诸如安全性与可用性等质量属性是被分别应用和评估的[3,10,20]。
因此,绝大多数系统在构建和部署时,都没有恰当地关注对质量属性(如可用性安全)集成状态的评估。必须确保软件系统具有足够的可用性和安全性 [15,19],,以便人们能够依赖这些系统,并像与真实人类互动一样与之交互。人们应该能够轻松地操作和使用这些系统,这有助于促进人与系统之间更好的协作[9,10]。此外,人们必须能够信任这些系统足以抵御任何可能在人机交互过程中导致故意的非预期更改或更新的恶意渗透行为[2,22]。
遗憾的是,如果没有仔细考虑可用性与安全性之间的平衡,系统的设计可能导致这些属性相互冲突,无法作为统一的概念进行协调和共同评估[1,16,25]。一种已被证明有效的方法是将可用性与安全性相结合,旨在提升计算机系统的性能和质量[8]。因此,我们采用了将可用性与安全属性结合为一个综合属性——可用性安全(usable‐security)的方法。实现这一目标的一种途径是采用模型和框架,基于形成性评估方法来评估软件的可用性、安全性和可用性安全需求 [10,13,20]。评估可用性安全有助于预测软件系统在多大程度上能够同时具备可用性和安全性[13]。本研究提出了一种基于可用性安全评估模型和框架的总结性可用性安全评估矩阵。该矩阵是大规模持续研究项目中的一个重要组成部分,旨在设计一个可用性安全工程框架(USEF),以在安全性和可用性平衡至关重要的情况下增强软件开发。
第2节介绍了可用性和安全性对软件系统的重要性背景,第3节介绍了一种基于数学的评估模型,用于帮助确定可用性和安全性质量属性的水平。第4节介绍了一种用于评估软件系统可用性安全的矩阵。最后一节是关于应用该矩阵的结论。
2 背景
尽管大多数现有系统在使人类生活更加便利方面取得了成功,但仍需持续评估和改进,以确保这些系统满足可用性和安全性需求及标准[4,17]。
2.1 可用性
一个可用性问题是软件系统必须具备有效性。例如,当航空公司使用自动语音识别系统进行电话预订时,只有当这些系统能够将旅行者的话语准确转换为文本表示,并像处理文本请求一样准确地进行处理时,才能被认为是有效的。另一个可用性问题是系统必须具备足够的效率,以节省用户和企业主的处理时间。然而,有许多例子表明,声音表示过程的延长会影响自动语音识别系统访问客户信息的速度。因此,缺乏有效性和效率会导致不满意客户以及此类软件系统的拥有者产生不满[4]。
2.2 安全性
安全性也是需要持续评估和增强的另一个重要方面[17]。例如,自然语言处理方法被用于语音生物特征认证和访问控制管理应用中[5]。语音认证系统中所使用的语音表示技术必须保持机密性,以防止对这些表示技术的访问,否则可能导致认证系统被攻破。语音认证系统也可能被用来破坏完整性这一重要的安全目标,例如允许对表示技术进行未授权的修改,从而导致误导性或不正确的表示过程。人机交互软件系统必须根据可用性需求规范,确保合法用户在任何时候都能获得应用程序的可用性。例如,当生物特征系统用于认证时,必须在所有对资源的访问权限请求期间保持可用。一旦生物特征认证不可用,访问控制将无法被激活。
基于上述关于可用性和安全性对任何软件系统的重要性论证,第3和4节提出了一种评估方法论和一个矩阵,以帮助评估软件系统。
3 可用性‐安全性测量与评估
为了开发一种有效的评估方法,开发人员应在评估过程开始之前具备适当的测量技术。获得合适的度量指标使开发人员能够预测评估结果。然而,可用性安全难以测量,因此也难以进行评估[7,11]。因此,本研究基于开放网络应用安全项目[20]和SAULTA[10]提出了新的测量与评估技术。该评估技术作为可用性‐安全性评估框架(AFUS)的扩展研究工作[13]。以下小节描述了可用性与安全性的测量和评估方法。为了确保评估的一致性,在根据表2对测量结果进行处理后,所有属性及其属性均依据表1进行评估。
3.1 可用性评估
可用性(Usability)一词由国际标准化组织(ISO)定义为:产品在有效、高效和特定方式下,供合法用户顺利完成特定任务的程度[26]。其他一些研究则将准确性、记忆性(memorability)和易学性(learnability)作为次要的可用性因素[16]。本文仅关注ISO定义中的三个因素。
为了在评估阶段评估任何已开发软件系统的特定可用性水平,必须关注每个可用性属性(效率、有效性及满意度)的应用状态(级别),并提供一种可测量的方法来评估这些属性在软件系统上的表现。以下评估公式改编自比万和麦克劳德的概念[6,18]。
表1. 可用性与安全性属性及其属性的测量指南,其中列出的测量状态:HA、MA、SA和 NA分别代表已高度实现、基本实现、部分实现和未实现; α 和 β 分别代表可用性和安全性。
| HA | MA | 已实现 | SA | NA | |
|---|---|---|---|---|---|
| EF1 | EF1 ≥ 0.9 | 0.7 ≤ EF1 < 0.9 | 0.6 ≤ EF1 < 0.7 | 0.3 ≤ EF1 < 0.6 | EF1 < 0.3 |
| EF2 | EF2 < 1.0 | EF2 = 1.0 | 1.0 < EF2 ≤ 1.2 | 1.2 < EF2 < 1.5 | EF2 ≥ 1.5 |
| SA1 | SA1 ≥ 0.9 | 0.7 ≤ SA1 < 0.9 | 0.6 ≤ SA1 < 0.7 | 0.3 ≤ SA1 < 0.6 | SA1 < 0.3 |
| α | α ≥ 0.9 | 0.7 ≤ α < 0.9 | 0.6 ≤ α < 0.7 | 0.3 ≤ α < 0.6 | α < 0.3 |
| CO1 | CO1 ≥ 0.99 | 0.95 ≤ CO1 < 0.99 | 0.90 ≤ CO1 < 0.95 | 0.80 ≤ CO1 < 0.90 | CO1 < 0.80 |
| IN1 | IN1 ≥ 0.99 | 0.95 ≤ IN1 < 0.99 | 0.90 ≤ IN1 < 0.95 | 0.80 ≤ IN1 < 0.90 | IN1 < 0.80 |
| AV1 | AV1 ≥ 0.99 | 0.95 ≤ AV1 < 0.99 | 0.90 ≤ AV1 < 0.95 | 0.80 ≤ AV1 < 0.90 | AV1 < 0.80 |
| β | β ≥ 0.9 | 0.7 ≤ β < 0.9 | 0.6 ≤ β < 0.7 | 0.3 ≤ β < 0.6 | β < 0.3 |
表2. 可用性与安全性属性及其属性的评估指南,其中所列测量状态:HA、MA、SA和 NA分别代表已高度实现、基本实现、部分实现和未实现。
| 测量状态 高达成 大部 | 评估 分达成 达成 部分达成 未达成 | 评估 分达成 达成 部分达成 未达成 | 评估 分达成 达成 部分达成 未达成 | 评估 分达成 达成 部分达成 未达成 | 评估 分达成 达成 部分达成 未达成 |
|---|---|---|---|---|---|
| 评估值 9 | 7 | 6 | 3 | 1 |
有效性。 只有当用户能够实现操作这些系统的目标时,系统才能被认为是有效的。可以通过基于目标的视角来衡量有效性属性,即统计合法用户成功完成的任务数量[12]。例如,如果软件系统允许用户成功创建密码、使用先前创建的密码登录或提供其生物特征,则该软件系统是有效的。公式1可用于评估软件系统的有效性,其中 n 表示合法用户执行的已接受任务总数,R表示每次执行任务的结果(“失败”或“成功”),EF1表示系统有效率。
$$
EF1 = \frac{1}{n} \sum_{i=1}^{n} \delta(R[i]) \tag{1}
$$
其中 $\delta(\theta)$ 定义为:
$$
\delta(\theta) =
\begin{cases}
0 & \text{if } \theta = \text{failure} \
1 & \text{if } \theta = \text{success}
\end{cases}
$$
根据表1,如果系统有效率的结果为 EF1 ≥ 0.9,这意味着该软件系统具有高有效性。另一方面,如果 EF1 < 0.3的结果成立,则表示该系统无效,可能需要进一步改进。在测量有效性之后,需根据表2进行评估,因为这可以确保所有可用性属性之间的一致性。
效率。 高效的系统必须在可接受的时间内完成特定任务或流程,以达到特定目标。效率属性非常重要,因为供应商和用户都不会依赖于执行特定任务(例如:认证)耗时过长的系统。用于评估效率的指标是实现特定目标或完成特定任务所消耗的时间量。公式2描述了该评估方法,其中 n 表示执行特定任务的试验次数, β表示完成该任务的标准平均时间,而 T表示每次试验中执行该任务所花费的时间。
$$
EF2 = \frac{\frac{1}{n} \sum_{i=1}^{n} T[i]}{\beta} \tag{2}
$$
根据表1,如果系统效率比率EF2的结果小于1,则表示该软件系统具有高效率。相反,如果EF2的结果值大于或等于1.50,则表示该软件系统效率低下,因为执行该任务所消耗的平均时间远低于标准平均水平, β。在测量效率之后,需根据表2进行评估,因为这能够确保所有可用性属性之间的一致性。
满意度。 一个系统要达到令人满意,供应商和用户都必须对系统感到满意。这取决于供应商和用户是否愿意依赖并重复使用该系统。需要注意的是,满意度受到供应商和用户情绪的显著影响[16]。如果系统同时具备高效性和高效率,则最有可能被视为令人满意。由于缺乏精确的测量工具,评估满意度属性是一项具有挑战性的任务。然而,评估满意度的最佳方式是通过问卷调查,例如 SUMI[18]和SUS[23]调查,或通过访谈[16]。因此,满意度的评估需结合与以用户为中心的方法相关的HCI‐SEC原则[27],重点关注易用性、满意程度以及困惑程度。根据所给调查的结果,用户满意度SA1,将依据表1进行测量。在通过上述满意度程度经由调查测量用户满意度后,将根据表2进行评估,因为这能确保所有可用性属性之间的一致性。
评估上述标准可用性属性可通过汇总三个属性(有效性、效率和用户满意度)的评估结果来得到整体可用性评估,如公式3所示,其中 α表示可用性:
$$
\alpha = \frac{EF1 + EF2 + SA1}{3} \tag{3}
$$
方程3提供了表 α中所示的度量。因此,与评估可用性属性一样,软件系统的整体可用性基于表1进行评估,因为这为所研究的三个质量属性(可用性、安全性以及可用‐安全性)之间的评估一致性提供了依据。
3.2 安全性评估
“安全性”一词有多种定义方式。本质上,系统安全是一系列用于防止弱点被利用的方法和技术,其基于三个安全目标:机密性、完整性和可用性[21]。软件系统存在需要被发现并修复的漏洞,或至少应加以防护以避免被利用。因此,要达到可接受的安全水平,必须应用并实现这三个安全属性。以下将分析安全属性的重要性、它们在系统中的应用方式以及如何对其进行可量化的评估。
机密性。 机密性是所有安全系统的目标。机密性定义为仅向授权用户授予访问权限的能力。如果未授权用户获得对计算机系统的访问权限,则可能访问机密信息,并利用这些信息损害系统供应商或用户。为了衡量软件系统的机密性,应用公式4、5和6 ,其中n表示访问尝试的总次数, α表示单次访问尝试 (“虚假访问”或“真实访问”), TAR代表真实访问率,FAR代表虚假访问率,CO1代表系统机密性评估值。
$$
CO1 = TAR \tag{4}
$$
$$
TAR = \frac{\sum_{i=1}^{n} \delta(\alpha[i])}{n} \tag{5}
$$
其中 $\delta(\theta)$ 定义为:
$$
\delta(\theta) =
\begin{cases}
1 & \text{if } \theta = \text{true access} \
0 & \text{if } \theta = \text{false access}
\end{cases}
$$
并且
$$
FAR = 1 - TAR \tag{6}
$$
根据表1,如果系统机密性率CO1的结果大于或等于0.99,则表示系统具有高度机密性。相反,如果CO1的结果小于或等于0.80,则表示系统未能提供机密性,因为向过多的未授权用户授予了访问权限。在测量机密性之后,需根据表2进行评估,因为这可以确保所有安全属性之间的一致性。
完整性。 完整性意味着对于授权用户,系统不允许他们以不恰当的方式执行任务,并保护数据免受任何未经授权的修改。由于对软件系统进行可用性‐安全性评估是本文的目标,因此必须正确应用完整性属性,以确保此类系统的安全性。通过使用哈希等适当的技术和工具,使系统能够创建自动备份和自动检查,从而实现该属性,此过程包括将备份文件与系统上的相同文件进行比较。公式7 描述了软件系统中的完整性计算,其中 n表示用于哈希的选定文件总数,IN1表示完整性评估结果。
$$
IN1 = \frac{1}{n} \sum_{i=1}^{n} \delta(\text{systemfile}[i] \text{backupfile}[i]) \tag{7}
$$
其中 $\delta(\theta)$ 定义为:
$$
\delta(\theta) =
\begin{cases}
1 & \text{if } \theta = 1 \
0 & \text{if } \theta \neq 1
\end{cases}
$$
根据表1,如果系统完整性IN1的结果大于或等于0.99,则表示系统提供了完整性,因为哈希结果(比较系统与备份文件)表明系统文件未发生任何未经授权的更改。相反,如果IN1的结果值小于0.80,则表示系统未提供完整性,因为发生了关键性变更。在测量完整性之后,需根据表2进行评估,因为这能确保所有安全性属性之间的一致性。
可用性。 可用性是一种安全性因素,要求系统的服务、内容或数据在授权用户需要访问时随时可用。它基于系统接收到的成功服务次数或数据访问请求次数进行衡量。公式8展示了可用性的计算方法,其中 n表示访问尝试的总次数, α表示单次访问尝试(结果为“可用”或“不可用”),而AV1表示可用率。
$$
AV1 = \frac{1}{n} \sum_{i=1}^{n} \delta(\alpha[i]) \tag{8}
$$
其中 $\delta(\theta)$ 定义为:
$$
\delta(\theta) =
\begin{cases}
1 & \text{if } \theta \text{ is available} \
0 & \text{if } \theta \text{ is unavailable}
\end{cases}
$$
根据表1,如果系统可用性评估结果AV1大于或等于0.99,则意味着该软件系统具有高可用性,因为它能在需要时被其授权用户访问。相反,如果AV1的值小于0.80,则意味着系统不可用,因为超过20%的请求未得到服务。在测量可用性之后,需根据表2中的统一数值评估值对其进行评估,因为这能确保所有安全属性之间的一致性。
对上述标准安全属性的评估通过将三个属性(机密性、完整性以及可用性)的评估结果相加后除以3,得出总体安全性评估。公式9展示了该计算方法,其中 β表示安全性:
$$
\beta = \frac{CO1 + IN1 + AV1}{3} \tag{9}
$$
上述计算的结果提供了表1中的一个测量状态。因此,与评估安全属性类似,软件系统的整体安全性基于表2进行评估,因为这确保了所研究的三个质量属性之间的评估一致性。
4 可用性‐安全性评估矩阵
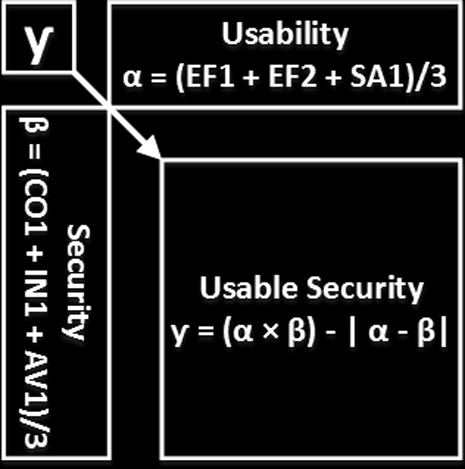
针对系统的可用性与安全性属性的分析与测量研究,深入揭示了系统可用性安全的本质与结构。根据上一节内容,可构建一个可用性‐安全性评估矩阵,以此作为实现本文总体目标的指导,即对软件系统进行评估并加以改进,使其兼具更高的可用性与足够的安全性(见图1)。图1所示的矩阵是一种用于评估软件系统可用性安全的建议方法。可通过使用公式3和9来评估系统的可用性(有效性、效率和满意度)以及安全性(机密性、完整性以及可用性)。随后将结果代入公式10中,其中 α表示整体可用性评估值, β表示整体安全性评估值, γ表示矩阵得分,即可用性安全评估结果。
$$
\gamma = (\alpha \times \beta) - |\alpha - \beta| \tag{10}
$$
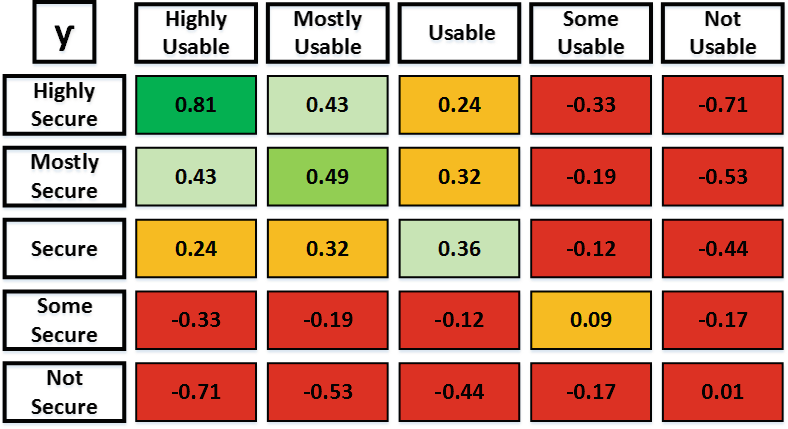
矩阵中最高的测评等级是系统得分至少为0.81,如图2所示。这意味着该系统已应用并实现了全部六项可用性与安全性属性的最高水平。此类系统被认为既可用又安全,不仅因为它实现了可用性和安全性目标,更因为在系统开发过程的初期就通过人机交互/以用户为中心的方法,充分考虑并将可用性与安全性有机结合在一起。
另一方面,矩阵中最低的测量评估类别是当软件系统得分最多为0.01时,如图2所示,这意味着该系统未实现在可用性与安全性属性方面的任何有益值。这样的系统被认为既不可用也不安全,不仅因为它未实现可用性和安全性目标,而且因为它未能弥合可用性和安全性也受到影响。此外,系统得分如此之低表明其开发人员可能在开发过程初期并未考虑人机交互/以用户为中心的方法。
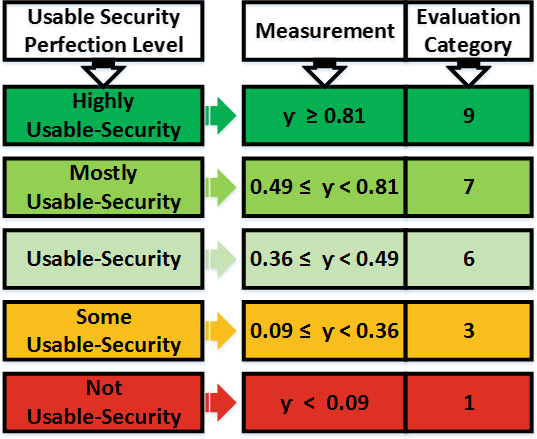
完成整个评估过程后,将获得一个最终可用性‐安全性评估结果,该结果属于五个完善等级之一:当 γ ≥ 0.81时为高可用性‐安全性,当 0.49 ≤ γ < 0.81 时为大部分可用性安全,当 0.36 ≤ γ < 0.49时为可用性安全,当 0.09 ≤ γ < 0.36时为部分可用性安全,当 γ < 0.09时为不可用性‐安全性。总体而言,每个完善等级对应的数值分类如下:高可用性‐安全性归类为9,大部分可用性安全归类为7,可用性安全归类为6,部分可用性安全归类为3,不可用性‐安全性归类为1。图3展示了最终可用性‐安全性评估与分类指南。
5 案例研究:认证方法
为了展示使用可用性‐安全性评估矩阵的优势,本节介绍了对一项实验的可用性水平进行评估的结果,该实验比较了两种认证方法。基于挑战的自适应认证 (CBAA)和基于传统的认证方法(TBAA)在[14]中进行了详细描述。该实验为每种方法使用了30个不同的场景,实验结果如下所述。
对于安全值,我们在TBAA的三十种场景中均使用了一个值(大部分安全: 0.7),其预期熵介于 226和 227之间。假设的安全值被视为在以NIST SP 800 系列作为基础安全策略时可达到的安全级别[24]。然而,由于在登录过程中显示多种认证方法增加了攻击者的复杂性,CBAA的安全级别得到了提升,如 [14],所述,其预期熵介于264和 265,之间,并额外包含生物识别。因此,我们预计CBAA的安全性至少应比TBAA高出0.1。故而,我们在CBAA的所有三十种场景中统一使用了安全值(大部分安全:0.8)。图4展示了这两组场景。
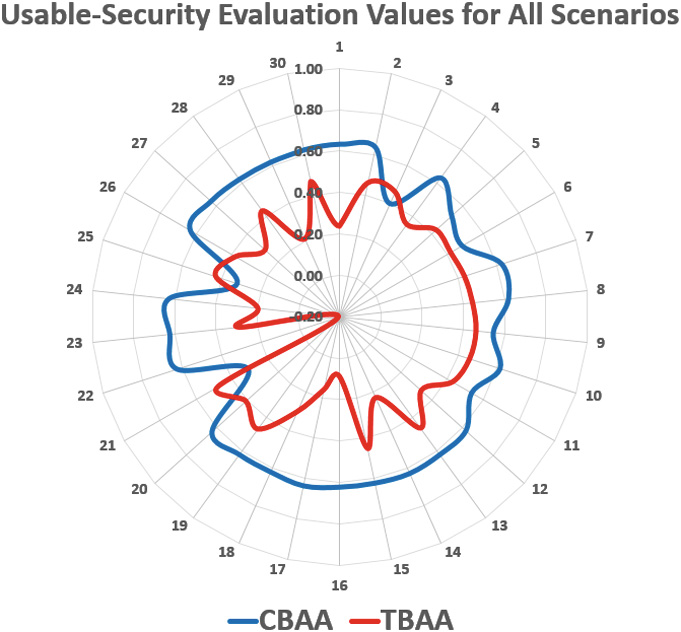
图4展示了一个雷达图,显示了基于挑战的自适应认证(CBAA)和基于时间的自适应认证(TBAA)在所有场景下可用性安全等级评估的趋势线。对两种方法趋势线的比较表明,CBAA比TBAA提供了更优的可用性安全平衡。此外,这还表明CBAA的可用性‐安全性评估结果比TBAA更稳定。另外,该图还显示了两种方法的可用性安全覆盖范围,并表明CBAA的覆盖范围比TBAA更广。根据图3中的指南,图4中基于挑战的自适应认证(CBAA)的结果显示,场景 21和25达到了“部分可用性安全”级别(分别为0.31和0.32),场景3和6分别提供了0.40和0.48的“可用性安全”级别,而其余26个场景均达到了“大部分可用性安全”级别(即:数值大于或等于0.49且小于0.81)。因此,基于挑战的自适应认证(CBAA)的整体可用性安全评估值为0.58,处于“大部分可用性安全”级别。
另一方面,图4中显示的基于时间的自适应认证(TBAA)场景表明,场景 16和22仅达到“不可用性‐安全性”级别(分别为0.09和 −0.19)。此外,有 10个场景达到了“部分可用性安全”级别,仅有18个场景提供了“可用性安全”级别。因此,基于时间的自适应认证(TBAA)的整体可用性安全评估值为 0.35,处于“部分可用性安全”级别。
6 结论
开发人员能够评估在系统需求中指定的可用性、安全性以及可用‐安全性的软件质量属性,并确保这些属性得到合理设计、正确构建、准确评估和适当部署,这一点至关重要。然而,现有的应用上述属性的方法论并不能保证所开发的系统能够达到必要的高可用性和高安全性质量标准。因此,将这些属性进行集成比单独应用每个属性更为重要。本文提出的工作超越了属性集成的应用,提出了一种评估方法来测试这些属性之间的一致性。此外,所提出的评估矩阵具有足够的灵活性,可用于修改属性度量,还可扩展用于评估其他质量属性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









