







基于核预测的FastDVDNet视频去噪技术
VNLnet、VNLB和DVDNet等算法的诞生则能有效地去除噪声。
对于加强时间一致性我们可以从以下两方面入手:
将搜索区域从空间邻域扩展到时空邻域;
使用运动估计。现在最先进的视频去噪方法FastDVDNet能很好地解决时间一致性这个问题,从而达到高效的视频去噪效果。
输入:图像序列与噪声估计,其中噪声作为输入是为了允许处理空间变化的噪声。(给补齐帧添加噪声?)
输出:t时刻的帧
连续5帧和一个噪声的估计一起作为网络的输入
Block1和Block2有着相同的结构。
Denoising Block的结构,是一个修改版的U-Net网络,相较于一般的 U-Net,它主要有以下几方面的改进:
(1)此处的网络有2个下采样层,且下采样并非通过Pool来实现,而是通过Stride为2的Conv层实现的;此外,上采样也没有通过Bilinear插值或Deconv来实现,而是通过PixelShuffle来实现的,这样有助于减少网格失真。
(2)编码器特性与解码器特性的合并是通过像素级的加法操作来完成的,这既减少了内存需求,又通过中心有噪声的输入帧与输出帧之间的剩余连接来实现剩余学习,简化了训练过程。
https://zhuanlan.zhihu.com/p/118395029
【论文复现】
对于encoder-decoder结构的U-Net,其本身具有在感受野范围内对齐的功能
https://zhuanlan.zhihu.com/p/73286010
输入:相邻5帧图像、noise map
输出:当前帧去噪后图像
网络:U-Net(16层)
数据集:Davis数据集,约38.4万样本
Loss函数:L2 loss
创新: 没有显式的运动估计阶段,对于encoder-decoder结构的U-Net,其本身具有在感受野范围内对齐的功能,从而提高性能。two-stage结构比single-stage提升去噪能力。 multi-scale结构,可以在不同的scale提取图像的特征,增大图像感受野。
时域一致性方法:
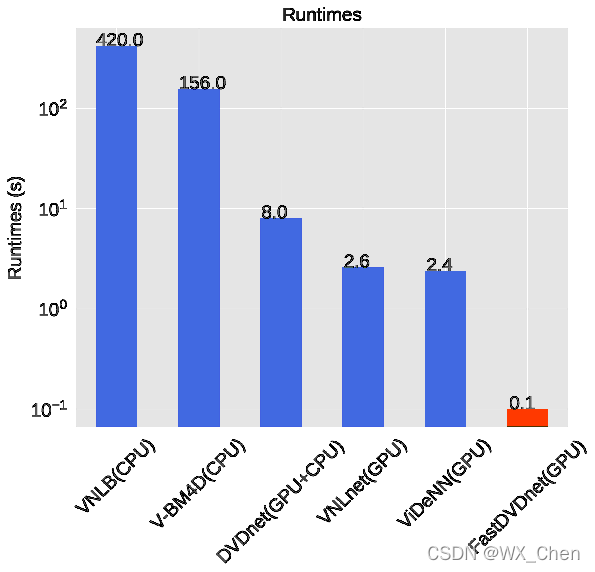
1、块匹配(VNLnet)——速度慢
2、光流对齐(DVDnet)——速度慢
3、网络隐式对齐(FastDVDnet)——精度低
代码
The model has been trained for values of noise in [5, 55]
4K 输入 只能5帧 (16G显存)
1080p 输入 可以50帧
https://github.com/m-tassano/fastdvdnet
下载nvidia-dali
https://developer.download.nvidia.com/compute/redist/cuda/
===========================================================================================================================================
As mentioned in the article, the DAVIS dataset (2017, https://davischallenge.org/) is used for training.
https://github.com/m-tassano/fastdvdnet/issues/5
'model.pth' is a pretrained model for RGB denoising. See for example that by default the definition of the 'model_file' param in 'test_fastdvdnet.py' is 'default="./model.pth"'
https://github.com/m-tassano/fastdvdnet/issues/3
the time to denoise a frame of resolution 960 × 540 is about 100ms, which is 10fps.
https://github.com/m-tassano/fastdvdnet/issues/7
===========================================================================================================================================
训练
训练集列表
https://github.com/m-tassano/fastdvdnet/issues/11
https://gist.github.com/m-tassano/27c1ef00ca42a8e50c2cee8a4205e559
Hi, I employ all the 90 sequences of the Davis trainset, from which I extract 384000, 5-frame length, random crops.
https://github.com/m-tassano/fastdvdnet/issues/9
the origin datas are jpeg format, but the model need mp4 format, so I use ffmpeg to transform the jpeg datasets to mp4 dataset
When converting the sequences one has to pay particular attention to the 'crf' and 'keyint' ffmpeg parameters to avoid strong compression. For the code to convert the image sequences see this gist
https://gist.github.com/m-tassano/0536391eb79d63864e5005ea4da88243
https://github.com/m-tassano/fastdvdnet/issues/6
===========================================================================================================================================
训练报错
python: /opt/conda/conda-bld/magma-cuda101_1572909250636/work/interface_cuda/interface.cpp:808: void magma_queue_create_internal(magma_device_t, magma_queue**, const char*, const char*, int): Assertion `queue->dBarray__ != __null' failed.
Aborted (core dumped)
I ran my code on GTX 1080. The GPU memory usage is 0 to 200 MB when nothing's running. However, after this error happened, the GPU memory usage went up to 700MB, and I have to restart the machine to free the memory, otherwise cuda will go out of memory when I run the same code again. I think there's memory leak in this bug.
https://github.com/pytorch/pytorch/issues/26120
Intel MKL ERROR: Parameter 4 was incorrect on entry to DLASCL.
解决:
conda install mkl==11.3.3
https://www.jianshu.com/p/4a74e6bee332



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











