






1、启动虚拟环境
![]()
2、安装langchain
![]()
![]()
3、安装相关依赖
pip install langchain pypdf rapidocr-onnxruntime modelscope transformers faiss-cpu tiktoken -i https://mirrors.aliyun.com/pypi/simple/4、indexer:
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import ModelScopeEmbeddings
from langchain_community.vectorstores import FAISS
# 解析PDF,切成chunk片段
pdf_loader=PyPDFLoader('LLM.pdf',extract_images=True) # 使用OCR解析pdf中图片里面的文字
chunks=pdf_loader.load_and_split(text_splitter=RecursiveCharacterTextSplitter(chunk_size=100,chunk_overlap=10)) #chunk_size表示每块的大小,chunk_overlap表示块和块的重叠部分大小
# 加载embedding模型,用于将chunk向量化
embeddings=ModelScopeEmbeddings(model_id='iic/nlp_corom_sentence-embedding_chinese-base')
# 将chunk插入到faiss本地向量数据库
vector_db=FAISS.from_documents(chunks,embeddings)
vector_db.save_local('LLM.faiss')
print('faiss saved!')注:如果报错ImportError: cannot import name 'get_metadata_patterns' from 'datasets.data_files'
解决:datasets版本不匹配导致,执行
pip install datasets==2.16.0 5、RAG :
注:在服务器上部署ollama过程
1、我在百度网盘下载的安装包,上传到服务器上
执行执行下面命令开始安装:
tar -C /usr -xzf ollama-linux-amd64.tgz如果报错:bash: sudo: command not foundapt-get updateapt-get install sudo
2、此时Ollama已经下载安装完成,在换另一个终端窗口执行
ollama serve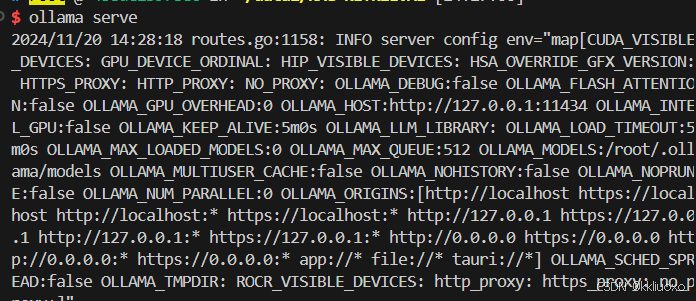
3、返回原终端窗口 启动Ollama服务。执行
ollama -v
查看Ollama服务是否成功启动。

4、想要实现外部访问需要修改其配置文件。
执行如下命令打开配置文件
sudo nano /etc/systemd/system/ollama.service
将如下内容复制到配置文件中:
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="OLLAMA_HOST=0.0.0.0:11434"
[Install]
WantedBy=default.target
修改完成后重启服务:
sudo systemctl daemon-reload
sudo systemctl enable ollama5、下载模型

完整代码
from langchain_community.embeddings import ModelScopeEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.memory import ChatMessageHistory
from langchain.prompts.chat import ChatPromptTemplate,SystemMessagePromptTemplate,HumanMessagePromptTemplate,AIMessagePromptTemplate,MessagesPlaceholder
from langchain.schema import HumanMessage,SystemMessage,AIMessage
from langchain_core.runnables import RunnablePassthrough
from operator import itemgetter
from langchain.llms import Ollama
# 加载embedding模型,用于将query向量化
embeddings = ModelScopeEmbeddings(model_id='iic/nlp_corom_sentence-embedding_chinese-base')
# 加载faiss向量库,用于知识召回
# FAISS.load_local加载一个名为LLM.faiss的本地向量数据库。这意味着我们预先将一些知识数据转化为向量并存储在这个库中。
vector_db = FAISS.load_local('LLM.faiss',embeddings,allow_dangerous_deserialization=True)
'''
as_retriever将vector_db转换为一个检索器对象(retriever),可以从中快速查找与输入向量(即query向量)相似的内容。
search_kwargs={"k":5}参数表示每次检索返回5条与query向量最相似的内容,这些内容将用于回答用户的问题。
'''
retriever = vector_db.as_retriever(search_kwargs={"k":5})
# 用Ollma部署本地大模型,我下载的是qwen:1.8b
chat = Ollama(
base_url='http://localhost:11434',
model="qwen:1.8b",
temperature=0.7,
stop=['<|im_end|>']
)
#Prompt模板
#system_prompt:定义系统的初始角色设定,使得模型明白自己是一个“乐于助人的助手”。
system_prompt = SystemMessagePromptTemplate.from_template('You are a helpful assistant.')
#user_prompt:定义用户问题的模板,包含{context}和{query}两个变量。context是从向量数据库中检索到的相关内容,query是用户的问题
user_prompt = HumanMessagePromptTemplate.from_template('''
Answer the question based only on the following context:
{context}
Question: {query}
''')
#构建多轮对话的完整提示
full_chat_prompt = ChatPromptTemplate.from_messages([system_prompt, MessagesPlaceholder(variable_name="chat_history"), user_prompt])
#构建对话链
'''
chat_chain定义了数据处理的步骤:
itemgetter("query") | retriever:从输入数据中提取query字段,并使用retriever检索与query相关的内容,将其作为context。
itemgetter("query")直接提取用户的query。
itemgetter("chat_history")提取多轮对话的chat_history。
| full_chat_prompt | chat:将处理后的数据输入full_chat_prompt,构造提示,然后传递给chat模型进行生成。
'''
chat_chain = {
"context": itemgetter("query") | retriever,
"query": itemgetter("query"),
"chat_history": itemgetter("chat_history"),
} | full_chat_prompt | chat
# 开始对话
chat_history = []
while True:
query = input('query:')
response_text = chat_chain.invoke({'query': query, 'chat_history': chat_history})
response = AIMessage(content=response_text)
chat_history.extend((HumanMessage(content=query), response))
print(response.content)
chat_history = chat_history[-20:] # 只保留最近10轮对话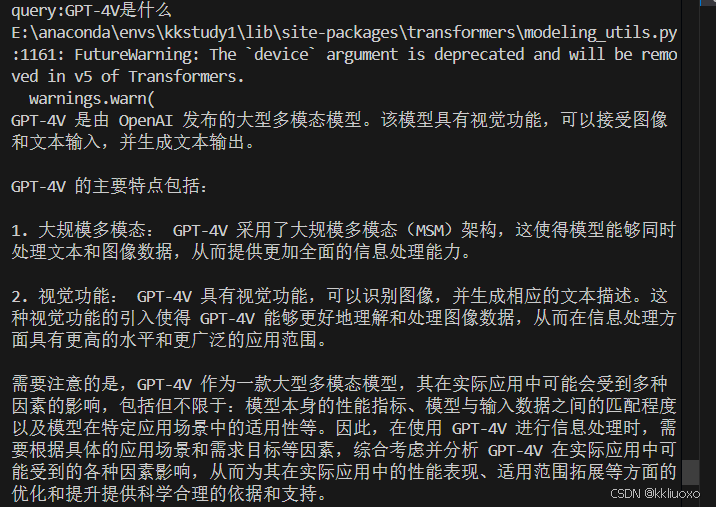

















 912
912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









