




 本文详细论述了《手搓神经网络——BP反向传播》中高级的BP反向传播部分。介绍了输入、权重与偏置的属性及计算,阐述了矩阵求导,包括x@w+b对w、x求导,激活函数对w、x求导。还讲解了前向计算和反向求导,涉及隐藏层和输出层的计算与参数更新。
本文详细论述了《手搓神经网络——BP反向传播》中高级的BP反向传播部分。介绍了输入、权重与偏置的属性及计算,阐述了矩阵求导,包括x@w+b对w、x求导,激活函数对w、x求导。还讲解了前向计算和反向求导,涉及隐藏层和输出层的计算与参数更新。
相关文章:
前言
本文是对于《手搓神经网络——BP反向传播》一文中高级的 BP 反向传播部分的详细论述
import numpy as np
import tensorflow as tf
输入,权重与偏置
输入,权重与偏置的属性
先来聊聊输入(x)、权重(w)、偏置(b)。无需再废话的是,这三者的类型都是数组numpy.ndarray
输入(x)
输入(x)的形状为(b, n),b表示 batch_size(批大小),n表示输入询量数据长度。下图表示 batch_size 为b的每个训练数据形状为(1, n)的训练集

输入矩阵中,x 上标表示此训练数据在一个批大小中的位置,x 下标表示第b个训练数据的第n个参数
权重(w)
权重(w)的形状为(n, m),n表示输入数据数量,m表示该层输出数据数量(即该层的神经元数量)
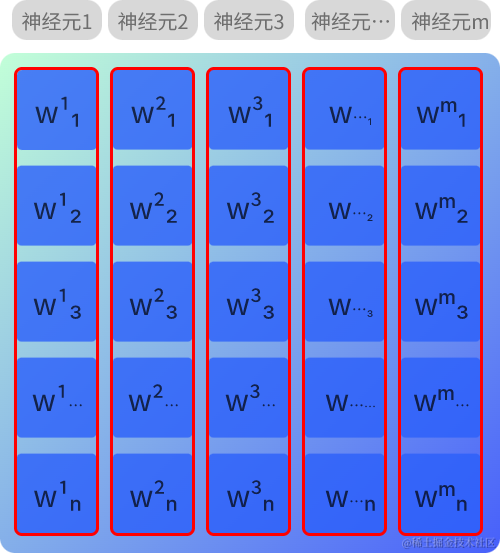
在全连接层中,每层的各个神经元相互交织连接。权重矩阵中,w 上标表示的是该层的第 m 个神经元,w 下标表示的是该层第 m 个神经元与第 n 个输入的联系
偏置(b)
偏置(b)的形状为(1, m),m表示该层输出数据数量(即该层的神经元数量),图中的 b1、b2、b3…分别表示神经元1、神经元2、神经元3…的偏置

输入,权重与偏置的计算
关于计算不多赘述,就是 x @ w + b x@w+b x@w+b ,在本文中@表示矩阵叉乘,用numpy表示即为x@w+b或者np.dot(x, w)+b,在将其计算结果带入激活函数,得到的即为神经网络层的输出,笔者认为前向运算的本质就是矩阵计算,反向传播的本质就是矩阵求导
矩阵求导
在输出层计算部分之前,单独论述下矩阵求导。主要论述x@w+b 对 w 求导与激活函数对 x@w+b 的求导
x@w+b 对 w 求导
下面有一个x@w+b表达式,嚯!看着挺复杂的,实则是笔者这里写的详细了些,与其说复杂倒不如是繁琐
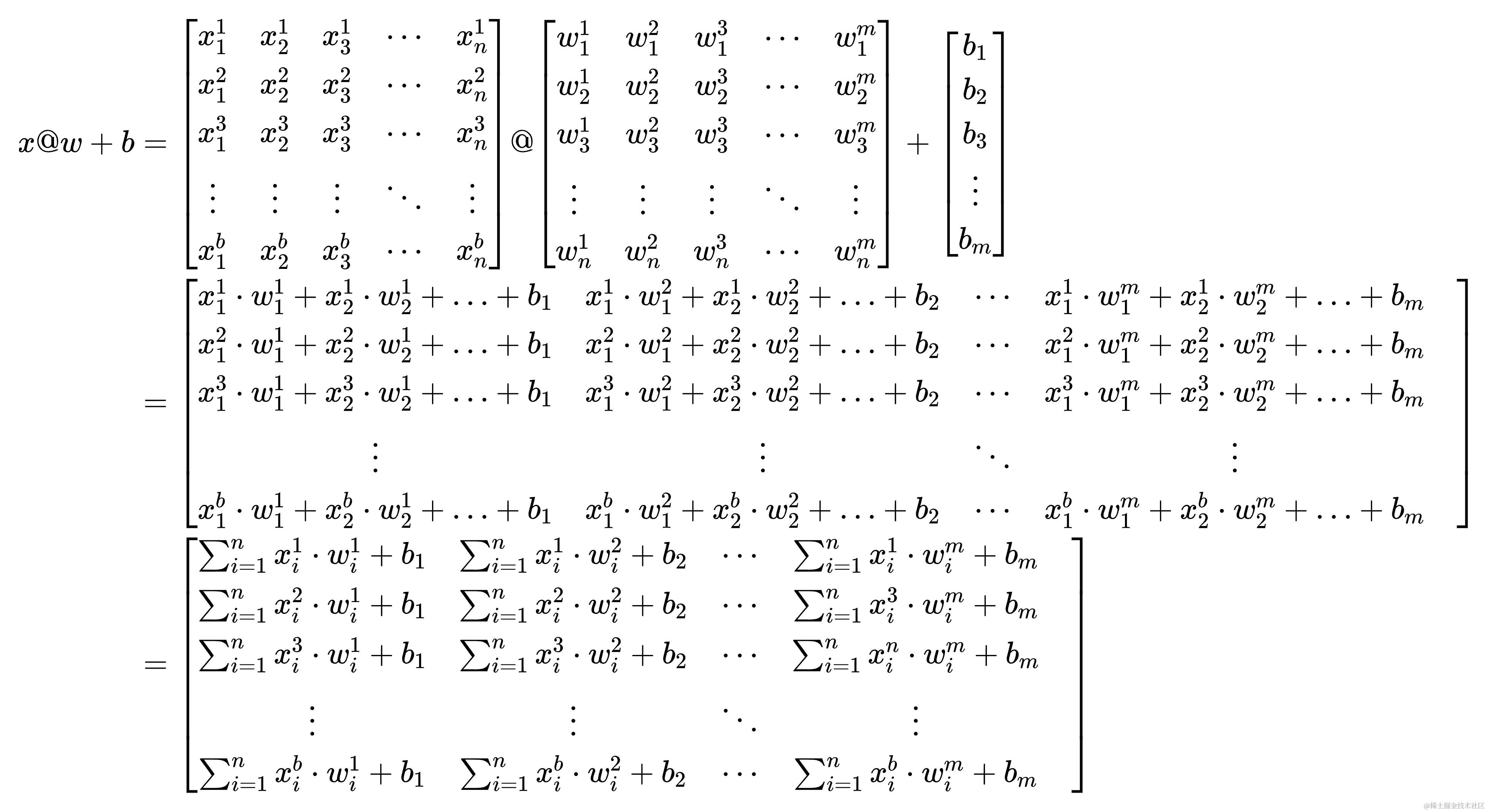
接下来,加一点魔法🪄,让x@w+b叉乘✖一个形状为(m, 1)的全一矩阵(矩阵里全是一①Ⅰ壹),m与权重(w)中m的含义相同。将这个矩阵记作 α 1 \alpha_{1} α1。哈哈,好像高中写数学题,要化简时经常要用到神奇的1
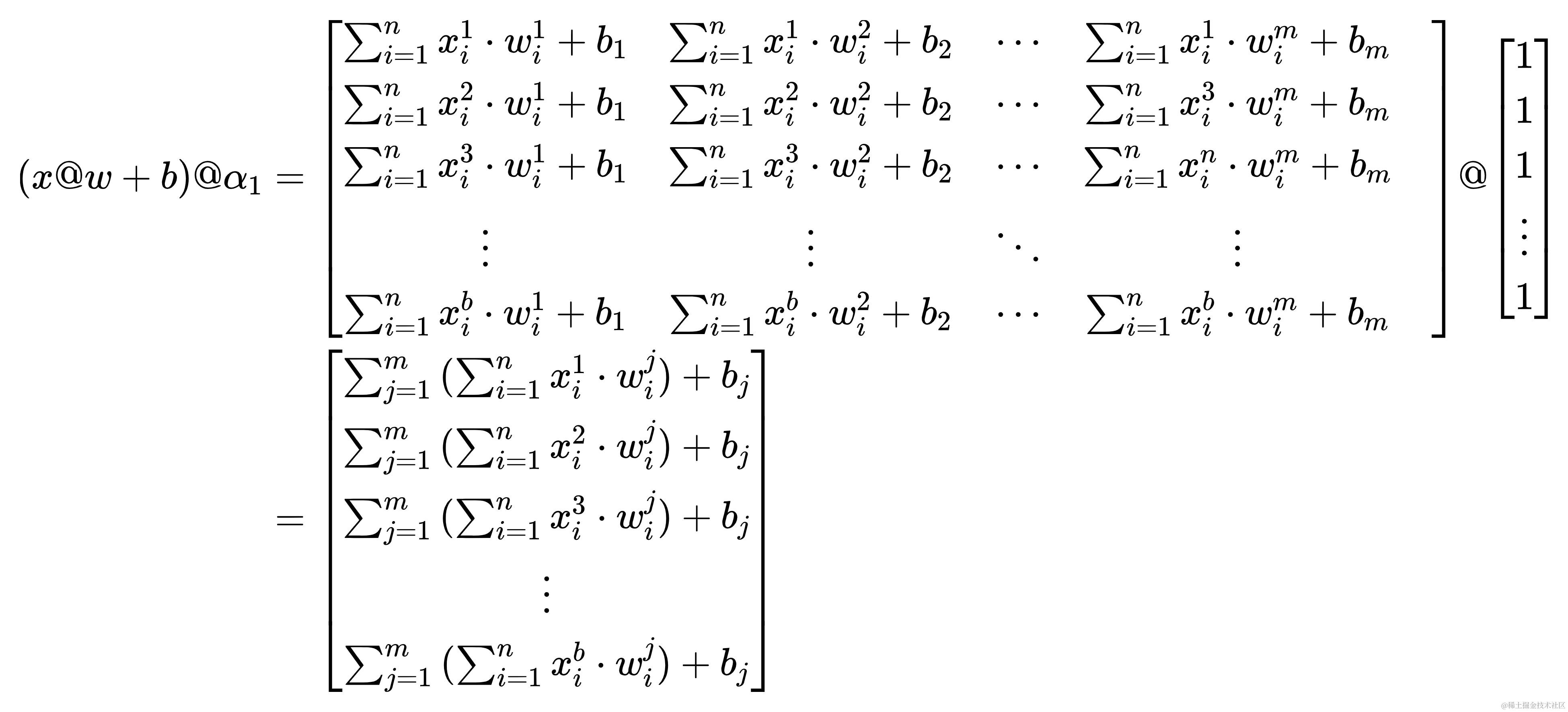
这样子,得出的结果看着就简洁多了。然后如法炮制,只不过是让一个形状为(1, b)的全一矩阵叉乘✖ ( x @ w + b ) @ α 1 (x@w+b)@\alpha_{1} (x@w+b)@α1,将这个矩阵记作 α 2 \alpha_{2} α2。哈哈哈,汗流浃背了吧,兄弟😅,你八成是看傻了,我两成是写傻了
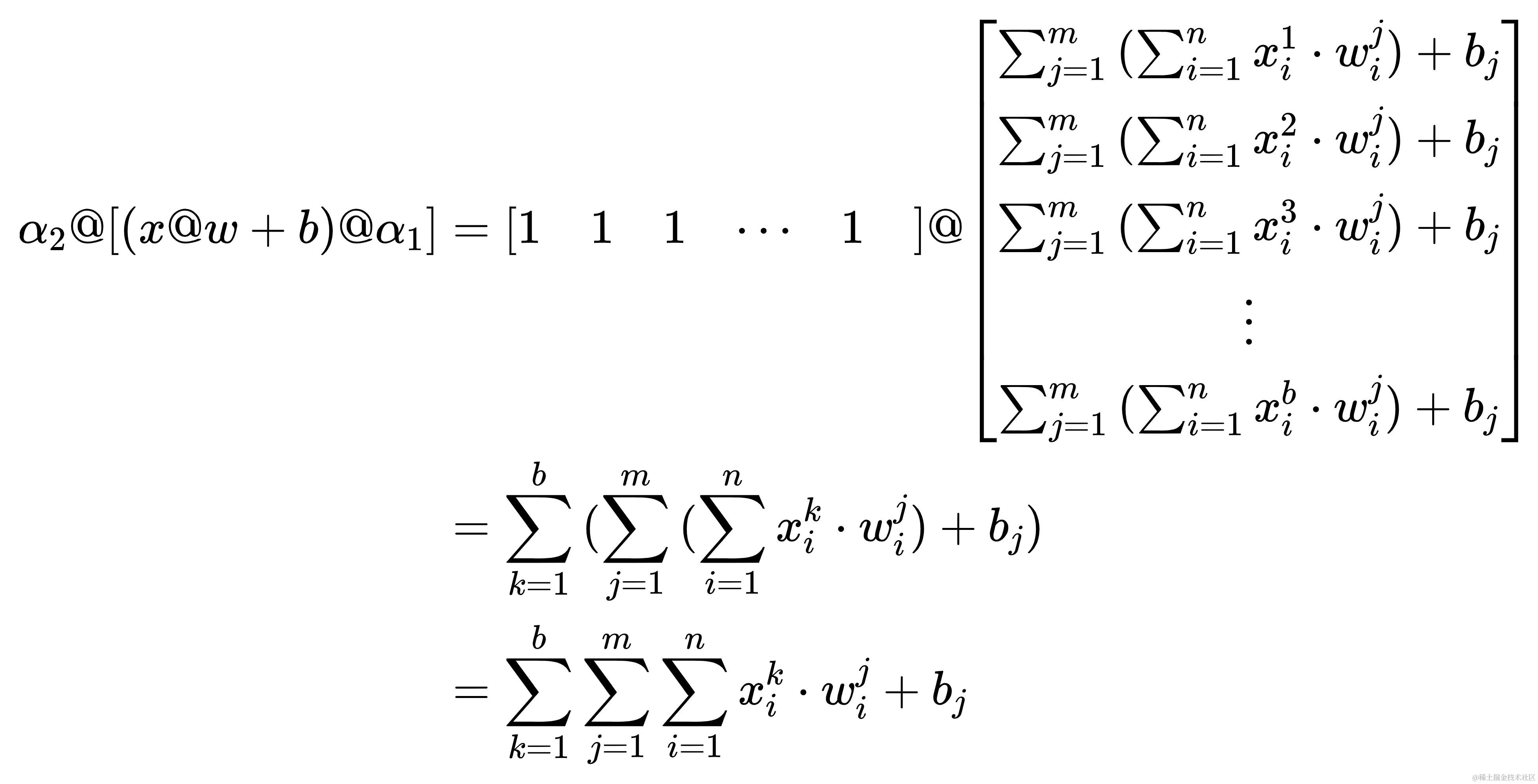
经过一坨又一坨的变换,最终以一个标量的表达式来表示最初的x@w+b( α 1 \alpha_{1} α1 与 α 2 \alpha_{2} α2 是为了化简成上方的形式而存在的,之所以要化简成上方形式是为了使表达式更简洁,也是为了便于对w求导)
计算 ∑ k = 1 b ∑ j = 1 m ∑ i = 1 n x i k ⋅ w i j + b j \sum_{k=1}^{b}{\sum_{j=1}^{m}{\sum_{i=1}^{n}{x_{i}^{k} \cdot w_{i}^{j}} + b_{j}}} ∑k=1b∑j=1m∑i=1nxik⋅wij+bj 对 w i j w_{i}^{j} wij 的导数
d y d w i j = d d w i j ∑ k = 1 b ∑ j = 1 m ∑ i = 1 n x i k ⋅ w i j + b j = ∑ k = 1 b x i k \frac{\mathrm{dy}}{\mathrm{d}w_{i}^{j}} = \frac{\mathrm{d}}{\mathrm{d}w_{i}^{j}} \sum_{k=1}^{b}{\sum_{j=1}^{m}{\sum_{i=1}^{n}{x_{i}^{k} \cdot w_{i}^{j}} + b_{j}}} = \sum_{k=1}^{b}{x_{i}^{k}} dwijdy=dwijdk=1∑bj=1∑mi=1∑nxik⋅wij+bj=k=1∑bxik
自此长篇大论得出的结论,x@w+b对w的导数表示成矩阵形式为
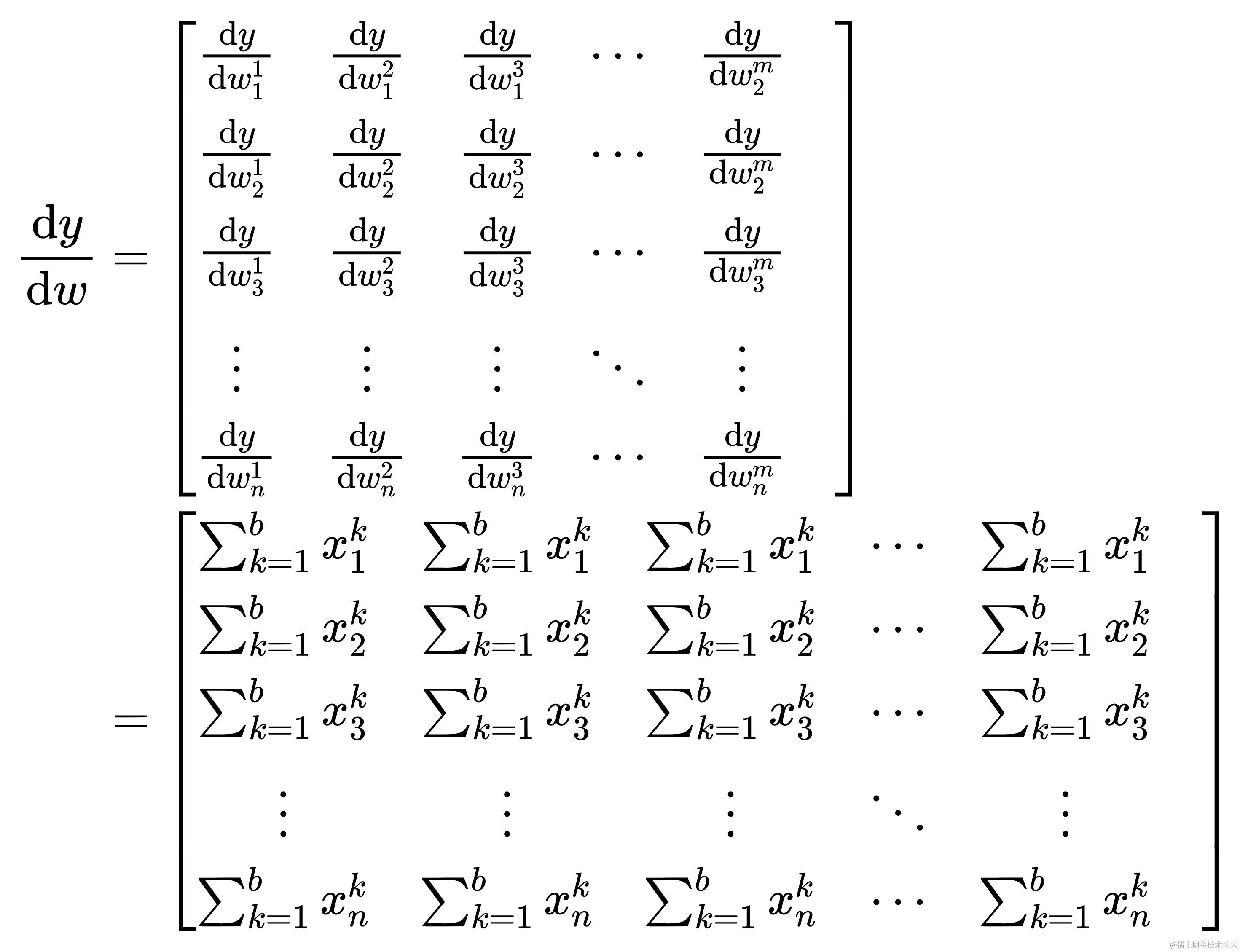
可以看得出x@w+b 对 w 的导数为 x 矩阵转置的行之和,且重复扩展成原形状(不是哥,你要问我怎么看出来是转置的?熟读并抄写10遍上文,还不晓得?熟读全文并背诵)
上面的话似乎有些难以理解,来点魔法。将形状为(b, m)全一矩阵记作 α 3 \alpha_{3} α3,用数学的语言表达如下
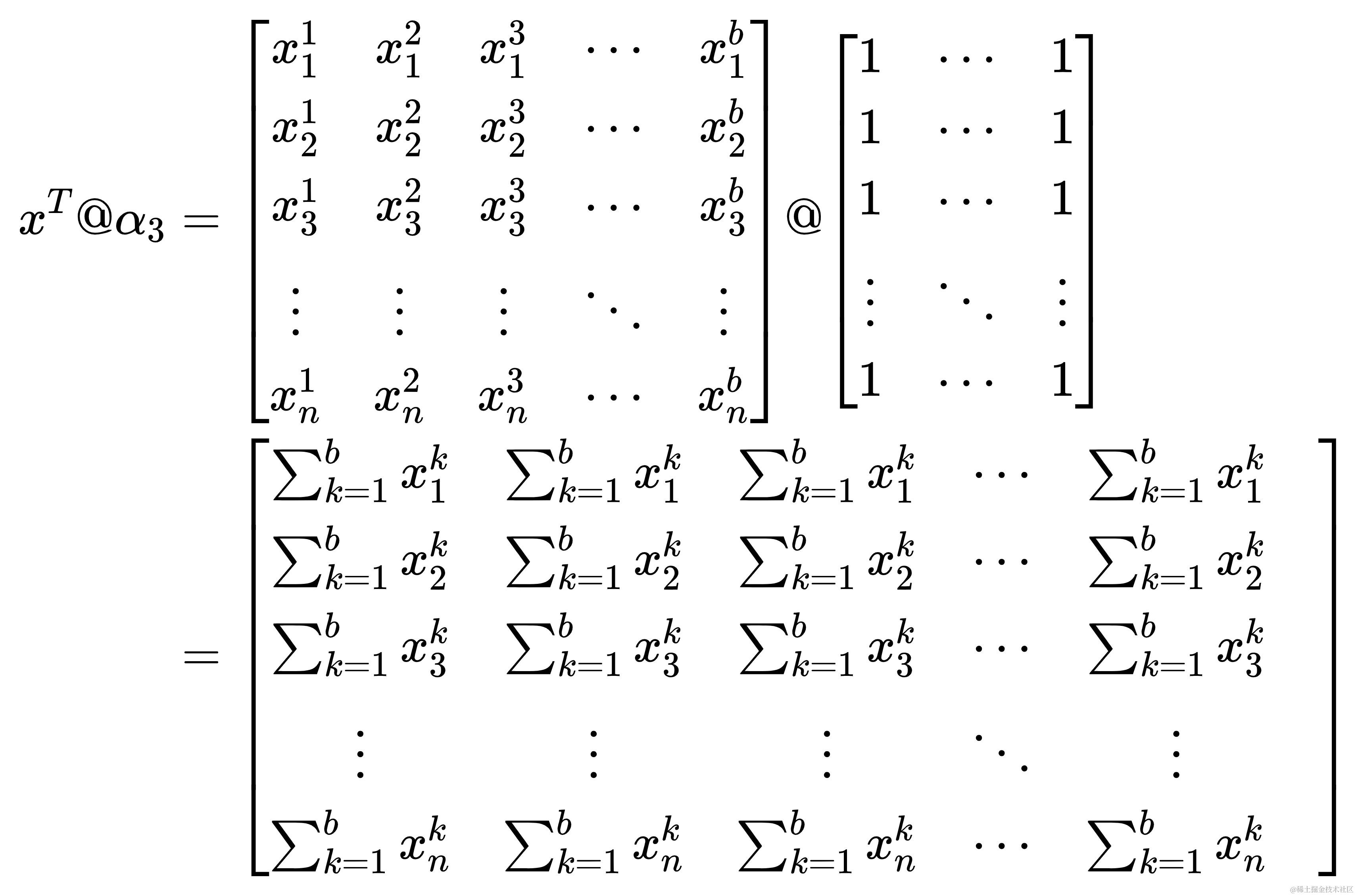
α 3 \alpha_{3} α3 的应用实现了两个功能,即上文所述的求行之和与重复扩展
- 求行之和:在矩阵叉乘中,可视为 x T x^{T} xT 的行与 α 3 \alpha_{3} α3 的列的点乘求和
- 具体来说, x T @ α 3 x^{T}@\alpha_{3} xT@α3 的结果是一个列向量,其第 i 个元素是 x T x^{T}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 346
346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











