



GLaMM: Pixel Grounding Large Multimodal Model
Abstract
大型多模态模型(Large Multimodal Model, LMM)将大语言模型扩展到视觉领域。最初的LMM使用整体图像和文本提示词来生成无定位的文本响应。最近,区域级LMM已被用于生成视觉定位响应。然而,它们仅限于一次仅引用单个目标类别,要求用户指定区域,或者不能提供密集的像素目标定位。在这项工作中,我们提出了Grounding LMM (GLaMM),这是第一个可以生成与相应的目标分割掩码无缝交织的自然语言响应的模型。GLaMM不仅将对话中出现的目标作为定位,而且足够灵活,可以接受文本和可选的视觉提示词(感兴趣的区域)作为输入。这使得用户能够在文本和视觉领域中以不同的粒度级别与模型进行交互。
由于缺乏新的视觉定位对话生成(Grounded Conversation Generation, GCG)设置的标准基准,我们引入了一个全面的评估协议,用于我们策划的定位对话。我们提出的GCG任务需要大规模的自然场景中的密集概念。为此,我们使用我们提出的自动注释流水线提出了一个密集注释的定位任何数据集(Grounding-anything Dataset, GranD),该数据集包括7.5M个独特的概念,这些概念定位总共810M个可用的分割掩码区域。除了GCG,GLaMM还可以有效地执行一些下游任务,例如引用表达分割、图像和区域级说明文字以及视觉-语言对话。
- Introduction
我们提出了一个自动流水线来注释大规模的定位一切数据集(GranD),以减轻手动标记的工作量。利用具有专用验证步骤的自动化流水线,GranD包括7.5M个独特概念,锚定在810M个区域,每个区域都有一个分割掩码。使用最先进的视觉和语言模型,数据集通过提高注释质量的多级层次方案对SAM [18]图像进行注释。凭借1100万张图片、8400万个参考表达和3300万个定位说明文字,GranD在综合性方面树立了新的标杆。
除了为GCG自动生成的数据集外,我们还提供了第一个高质量的定位对话数据集,该数据集是通过使用GPT-4 [34]上下文学习对GCG的现有手动注释数据集[16, 37, 49]进行修改而获得的。我们将高质量数据集称为GranDf,表示其适用于微调。
我们的工作有三个主要贡献:
- 我们提出了GLaMM,这是第一个能够生成与目标分割掩码无缝集成的自然语言响应的模型。与现有模型不同,GLaMM适应文本和视觉提示词,促进增强的多模态用户交互。
- 提出了新的定位对话生成(GCG)任务。我们还引入了一个综合评估协议来衡量GCG模型的功效,该协议统一了多个孤立的任务,填补了文献中的一个重大空白。
- 为了便于模型训练和评估,我们创建了定位一切数据集(GranD),这是一个大规模的密集注释数据集。它使用自动注释流水线和验证标准开发,涵盖了810M个区域的7.5M个独特概念。此外,我们提出了GranDf,这是一个明确设计用于GCG任务微调的高质量数据集,通过重新利用现有的开源数据集。
- Method
现有的大型多模态模型(LMM):生成未定位的文本;单目标定位;用户指定的区域输入;缺乏密集像素级目标定位。
Grounding LMM (GLaMM)旨在通过生成与目标分割掩码无缝集成的自然语言响应来克服这些限制。这使得可以进行直观的人机对话。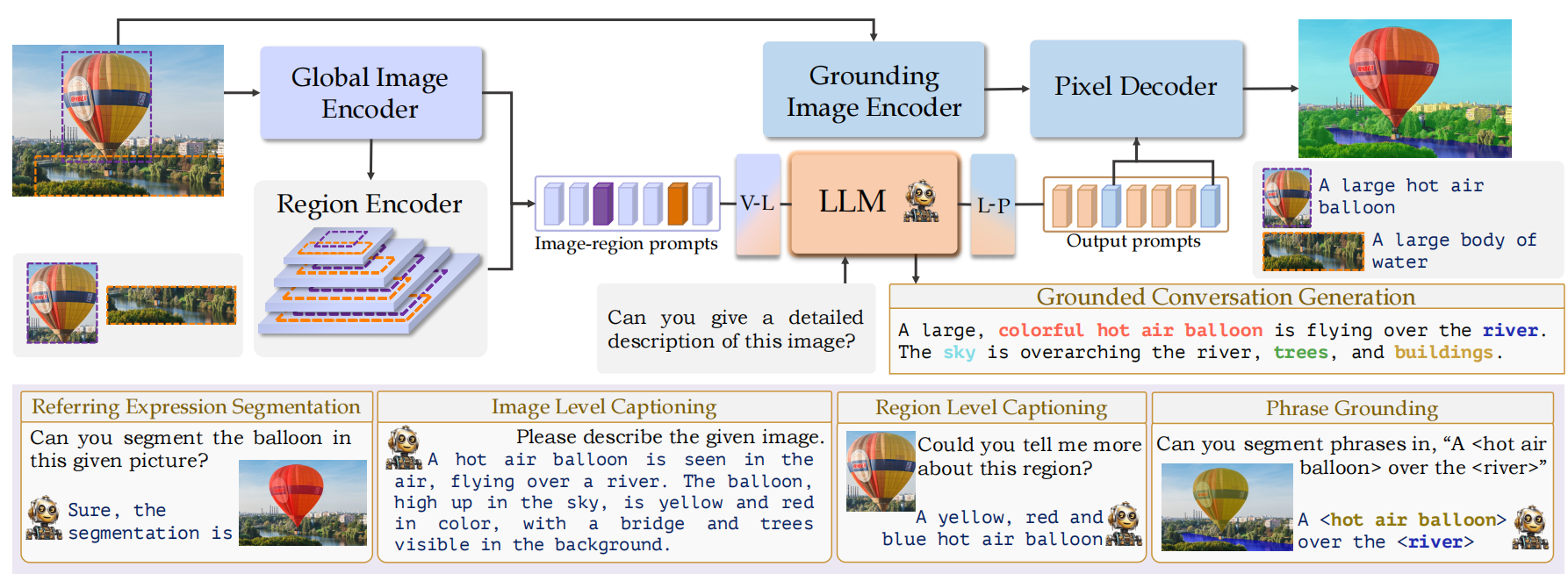 图2. GLaMM的架构。该图展示了模型架构,展示了其提供场景级理解、区域级解释和像素级定位的能力。顶部:GLaMM的核心组件,包括全局图像编码器、区域编码器、LLM、定位图像编码器和像素解码器,都是为不同粒度的视觉-语言任务量身定制的。
图2. GLaMM的架构。该图展示了模型架构,展示了其提供场景级理解、区域级解释和像素级定位的能力。顶部:GLaMM的核心组件,包括全局图像编码器、区域编码器、LLM、定位图像编码器和像素解码器,都是为不同粒度的视觉-语言任务量身定制的。
视觉到语言(V-L)投影层有效地将图像特征映射到语言域中,像素解码器利用语言到提示词(L-P)投影层,将与分割相关的文本嵌入转换到解码器空间中。GLaMM的一个主要功能是它能够执行我们新引入的定位会话生成(GCG)任务。这突出了模型将特定短语锚定到图像中相应分割掩码的能力。
3.1. GLaMM Architecture
GLaMM由五个核心组件组成:i) 全局图像编码器,ii) 区域编码器,iii) LLM,iv) 定位图像编码器,以及v) 像素解码器。这些组件经过一致设计,可以处理文本和可选的视觉提示词(图像级别和区域),允许在多个粒度级别进行交互,并生成定位文本响应(见图2)。如下面所解释的,这些模块共同保证场景级、区域级和像素级定位。训练细节详见附录A.2。
场景级理解:为了实现对场景的整体理解,我们使用ViT-H/14 CLIP [38]作为我们的全局图像编码器(),并结合基于Vicuna的LLM ()和视觉到语言(V-L)投影层(f)。具体地,给定图像ximg和文本指令xt,首先将图像编码为特征向量,并投影到语言空间。然后,LLM集成投影图像特征和文本指令以生成输出yt:
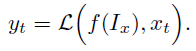
这将图像特征映射到语言空间,使GLaMM能够提供全面的场景理解,通过特定的提示词实现,如"The provides an overview of the image. Could you please give me a detailed description of the image?" token被CLIP全局图像编码器的256个token取代。
区域级理解:此组件从四个选定的CLIP全局图像编码器层构建层次特征棱锥体,然后通过RoIAlign [10]生成14x14的特征图。将这些特征组合在一起可以产生一个统一的兴趣区域(RoI)表征。为了促进在GLaMM中针对区域的响应,我们使用一个专用token 来扩充现有的词汇表。这被集成到提示词中,比如"The provides an overview of the image. Can you provide a detailed description of the region ?"。此处 token被替换成提取的RoI特征。
为了区域级理解,除了全局图像特征Ix,我们还将用户指定的区域 r 作为输入,写作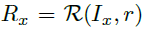
,然后通过与场景级理解中使用的相同V-L投影层 f 投影到语言空间。我们通过用相应的区域特征替换 token来扩充文本指令xt,以获得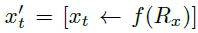
。LLM然后生成输出yt,
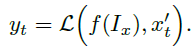
像素级定位:GLaMM利用定位图像编码器(表示为V)和像素解码器(表示为P),促进了细粒度的像素级目标定位,使其能够在视觉上定位其响应。我们用预训练的SAM编码器[18]实例化V,并基于类似SAM解码器的架构设计。为了激活像素级定位,我们模型的词汇表使用专用token 进行扩充。提示词,如"Please segment the ‘man in red’ in the given image," 触发模型生成带有相应 token的响应。一个**语言到提示词(L-P)投影层(g)**将对应于 token的最后一层嵌入(lseg)转换到解码器的特征空间。随后,P产生二值分割掩码M,
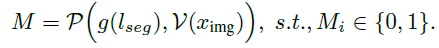
使用端到端的训练方法,GLaMM在区域理解、像素级定位和会话能力方面表现出色。然而,由于缺乏生成视觉定位详细对话的新设置的标准基准,我们引入了一个新任务,即视觉定位对话生成(GCG),以及一个全面的评估协议,如下所述。
3.2. Grounded Conversation Generation (GCG)
GCG任务的目标是构建图像级说明文字,其中特定短语直接绑定到图像中相应的分割掩码。
GCG输出表征:在这个任务中查询模型的示例提示词是:“Could you please give me a detailed description of the image? Please respond with interleaved segmentation masks for the corresponding parts of the answers.” 该模型生成了一个详细的说明文字和交错的分割掩码。我们使用特殊的token来分别描绘每个短语的开始和结束以及相应的区域掩码。
评估标准:我们为GCG引入了一个基准套件,其中包括2.5K幅图像的验证集和5K幅图像的测试集。评估了四个关键方面:i) 生成的密集说明文字质量,ii) 掩码到短语的对应精度,iii) 生成的掩码质量,以及iv) 区域特定的定位能力。指标包括说明文字的METEOR和CIDEr,定位的类不可知掩码AP,分割的掩码IoU,以及区域特定定位的掩码recall。

4. Data Annotation Pipeline
该流水线包含四个不同的级别(见图4)。
i) Level-1专注于目标定位,并提供语义标签、分割掩码、属性和深度信息。
ii) Level-2定义了检测目标之间的关系。
iii) Level-3将前两级的信息组织成分层场景图,用于使用LLM和上下文中的示例生成密集说明文字。
iv) Level-4提供了丰富的上下文信息,以加深对场景的理解,超越了观察到的内容(例如,地标的历史信息)。
4.1. Object Localization and Attributes (Level-1)
在Level-1中,重点是图像中的详细目标识别。首先,使用多个SoTA目标检测模型来识别目标边界框。将类无关NMS应用于每个模型,以滤除假阳。在该步骤之后,使用IoU来比较来自不同模型的边界框,其中仅当边界框被至少两个其他检测模型检测到时,边界框才被保留为目标。我们还使用基于区域的视觉-语言模型为每个过滤后的目标生成属性,并结合深度信息来将每个目标在场景中的相对位置情境化。
4.2. Relationships and Landmarks (Level-2)
在Level-2中,生成整个场景的多个简短文本描述。从这些描述中提取的短语定位Level-1中的特定目标,以形成关系。这些关系阐明了多个目标之间的连接,或定义了目标在场景中的角色。此外,每个场景都被分配了一个地标类别,包括一个主要类别和一个更具体的子类别(见附录7中的表7)。
4.3. Scene Graph and Dense Captioning (Level-3)
在Level-3中,来自Level-1的目标属性和标签与从Level-2获得的关系和短语相结合,形成分层场景图。这些结构化数据作为大型语言模型生成密集图像描述的输入。为提供更丰富的上下文信息,系统通过深度值和边界框坐标将每个物体定位到场景中的特定空间层级,包括前景、中景、背景等。同时,场景图中还融入了简短的场景描述,以增强语言模型对上下文的理解能力。
密集说明文字验证:为了提高LLM生成的密集说明文字的精确性,我们使用思想链提示实现了一个自动验证流水线。该流水线生成了一个目标检查表,这些目标来自生成的密集说明文字(预计会出现在图像中)。如果场景图中没有检查表中指定的任何目标,则相关联的说明文字将被标记为不准确。然后重新生成这样的说明文字,并将初始评估的反馈纳入其中。
4.4. Extra Contextual Insights (Level-4)
第四级在第三级场景图基础上进行升级,以获得更细致的视觉理解。我们通过调用大语言模型(LLM),不仅提取基础对象识别和关系,还获取扩展的上下文信息,包括地标详情、历史背景、场景互动指南,甚至对未来事件的预测。为此,我们通过上下文示例引导大语言模型进行提示。
利用我们的自动注释流水线,我们注释了11M幅SAM图像[18]的语料库,这些图像具有固有的多样性、高分辨率和隐私兼容性。所得到的数据集包括810M个区域,每个区域与分割掩码相关联,并且包括7.5M个独特的概念。此外,数据集以84M个引用表达、22M个定位短说明文字和11M个密集定位说明文字为特征。据我们所知,这是第一个完全通过自动注释流水线生成的这种规模的数据集(详见表2,数据集样本可视化见图15)。
4.5. Building GranDf for GCG
由于在微调阶段需要更高质量的数据,我们引入了GranDf。它包含214K个图像定位文本对和2.5K个验证和5K个测试样本。GranDf包括两个主要组件:一个子集是手动注释的,另一个子集通过重新利用现有的开源数据集来派生。
我们通过生成兼容的GCG标注扩展了开源数据集——具体包括Flickr-30K[37]、RefCOCOg[16]和PSG[49]。
针对RefCOCOg数据集,我们采用其包含的指代表达式及其对应的连接掩码。这些表达式能简洁描述图像中不同物体的特征。借助GPT-4模型,我们将这些指代表达式与COCO标注的上下文信息无缝融合,生成既详细又精准的定位标注,同时保留原始指代表达式。这种技术确保了短语与对应分割掩码的匹配零误差,最终获得约24K个GCG样本。
对于PSG数据集,我们利用其描述场景中两个物体关系的三元组结构,通过GPT-4将这些三元组与COCO标注整合,生成可精准映射到分割掩码的密集标注文本,新增约31K个GCG样本。
在Flickr-30K数据集方面,我们采用158K条Flickr标注及其对应的指代表达式和边界框,通过HQ-SAM[17]算法实现边界框的精准分割。
此外,我们还提供了一个小型但高质量的手动标注集,用于评估GCG任务。基于GranD的自动标注结果,标注人员对指代表达式进行优化,使其与SAM GT掩码匹配,最终获得约1000个训练样本和1000个评估样本。
- Conclusion
我们介绍了GLaMM,这是第一个能够生成与目标分割掩码交织的自然语言响应的模型,允许增强多模态用户交互。认识到缺乏视觉定位对话的标准化基准,我们引入了定位对话生成的新任务,并建立了一个全面的评估协议。为了促进研究和模型开发,我们创建了定位一切数据集(GranD),这是一个大规模的、注释密集的数据集,包含810万个区域的750万个独特概念。我们的自动化注释流水线确保了用于我们模型的数据集的可靠性和可扩展性。除了这些贡献之外,我们还利用现有的开源数据集,创建了一个专门为GCG任务量身定制的数据集(GranDf),建立了一个高质量的微调数据集,以开发视觉定位对话。我们的模型在除了GCG之外的下游任务上表现良好,包括区域和图像说明文字、引用分割和视觉-语言对话。
Supplementary Material
A. Additional Implementation Details
A.1. Evaluation Metrics
掩码召回:为了量化区域特定定位,我们利用两层验证方法提出了一个“掩码召回”指标。最初,预测掩码通过一对一的集合分配映射到真正事实掩码,然后对这些对进行IoU计算。超过0.5 IoU阈值的对使用BERT进行文本相似性评估。只有当IoU和BERT相似度都超过其0.5阈值时,一对才被认为是真阳性(TP);否则,它被分类为假阳性(FP)。随后使用标准公式计算掩码召回,通过总真正事实掩码计数对TP的数量进行归一化。
A.2. Model Architecture and Training
在我们所有的实验中,我们使用了具有7B参数的Vicuna LLM [60]。区域编码器的设计灵感来自GPT4RoI [57],定位图像编码器和像素解码器的设计灵感来源于LISA [21]。V-L和L-P层使用具有GELU激活的2层MLP来实现,如LLaVA-v1.5 [28]中所述。我们使用PyTorch来实现我们的GLaMM,并在训练期间使用Deepspeed zero-2优化。
具体来说,我们的模型是使用两种类型的损失来训练的:用于文本生成的自回归交叉熵损失和用于分割的每像素二值交叉熵损失与DICE损失的线性组合。在训练过程中,全局图像编码器和定位图像编码器保持冻结,区域编码器、投影层(V-L和L-P)和像素解码器被完全微调,而LLM被LORA微调(α=8)。我们的代码和预训练模型将公开发布。
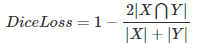
A.2.1 Pretraining on GranD
在预训练过程中,GLaMM在GranD数据集上进行训练,同时用于引用表达分割、区域级说明文字、图像级说明文字和定位会话生成(GCG)任务。我们使用160的批大小,并在预训练期间训练总共35K次迭代。我们使用LORA-8来有效地调整LLM,并初始化来自GPT4RoI [57]的预训练以更快地收敛。在第5节的实验表中,我们将该模型称为GLaMM (ZS),它是在GranD上预训练后获得的。
A.3. Finetuning on Downstream Tasks
我们在多个下游任务上微调GLaMM,包括GCG、引用表达分割、区域级说明文字和图像级说明文字。对于GCG,我们在GranDf数据集上微调我们的模型。使用160的批量大小,并且对模型进行总共5K次迭代的训练。值得注意的是,GranDf数据集是多个开源数据集的组合,我们使用GPT4 [34]将其重新用于GCG任务。请参阅附录D用于查询GPT4以构建GranDf数据集的提示词,以及数据集可视化。
对于引用表达分割,我们在refCOCO、refCOCO+和refCOCOg数据集上微调GLaMM。我们在表4中将该模型表示为GLaMM (FT)。类似地,对于区域级说明文字,GLaMM (FT)在refCOCOg和Visual Genome数据集上进行了微调。对于图像级说明文字,我们在LLaVA-Instruct150K [29]数据集上微调GLaMM。对于LLaVA-bench,该模型在LLaVA-Instruct-80K [29]指令集上进行了微调。我们在所有预训练和微调实验中使用了八个NVIDIA A100-40GB GPU。
A.4. Automated Dataset Annotation Pipeline
我们的自动化注释流水线包含了不同级别的各种最先进的模型。对于Level-1,我们使用Tag2Text [14]和RAM [58]进行图像标记,使用CoDETR [62]、EVAv02 [7]、OWL-ViT [33]和POMP [40]进行目标定位,使用GRiT [48]和GPT4RoI [57]进行属性生成,使用MiDAS [39]进行深度估计。Level-2利用BLIP-2 [24]和LLaVA-v1.5 [28, 29]进行场景描述和地标分类,利用SpaCy [11]进行短语提取,利用MDETR [15]进行短语定位。对于Level-3和Level-4,我们使用具有13B参数的Vicuna-v1.5 [60],并辅以上下文示例。有关在不同流水线级别上使用的实现和LLM提示词的更多详细信息,请参阅附录A.4。
我们设计了一个全自动的数据集注释流水线,使用视觉域中的多个层次来构建GranD数据集。通过将我们检测到的标记区域与SAM提供的类不可知区域进行比较,可以从SAM [18]注释中获得大多数区域的分割掩码。对于与任何SAM区域都不匹配的其余区域,我们使用边界框查询运行SAM模型以获得掩码。
我们的自动注释流水线仅使用开源模型,并通过LLM使用思想链进行提示。由于它不需要来自回路中的人的反馈,因此可以对其进行缩放以生成大量图像的密集噪声标签,然后可以使用这些标签来预训练更大的LMM。如果有足够的计算能力,这可能是朝着构建更大的通用大型多模态模型迈出的一步。我们将发布我们的GranD数据集,同时实现我们的自动数据集注释流水线,以供进一步研究。下面我们将介绍我们在自动化数据集注释流水线的不同级别使用的LLM提示词。
A.4.1 LLM Prompts and In-context Learning
地标分类:我们使用LLaVA-v1.5-13B [28]模型为每个图像分配地标类别。所使用的主要和精细类别请参见表7。
密集说明文字:我们分层排列目标、属性和关系,构建一个视觉场景图,用于查询Vicuna-v1.5-13B [60]模型以及上下文示例,以生成密集说明文字。设计的提示如图6(a)所示。
额外上下文:我们查询Vicuna-v1.5-13B模型以生成关于视觉场景的额外上下文。为此目的设计的提示词如图6(b)所示。
B. Additional Downstream Tasks
B.1. Phrase Grounding
为了使GLaMM模型适应短语定位,我们重新调整了GCG数据集的用途,以适应这一特定任务。具体来说,GCG数据集中的答案现在被用作问题,说明文字中包含定位的部分被视为短语。随后对模型进行训练,以定位这些短语的像素级定位,这些短语包含在
和
token中。这种调整的结果如下图所示。B.2. Conversational Style Question Answering
我们在LLaVA-Bench [28, 29]上评估我们的模型,该基准使用GPT-4来评估模型。该基准测试在三种不同类型的任务上测试该模型:会话问答、详细描述和复杂推理任务。该评估提供了对模型对话和推理能力的深入了解。
表8中的结果将GLaMM与以前的开源模型进行了比较。我们注意到,GLaMM的性能与最近发布的LLaVA-1.5不相上下,后者利用额外的数据实现视觉到语言的对齐。定性结果如图11和图13所示。

















 1299
1299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









