




 本文介绍Rapids、Vaex和Dask等工具如何利用GPU和多核CPU加速大规模数据分析流程,覆盖数据转换、读取和分析等多个环节。
本文介绍Rapids、Vaex和Dask等工具如何利用GPU和多核CPU加速大规模数据分析流程,覆盖数据转换、读取和分析等多个环节。
1. Rapids
Rapids是英伟达推出的一款GPU加速平台:https://rapids.ai/。RAPIDS开源平台的核心是一套CUDA加速库,用于基于GPU的分析、机器学习和数据可视化。一个最典型的大数据分析流程大致分为数据准备、数据合并和数据降维三个步骤。RAPIDS构建于Apache Arrow、PANDAS和SKLEARN等开源项目上,通过cuDF数据过滤、cuML机器学习以及cuGRAPH数据图像化来加速处理数据,为最流行的Python数据科学工具链带来了GPU提速。
如果用户正在使用ML算法,包括但不限于XGBoost, K-NN, K-means, Random Forest, Gradient Boosted Decision Trees(GBDT), General线性模型以及DBSCAN等,将特别适合使用RAPIDS进行加速。
当数据量比较大的时候,Rapids可以和后面的dask进行结合。
1.1 CuPy:用GPU加速Numpy
import cupy as cp
N = 10 ** 7
data = cp.random.uniform(-1, 1, size=(N, 2))
inside = (cp.sqrt((data ** 2).sum(axis=1)) < 1).sum()
pi = 4 * inside / N
print('pi: %.5f' % pi)
在GPU上仅用640us,在cpu上需要用757ms,提升效果异常显著。
1.2 cuDF:用 GPU 加速 pandas
将 import pandas as pd 替换成 import cudf,GPU 内部如何并行,CUDA 编程这些概念,用户都不再需要关心。这里cudf可以用mars来代替。
import cudf
ratings = cudf.read_csv('ml-20m/ratings.csv')
ratings.groupby('userId').agg({'rating': ['sum', 'mean', 'max', 'min']})
运行时间从 CPU 上的 18s 提升到 GPU 上的 1.66s,提升超过 10 倍。
1.3 RAPIDS cuML:用 GPU 加速 scikit-learn
同样是 k-最邻近问题。
import cudf
from cuml.neighbors import NearestNeighbors
df = cudf.read_csv(‘data.csv’)
nn = NearestNeighbors(n_neighbors=10)
nn.fit(df)
neighbors = nn.kneighbors(df)
运行时间从 CPU 上 1min52s,提升到 GPU 上 17.8s。
2. Vaex
vaex是一种具有超级字符串功能的DataFrame Python库
字符串操作是数据科学的重要组成部分。Vaex的最新版本为所有常见的字符串操作添加了令人难以置信的速度和内存利用效率。与Pandas(Python生态系统中最受欢迎的DataFrame库)相比,四核笔记本电脑上的字符串操作速度提高了约30-100倍,而32核设备上的字符串操作速度提高了1000倍。
Vaex的特长在于字符串。由于Pandas字符串操作不释放GIL,因此Dask无法有效地使用多线程。围绕GIL的方法是使用Dask中的进程。然而,与Pandas相比,这使得操作速度减慢了40倍,与Vaex相比,它放慢了1300倍。大部分时间都花在pickling和unpickling字符串上。
Pandas将按每秒数百万字符串的顺序进行(并且不会缩放)
Spark将以每秒1000万个字符串的顺序执行(并且将随着核心数量和计算机数量而扩展)。
Vaex每秒可以处理大约1亿个字符串,并且会随着核心数量的增加而扩展。在32核机器上,我们每秒可以获得10亿个字符串。
2.1 数据转换
使用纽约市(NYC)出租车数据集,其中包含标志性的黄色出租车在2009年至2015年之间进行的超过10亿次出行的信息。数据可以从网站(https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page)下载,并且为CSV格式。
第一步是将数据转换为内存可映射文件格式,例如Apache Arrow,Apache Parquet或HDF5。在此处也可以找到如何将CSV数据转换为HDF5的示例。
2.2 数据读取
数据变为内存可映射格式后,即使在磁盘上的大小超过100GB,也可以使用Vaex即时打开(只需0.052秒!)。
为什么这么快?当使用Vaex打开内存映射文件时,实际上没有进行任何数据读取。Vaex仅读取文件的元数据,例如磁盘上数据的位置,数据结构(行数、列数、列名和类型),文件说明等。那么,如果我们要检查数据或与数据交互怎么办?打开数据集会生成一个标准的DataFrame并对其进行快速检查:
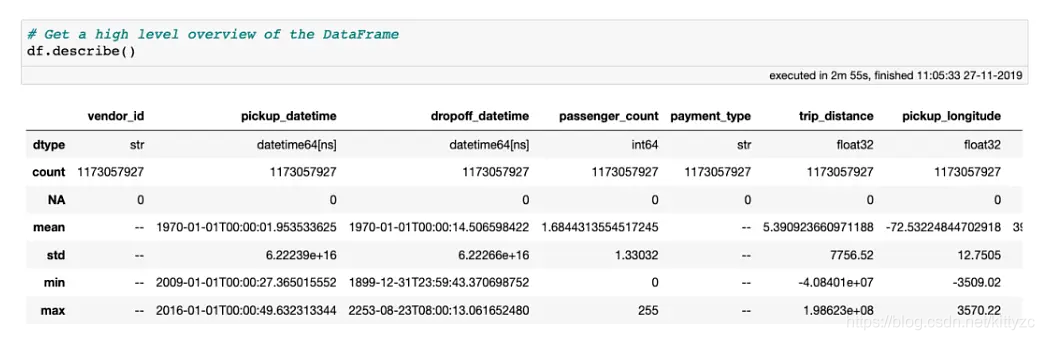
让我们从极端异常值或错误数据输入值开始清除此数据集。一个很好的方法是使用describe方法对数据进行高级概述,其中显示了样本数、缺失值数和每一列的数据类型。如果列的数据类型为数字,则还将显示平均值、标准偏差以及最小值和最大值。所有这些统计信息都是通过对数据的一次传递来计算的。
2.3 数据分析
可以使用pandas类似的查询和聚合功能:
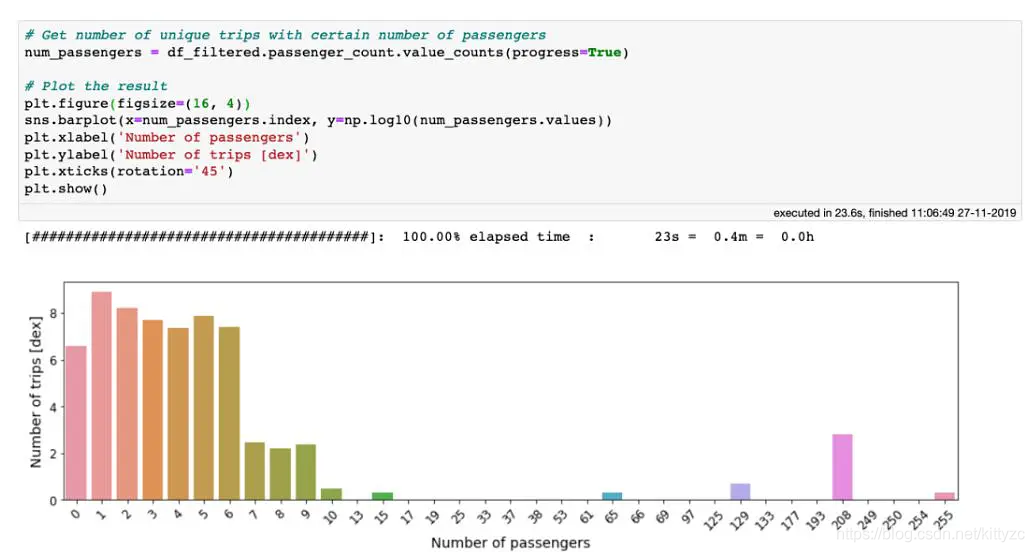
在 10 亿行数据上使用 value_counts 方法只需要 20 秒
3. dask
Dask是一个并行计算库,能在集群中进行分布式计算,能以一种更方便简洁的方式处理大数据量,与Spark这些大数据处理框架相比较,Dask更轻。Dask更侧重与其他框架,如:Numpy,Pandas,Scikit-learning相结合,从而使其能更加方便进行分布式并行计算。

Dask存在三种最基本的数据结构,分别是:Arrays、Dataframes以及Bags,接下来详细介绍这三种数据结构以及其应用场景。
3.1 dask array
dask array就是分块的numpy array,保证每一块不会out-of-memory:
# Arrays implement the Numpy API
import dask.array as da
x = da.random.random(size=(10000, 10000),
chunks=(1000, 1000))
x + x.T - x.mean(axis=0)
3.2 Dataframes
Dataframe是基于Pandas Dataframe改进的一个可以并行处理大数据量的数据结构,即使对大于内存的数据也是能够处理的。在这里有一个重要的概念——Delayed(延迟计算),这个之后会讲解,这里就暂时将其看作是一个指针,其并没有真的将所有分块后的数据读入内存,只是在内存中存放了一个指针指向了这些块数据。
通过以上的步骤,我们知道了当我读取一个csv文件时,其实Dask会将其转换成一个Delayed List,列表中的每一个Delayed对象计算后的大小都不会超过blocksize。
# Dataframes implement the Pandas API
import dask.dataframe as dd
df = dd.read_csv('s3://.../2018-*-*.csv', parse_dates='timestamp', # normal Pandas code
blocksize=64000000) # break text into 64MB chunks
df.groupby(df.account_id).balance.sum()
3.3 bags/lists
bags是json/list的一个封装,下面是例子:
import dask.bag as db
b = db.read_text('*.json').map(json.loads)
total = (b.filter(lambda d: d['name'] == 'Alice')
.map(lambda d: d['balance'])
.sum())
3.4 delayed
Dask.delayed是一种并行化现有代码的简单而强大的方法。之所以被叫做delayed是因为,它没有立即计算出结果,而是将要作为任务计算的结果记录在一个图形中,稍后将在并行硬件上运行。
有时问题用已有的dask.array或dask.dataframe可能都不适合,在这些情况下,我们可以使用更简单的dask.delayed界面并行化自定义算法。例如下面这个例子。
def inc(x):
return x + 1
def double(x):
return x * 2
def add(x, y):
return x + y
data = [1, 2, 3, 4, 5]
import dask
output = []
for x in data:
a = dask.delayed(inc)(x)
b = dask.delayed(double)(x)
c = dask.delayed(add)(a, b)
output.append(c)
total = dask.delayed(sum)(output)
3.5 sklearn
dask实现了不少sklearn的方法:
# Dask-ML implements the Scikit-Learn API
from dask_ml.linear_model \
import LogisticRegression
lr = LogisticRegression()
lr.fit(train, test)
4. 多线程和多进程
多进程和多线程都可以执行多个任务,线程是进程的一部分。多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了。
4.1 多进程
multiprocessing模块提供了一个Process类来代表一个进程对象。
创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动。join()方法可以等待子进程结束后再继续往下运行,通常用于进程间的同步。 multiprocessing模块提供了一个Pool进程池的方式批量创建子进程。pool的默认容量为CPU的计算核的数量。
下面是个简单例子:
from multiprocessing import Pool
import os, time
def long_time_task(name):
time.sleep(2)
print('Sub task %s (%s) done\n' % (name, os.getpid()))
print('Parent process %s.' % os.getpid())
p = Pool(5)
for i in range(10):
p.apply_async(long_time_task, args=(i,))
p.close()
#p.join()
print('Main subprocesses done.')
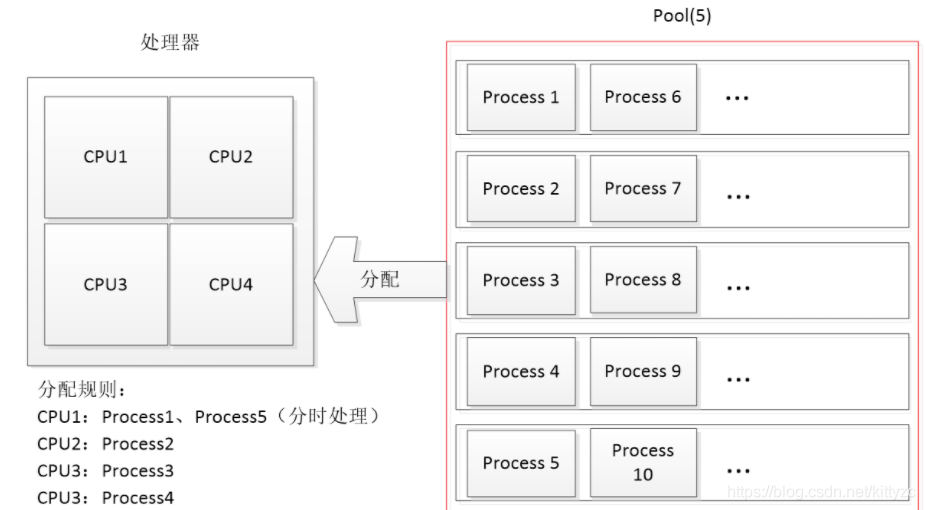
请注意输出的结果,process 0,1,2,3,4是立刻执行的,而process 5要等待前面某个process完成后才执行,这是因为Pool的大小为5,在电脑上默认为CPU的核数。因此,最多同时执行5个进程。
Process之间肯定是需要通信的,操作系统提供了很多机制来实现进程间的通信。Python的multiprocessing模块包装了底层的机制,提供了Queue、Pipes等多种方式来交换数据。
from multiprocessing import Process, Queue
import os, time, random
# 写数据进程执行的代码:
def write(q):
print('Process to write: %s' % os.getpid())
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
# 读数据进程执行的代码:
def read(q):
print('Process to read: %s' % os.getpid())
while True:
value = q.get(True)
print('Get %s from queue.' % value)
if __name__=='__main__':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 启动子进程pr,读取:
pr.start()
# 等待pw结束:
pw.join()
# pr进程里是死循环,无法等待其结束,只能强行终止:
pr.terminate()
4.2 多线程
线程的生命周期包括如下几个步骤:
- 新建:使用线程的第一步就是创建线程,创建后的线程只是进入可执行的状态,也就是Runnable,
t = threading.Thread(target=XX,args = []) - Runnable:进入此状态的线程还并未开始运行,一旦CPU分配时间片给这个线程后,该线程才正式的开始运行
- Running:线程正式开始运行,
t.start()。在运行过程中线程可能会进入阻塞的状态,即Blocked,t.join() - Blocked:在该状态下,线程暂停运行,解除阻塞后,线程会进入Runnable状态,等待CPU再次分配时间片给它
- 结束:线程方法执行完毕或者因为异常终止返回
任何进程默认就会启动一个线程,我们把该线程称为主线程,主线程又可以启动新的线程,Python的threading模块有个current_thread()函数,它永远返回当前线程的实例。主线程实例的名字叫MainThread,子线程的名字在创建时指定,我们用LoopThread命名子线程。名字仅仅在打印时用来显示,完全没有其他意义,如果不起名字Python就自动给线程命名为Thread-1,Thread-2……。
要想停止任务,可以显式地增加一个flag:
import threading
import time
flag = False
#定义线程需要做的内容,写在函数里面
def target():
for i in range(10):
print(i)
time.sleep(1)
if flag:
return
print('当前的线程 %s 在运行' % threading.current_thread().name)
t = threading.Thread(target=target,args = [])
t.start() #线程启动
time.sleep(3)
flag = True
print('当前的线程 %s 结束' % threading.current_thread().name)
4.3 任务同步:join
join所完成的工作就是线程/进程同步,即主任务结束之前,进入阻塞状态,一直等待其他的子任务执行结束之后,主任务再继续下去。
简单来说,就是阻塞主任务。
import threading
import time
#定义线程需要做的内容,写在函数里面
def target():
print('当前的线程%s 在运行' % threading.current_thread().name)
time.sleep(1)
print('当前的线程 %s 结束' % threading.current_thread().name)
print('当前的线程 %s 在运行' % threading.current_thread().name)
t = threading.Thread(target=target,args = [])
t.start() #线程启动
print('当前的线程 %s 结束' % threading.current_thread().name)
不添加join,上面的代码结果为:
当前的线程 MainThread 在运行
当前的线程Thread-13 在运行
当前的线程 MainThread 结束
当前的线程 Thread-13 结束
添加join,上面代码的结果为:
当前的线程 MainThread 在运行
当前的线程Thread-11 在运行
当前的线程 Thread-11 结束
当前的线程 MainThread 结束
join有一个timeout参数,当设置守护线程setDaemon(True),含义是主线程对于子线程等待timeout的时间将会杀死该子线程,最后退出程序。所以说,如果有10个子线程,全部的等待时间就是每个timeout的累加和。简单的来说,就是给每个子线程一个timeout的时间,让他去执行,时间一到,不管任务有没有完成,直接杀死。
没有设置守护线程时,主线程结束,但是并没有杀死子线程,子线程依然可以继续执行,直到子线程全部结束,程序退出

















 3478
3478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









