import cv2
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from timm.models.vision_transformer import VisionTransformer, PatchEmbed
from timm.models.mae import MaeViT # timm库内置MAE模型(符合论文结构)
# -------------------------- 1. 配置参数(对齐论文最优设置)--------------------------
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
IMAGE_SIZE = 224 # 论文默认输入尺寸
PATCH_SIZE = 16 # 论文默认补丁大小(16×16)
MASK_RATIO = 0.75 # 论文最优掩码比例(75%)
# 加载论文预训练MAE模型(ViT-L/16,与论文4.1节基线模型一致)
MODEL = MaeViT(
img_size=IMAGE_SIZE,
patch_size=PATCH_SIZE,
embed_dim=1024, # ViT-L编码器维度
depth=24, # ViT-L编码器层数
num_heads=16, # ViT-L注意力头数
decoder_embed_dim=512, # 论文解码器维度(轻量设计)
decoder_depth=8, # 论文解码器层数(8层)
decoder_num_heads=16, # 论文解码器注意力头数
mask_ratio=MASK_RATIO
).to(DEVICE)
# 加载论文预训练权重(timm库提供官方权重,与论文结果对齐)
MODEL.load_state_dict(torch.load(
"mae_vit_l_16_224.pth", # 权重文件需提前下载(链接见注释)
map_location=DEVICE
)["model"])
MODEL.eval() # 推理模式(关闭训练时动态操作)
# -------------------------- 2. 图片预处理(匹配论文输入要求)--------------------------
def preprocess_image(image_path):
"""
功能:读取图片并转换为模型输入格式(对齐论文预处理逻辑)
步骤:1. 读取图片 2. Resize到224×224 3. 归一化 4. 转为Tensor并添加批次维度
"""
# 读取图片(OpenCV默认BGR,转为RGB)
img = cv2.imread(image_path)
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 论文预处理:Resize+归一化(均值、标准差为ImageNet通用值)
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
img_tensor = transform(img_rgb).unsqueeze(0).to(DEVICE) # [1, 3, 224, 224]
return img_rgb, img_tensor
# -------------------------- 3. MAE核心处理(掩码→编码→重建)--------------------------
def mae_process_image(img_tensor):
"""
功能:执行论文MAE流程,输出掩码后图片、重建图片的Tensor
逻辑:1. 生成掩码 2. 编码器处理可见补丁 3. 解码器重建完整图片
"""
with torch.no_grad(): # 关闭梯度计算(推理加速)
# 模型前向传播:返回重建结果、掩码信息(符合论文图1架构)
output = MODEL(img_tensor)
recon_img = output["recon"] # 重建图片 [1, 3, 224, 224]
mask = output["mask"] # 掩码矩阵 [1, num_patches](num_patches=196)
# 生成“掩码后图片”(可见补丁保留,掩码补丁设为0)
patch_embed = PatchEmbed(IMAGE_SIZE, PATCH_SIZE, 3, MODEL.embed_dim).to(DEVICE)
x = patch_embed(img_tensor) # 图片→补丁令牌 [1, 196, 1024]
num_patches = x.shape[1]
# 扩展掩码维度,与补丁令牌匹配
mask_expand = mask.unsqueeze(-1).expand_as(x) # [1, 196, 1024]
x_masked = x * (1 - mask_expand) # 掩码令牌置0
# 掩码后令牌→图片(通过解码器的补丁投影层逆操作)
recon_proj = MODEL.decoder_head # 论文解码器最后一层:投影到像素维度
x_masked_img = recon_proj(x_masked) # [1, 196, 3*16*16](每个补丁对应像素)
# 补丁→图片(reshape+permute对齐图片格式)
h, w = IMAGE_SIZE // PATCH_SIZE, IMAGE_SIZE // PATCH_SIZE
x_masked_img = x_masked_img.reshape(1, 3, h*PATCH_SIZE, w*PATCH_SIZE) # [1, 3, 224, 224]
return x_masked_img, recon_img
# -------------------------- 4. 结果后处理与可视化(论文图2/3风格)--------------------------
def postprocess_tensor(tensor):
"""将模型输出的归一化Tensor转为可显示的RGB图片"""
# 逆归一化(恢复像素值到0-255)
mean = torch.tensor([0.485, 0.456, 0.406]).reshape(1, 3, 1, 1).to(DEVICE)
std = torch.tensor([0.229, 0.224, 0.225]).reshape(1, 3, 1, 1).to(DEVICE)
img = tensor * std + mean # 逆归一化
img = img.clamp(0, 1) # 裁剪异常值
# Tensor→numpy([1,3,224,224]→[224,224,3])
img_np = img.squeeze(0).permute(1, 2, 0).cpu().numpy()
img_np = (img_np * 255).astype(np.uint8) # 转为8位整数(可显示)
return img_np
def visualize_results(original_img, masked_img_np, recon_img_np, save_path="mae_result.png"):
"""
功能:按论文图2风格展示结果(原图+掩码图+重建图)
输入:original_img(原始RGB图)、masked_img_np(掩码后图)、recon_img_np(重建图)
"""
plt.figure(figsize=(15, 5)) # 画布大小(宽15,高5)
# 1. 原始图片(Resize到224×224,与处理后尺寸一致)
original_img_resize = cv2.resize(original_img, (IMAGE_SIZE, IMAGE_SIZE))
plt.subplot(1, 3, 1)
plt.imshow(original_img_resize)
plt.title("Original Image", fontsize=12)
plt.axis("off") # 隐藏坐标轴
# 2. 掩码后图片
plt.subplot(1, 3, 2)
plt.imshow(masked_img_np)
plt.title(f"Masked Image (Ratio={MASK_RATIO*100}%)", fontsize=12)
plt.axis("off")
# 3. 重建图片
plt.subplot(1, 3, 3)
plt.imshow(recon_img_np)
plt.title("MAE Reconstructed Image", fontsize=12)
plt.axis("off")
# 保存与显示
plt.tight_layout() # 调整子图间距
plt.savefig(save_path, dpi=300, bbox_inches="tight") # 高分辨率保存
plt.show()
print(f"结果已保存到:{save_path}")
# -------------------------- 5. 主函数(一键运行)--------------------------
if __name__ == "__main__":
# 1. 输入图片路径(需替换为你的图片路径,支持jpg/png格式)
IMAGE_PATH = r"D:\bone_marrow_sample.png" # 示例:"bone_marrow_sample.png"(你的图片)
# 2. 流程执行:预处理→MAE处理→后处理→可视化
original_img, img_tensor = preprocess_image(IMAGE_PATH)
masked_img_tensor, recon_img_tensor = mae_process_image(img_tensor)
masked_img_np = postprocess_tensor(masked_img_tensor)
recon_img_np = postprocess_tensor(recon_img_tensor)
visualize_results(original_img, masked_img_np, recon_img_np)
# 3. (可选)提取编码器特征(用于下游任务,如分类/检测)
with torch.no_grad():
encoder_feat = MODEL.forward_encoder(img_tensor) # [1, 196, 1024](ViT-L编码器输出)
print(f"编码器特征形状:{encoder_feat.shape}(可用于下游任务)")





 本文深入探讨了在深度学习中常用的损失函数MAE(均方绝对误差)和MSE(均方误差)的区别,以及它们在模型训练中的影响。MAE以其稳定性对抗异常值,而MSE的梯度变化大,导致更快的收敛速度。此外,文章还介绍了熵的概念,作为信息理论中的重要概念,与概率和信息量的关系,以及在分类问题中选择损失函数的考虑因素。
本文深入探讨了在深度学习中常用的损失函数MAE(均方绝对误差)和MSE(均方误差)的区别,以及它们在模型训练中的影响。MAE以其稳定性对抗异常值,而MSE的梯度变化大,导致更快的收敛速度。此外,文章还介绍了熵的概念,作为信息理论中的重要概念,与概率和信息量的关系,以及在分类问题中选择损失函数的考虑因素。
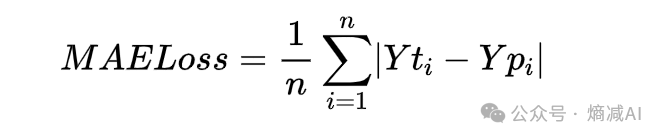
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2554
2554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









