




 Gemini作为最新的模型,其在多模态处理方面展现出领先优势,尤其是在video识别上超越了GPT4v。该模型采用了非casual-decoder的Encoder-decoder架构,引入video能力,规模约为GPT-4的2.5倍。此外,文章探讨了Gemini所使用的硬件,特别是Google的TPU和OCS全光网络系统在深度学习通信延迟和带宽管理上的创新。
Gemini作为最新的模型,其在多模态处理方面展现出领先优势,尤其是在video识别上超越了GPT4v。该模型采用了非casual-decoder的Encoder-decoder架构,引入video能力,规模约为GPT-4的2.5倍。此外,文章探讨了Gemini所使用的硬件,特别是Google的TPU和OCS全光网络系统在深度学习通信延迟和带宽管理上的创新。
跟我读,[dʒemɪnaɪ], 不是铃木汽车那个jimny
一早上被刷屏了,铺天盖地的Gemini逆袭,从现在公布出来的demo和测试结果确实看着是很领先的模型,对video的识别GPT4v目前是做不到的,因为它的多模态encoder和decoder现在不支持video的
与此同时也伴随着争议让一些问题发酵,比如为什么在MMLU里面few_shot COT@32的时候 Gemini Ultra beat GPT4,而few_shot COT@5的时候 不如GPT4
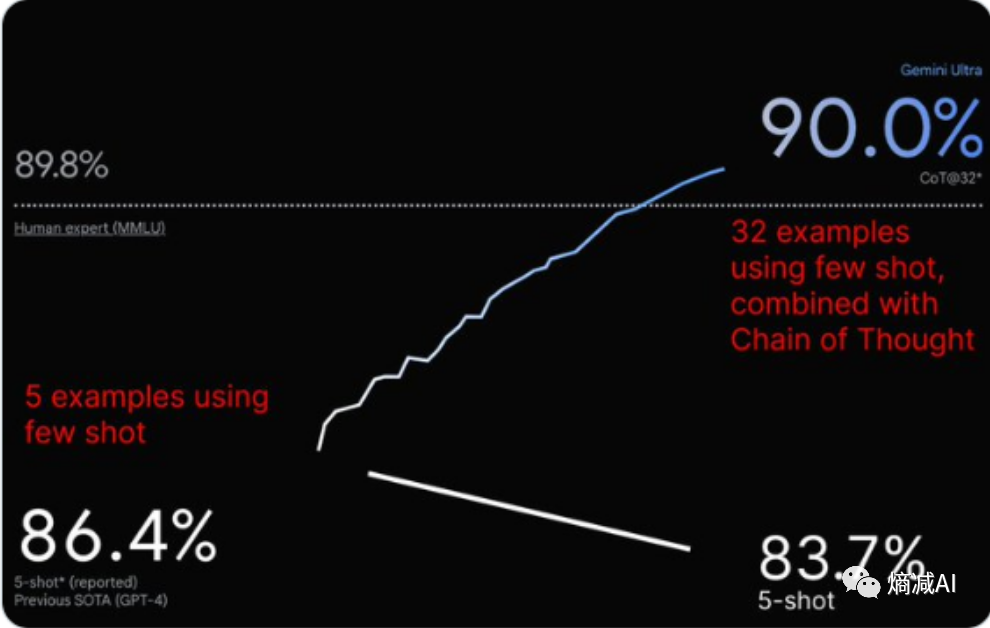
对于我个人来说,我其实最关注的是Gemini的技术实现是否有所突破,相对于现在的casual-decoder的Transformer来讲
由于东西比较新,也没有Paper出来(由于GPT-4就没公布,估计后面大家想看到一些商业化的产品的核心内容也很难了),我就自己总结了几个比较值得说的点:
1- 真正的多模态:把video能力加入到编解码里面,目前没看到解码,如果不能生成视频的话,那严格来说还是差了一块拼图,但是不管怎么说,这个是个不小的提升,相当于把人类世界的几种表达方式凑全了,目前Claude2只能text,GPT-4V和GPT-4严格来说是两个模型,还不支持video
2- Encoder-decoder模式:不知道是急于给T5和众兄弟证明,还是确实顶级大佬们发现了Encoder-decoder模式的某种没表现出来的能力,从一些小道消息,我听说Gemini并没有采用业界现在最火,性能最优的casual-decoder的架构,而是采用了最让人诟病的和T5一样的非满秩encoder-decoder全来的传统Transform
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 366
366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









