







线性回归

时间: 2025 − 03 − 15 2025-03-15 2025−03−15 暴雨 深圳
一、前置条件
| 类别 | 子类别 | 描述 |
|---|---|---|
| 数学基础 | 线性代数 | 掌握向量和矩阵运算(如点积与转置) |
| 微积分 | 理解导数、梯度及极值求解的基本概念 | |
| 统计学 | 熟悉均值、方差、协方差和正态分布的基础知识 | |
| 编程基础 | Python | 具备基础语法知识,并能灵活运用列表和字典等数据结构 |
| NumPy | 能够进行数组操作并利用各种数学函数 | |
| Matplotlib | 掌握基础的数据可视化技能,使你能够将抽象的数据转化为直观的图像 | |
| 线性回归相关概念 | 因变量(Dependent Variable) | 指依赖于其他变量变化的变量 y y y |
| 自变量(Independent Variable) | 影响因变量变化的变量 x x x | |
| 拟合(Fitting) | 通过模型训练使预测结果尽可能贴近实际数据的过程,就像裁缝为顾客量身定制一套完美贴合的衣服 | |
| 过拟合(Overfitting) | 模型在训练数据上表现过于精确,导致对新数据泛化能力差,如同过度装饰的蛋糕,外观华丽却失去实用价值 | |
| 欠拟合(Underfitting) | 模型未能充分学习数据特征,导致对训练数据和新数据的表现都不佳,类似于没有完全展开的地图,无法提供完整的信息 |
二、核心知识点
线性回归基础
1. 线性回归的定义
线性回归是通过一条直线(一元)或超平面(多元)拟合数据,预测因变量与自变量之间的线性关系。

公式:
y
=
β
0
+
β
1
x
+
ϵ
y = \beta_0 + \beta_1 x + \epsilon
y=β0+β1x+ϵ
其中,
y
y
y 是因变量,
x
x
x 是自变量,
β
0
\beta_0
β0 是截距,
β
1
\beta_1
β1 是斜率,
ϵ
\epsilon
ϵ 是误差项。
通俗解释:
假设你想根据房屋面积(自变量)预测房价(因变量),线性回归就是找到一条最能代表数据趋势的直线,这条直线的方程就是你的预测模型。
例子:
假设你想根据房屋的面积(自变量)预测房价(因变量)。收集到的数据点可能像这样散落在图上:
- 面积小的房子价格低,面积大的房子价格高。
- 但数据点可能不完全在一条直线上,因为价格还受地段、装修等因素影响。
线性回归的目标是找到一条最贴近这些点的直线,即使得这条线尽可能“平滑地穿过所有点中间”,从而预测未来房屋的价格。例如:- 如果一条直线的方程是 价格 = 100万 + 2万元/平方米 × 面积,那么当面积是100平方米时,预测价格就是 100万 + 2×100 = 300万元。

2. 为什么线性回归可以实现预测
线性回归的假设
| 序号 | 核心假设 | 描述 | 含义和解读 |
|---|---|---|---|
| 1 | 线性关系 | 因变量与自变量之间存在线性关系。 | 指的是模型假设因变量的变化与一个或多个自变量的变化成比例。这意味着随着自变量的增加或减少,因变量也会相应地按固定比率增减。 |
| 2 | 独立性 | 观测值之间相互独立。 | 每个观测值应不受其他观测值影响。这保证了误差项(残差)彼此不相关,有助于确保回归系数估计的准确性。 |
| 3 | 同方差性 | 误差项的方差在不同自变量值下相同。 | 即无论自变量取何值,误差项的分布保持不变。违反这一假设可能导致某些预测值的可靠性降低。 |
| 4 | 正态性 | 误差项服从正态分布。 | 特别是在小样本中,如果误差项不符合正态分布,可能会影响参数估计的准确性和置信区间的计算。 |
| 5 | 无多重共线性 | 自变量之间无完全线性相关。 | 确保模型中的自变量不是由其他自变量线性组合而成。多重共线性会使得估计的回归系数不稳定,难以解释。 |
在探讨线性回归模型的有效性时,我们首先需要理解其核心假设和逻辑基础。
线性回归基于这样一个假设:
自变量与因变量之间存在
线性关系。这意味着它们之间的关联可以通过一条直线(或在多维情况下为超平面)来近似表示。尽管现实世界中的数据往往受到多种复杂因素的影响,但线性回归通过简化这些关系,提取出一个“平均趋势”,从而有效地简化了分析过程。
考虑到真实数据点可能不会完美地落在直线上,线性回归引入了误差项的概念,用以表示如测量误差或未考虑在内的其他影响因素。数学上,这可以表示为
y
=
β
0
+
β
1
x
+
ϵ
y = \beta_0 + \beta_1 x + \epsilon
y=β0+β1x+ϵ,其中
y
y
y代表因变量(例如房价),
x
x
x代表自变量(例如面积),而
ϵ
\epsilon
ϵ表示由于地段、装修等因素造成的噪声。这一误差项的存在使得模型能够更准确地反映实际情况。
为了找到最佳拟合直线,线性回归采用最小二乘法,旨在最小化每个数据点到直线垂直距离的平方和。这一过程可以直观地想象为所有数据点通过橡皮筋连接到一条直线上,当橡皮筋处于最松弛状态时,即总的拉力(误差)最小,这时的直线就是最优解。这种方法不仅简单易行,而且在大多数情况下都能提供满意的拟合效果。
最后,线性回归因其计算简便且易于解释的特点,成为快速验证理论假设的理想选择。
- 斜率( β 1 \beta_1 β1)揭示了自变量每增加一个单位时,因变量平均预期的变化量;
- 截距( β 0 \beta_0 β0),虽然有时在实际情况中没有直接意义,但它在数学上是必要的,用于描述当所有自变量均为零时,因变量的预期值。
综上所述,线性回归不仅提供了对变量间关系的初步洞察,还为后续更复杂的统计分析奠定了基础。
3. 线性回归的局限性
虽然线性回归简单有效,但并非万能:
- 仅适用于线性关系:若数据趋势是曲线(如二次函数),线性回归效果差。
- 忽略复杂关系:无法直接处理自变量间的交互作用或非线性影响。
- 对异常值敏感:极端值可能大幅影响直线的位置。

4. 总结
| 通俗理解 | 核心用途 | 为什么可行 |
|---|---|---|
| 通过一条直线/超平面,找到数据的整体趋势 | 预测连续值、分析变量关系、趋势分析 | 假设线性关系存在,通过最小化误差找到最优直线,简单直观且可解释性强 |
重点知识
损失函数
损失函数(Loss Function)衡量预测值与真实值的差异
均方误差(Mean Squared Error, MSE)是一种常用的损失函数,用于回归问题中衡量预测值与真实值之间的差异
均方误差(MSE):
MSE
=
1
n
∑
i
=
1
n
(
y
i
−
y
^
i
)
2
\text{MSE} = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2
MSE=n1i=1∑n(yi−y^i)2
其中,
y
^
i
=
β
0
+
β
1
x
i
\hat{y}_i = \beta_0 + \beta_1 x_i
y^i=β0+β1xi 是预测值。
def mean_squared_error_self(y_true,y_pred):
if len(y_true) != len(y_pred):
raise "error"
return sum( (y_t - y_p) ** 2 for (y_t, y_p ) in zip(y_true,y_pred) )/len(y_true)
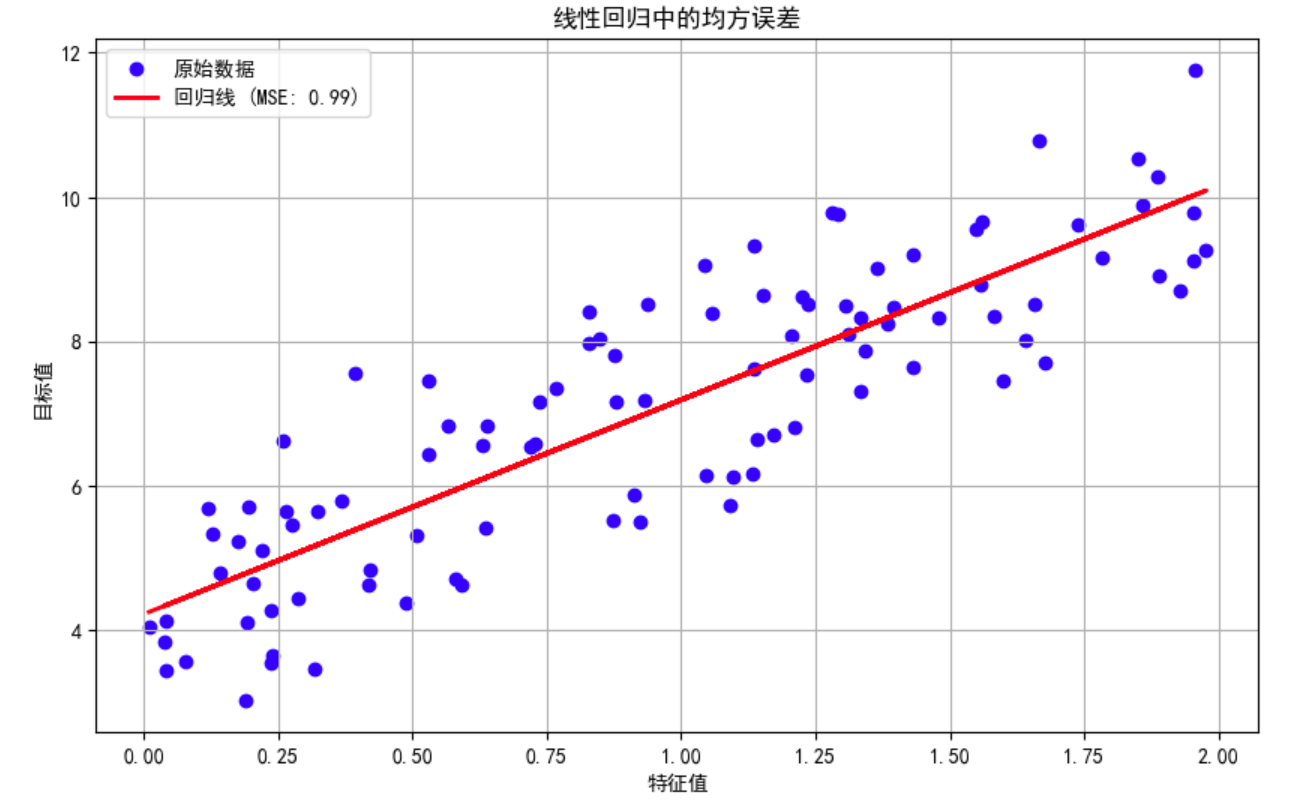
最小二乘法
通过求导使损失函数最小化,得到参数 β 0 \beta_0 β0 和 β 1 \beta_1 β1的最优解:
最小二乘法(Least Squares Method)是一种常用的数据拟合方法,主要用于找到一条直线或其他曲线,使得实际数据点与该曲线之间的垂直距离的平方和最小。在线性回归中,最小二乘法用于找到最佳拟合直线。
β
1
=
∑
(
x
i
−
x
ˉ
)
(
y
i
−
y
ˉ
)
∑
(
x
i
−
x
ˉ
)
2
β
0
=
y
ˉ
−
β
1
x
ˉ
\beta_1 = \frac{\sum (x_i - \bar{x})(y_i - \bar{y})}{\sum (x_i - \bar{x})^2} \\ \beta_0 = \bar{y} - \beta_1 \bar{x}
β1=∑(xi−xˉ)2∑(xi−xˉ)(yi−yˉ)β0=yˉ−β1xˉ
其中,
x
ˉ
\bar{x}
xˉ和
y
ˉ
\bar{y}
yˉ是均值。
梯度下降法
通过迭代更新参数 β \beta β来最小化损失函数:
β
j
=
β
j
−
α
∂
MSE
∂
β
j
\beta_j = \beta_j - \alpha \frac{\partial \text{MSE}}{\partial \beta_j}
βj=βj−α∂βj∂MSE
其中,
α
\alpha
α是学习率(Learning Rate)。
- 通俗解释:
假设你站在一座山的山顶,想要找到山脚(最低点),梯度下降就像每次向坡度最陡的方向迈出一小步,直到无法再下降为止。
指引:
简单案例—预测
1. 数据生成
- 代码示例:
import numpy as np import matplotlib.pyplot as plt # 生成随机数据 np.random.seed(42) X = 2 * np.random.rand(100, 1) y = 4 + 3 * X + np.random.randn(100, 1) # 真实模型:y = 4 + 3x + 噪声

2. 最小二乘法求解
-
代码实现:
# 添加截距项 X_b = np.c_[np.ones((100, 1)), X] # 计算最佳拟合直线的参数 beta_best = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y) print("β0:", beta_best[0][0], "β1:", beta_best[1][0])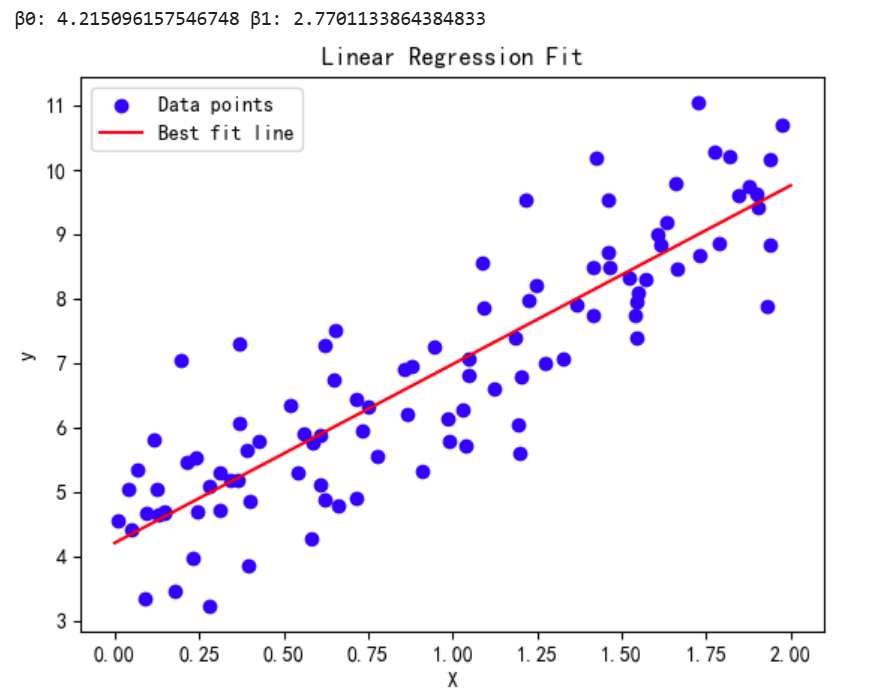
3. 梯度下降法求解
均方误差(Mean Squared Error, MSE)是衡量预测值与真实值之间差异的一种常见损失函数,广泛应用于回归问题中。MSE的定义为所有数据点上预测值与实际值之差的平方的平均值:
M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2
其中,
- n n n 是样本数量,
- y i y_i yi 是第 i i i 个样本的真实值,
- y ^ i \hat{y}_i y^i 是第 i i i 个样本的预测值。
当我们进行模型训练时,通常需要计算MSE关于模型参数(例如线性回归中的斜率和截距)的梯度,以便使用梯度下降等优化算法来最小化损失。
假设我们有一个简单的线性回归模型 y ^ = β 0 + β 1 x \hat{y} = \beta_0 + \beta_1 x y^=β0+β1x,其中 β 0 \beta_0 β0 是截距, β 1 \beta_1 β1 是斜率。MSE相对于这些参数的偏导数如下:
关于斜率 β 1 \beta_1 β1 的偏导数
∂ M S E ∂ β 1 = 2 n ∑ i = 1 n − x i ( y i − ( β 0 + β 1 x i ) ) \frac{\partial MSE}{\partial \beta_1} = \frac{2}{n} \sum_{i=1}^{n} -x_i(y_i - (\beta_0 + \beta_1 x_i)) ∂β1∂MSE=n2i=1∑n−xi(yi−(β0+β1xi))
关于截距 β 0 \beta_0 β0 的偏导数
∂ M S E ∂ β 0 = 2 n ∑ i = 1 n − ( y i − ( β 0 + β 1 x i ) ) \frac{\partial MSE}{\partial \beta_0} = \frac{2}{n} \sum_{i=1}^{n} -(y_i - (\beta_0 + \beta_1 x_i)) ∂β0∂MSE=n2i=1∑n−(yi−(β0+β1xi))
这两个偏导数用于更新模型参数以减少MSE,通过以下公式进行参数更新:
β j : = β j − α ∂ M S E ∂ β j \beta_j := \beta_j - \alpha \frac{\partial MSE}{\partial \beta_j} βj:=βj−α∂βj∂MSE
其中 α \alpha α 是学习率,控制每一步更新的幅度,而 j j j 可以是 0 0 0 或 1 1 1,分别对应于截距和斜率。这种基于梯度的方法使得我们可以有效地找到使MSE最小化的参数值。
- 代码实现:
import numpy as np import matplotlib.pyplot as plt # 生成随机数据 np.random.seed(42) X = 2 * np.random.rand(100, 1) # 生成100个在0到2之间的随机数作为特征 y = 4 + 3 * X + np.random.randn(100, 1) # 真实模型:y = 4 + 3x + 噪声 # 添加截距项 X_b = np.c_[np.ones((100, 1)), X] # 在每个样本前面添加1,用于表示截距项 # 随机梯度下降参数设置 eta = 0.1 # 学习率 epochs = 500 # 迭代次数 m = 100 # 样本数量 # 随机初始化参数 theta = np.random.randn(2, 1) # 初始化两个参数θ0和θ1 # 存储theta的历史值 theta_history = [] # 随机梯度下降算法 for epoch in range(epochs): for i, v in enumerate(X_b): # 预测 y_p = np.dot(v.T, theta) # 计算预测值y_p # 更新参数 theta[1] = theta[1] - eta * X_b[i][1] * (y_p - y[i]) * 2 / m # 更新斜率θ1 theta[0] = theta[0] - eta * (y_p - y[i]) * 2 / m # 更新截距θ0 theta_history.append(theta.copy()) # 将当前的θ0和θ1保存到历史记录中 print("θ0:", theta[0], "θ1:", theta[1]) # 绘制散点图和最佳拟合直线 plt.figure(figsize=(12, 6)) plt.subplot(1, 2, 1) plt.scatter(X, y, color='blue', label='数据点') # 绘制数据点 plt.plot(X, X_b.dot(theta), color='red', label='最佳拟合线') # 绘制最佳拟合直线 plt.title('随机梯度下降法线性回归拟合') plt.xlabel('X') plt.ylabel('y') plt.legend() # 绘制θ0和θ1的变化历史 theta_history = np.array(theta_history) plt.subplot(1, 2, 2) plt.plot(range(len(theta_history)), theta_history[:, 0], label='θ0 变化历史', color='green') # 绘制θ0的变化历史 plt.plot(range(len(theta_history)), theta_history[:, 1], label='θ1 变化历史', color='purple') # 绘制θ1的变化历史 plt.title('θ0和θ1随迭代次数的变化') plt.xlabel('迭代次数') plt.ylabel('θ值') plt.legend() plt.tight_layout() plt.show()

评估与优化
1. 评估指标
| 指标 | 公式 | 作用 |
|---|---|---|
| R²分数 | R^2 = 1 − ∑ ( y i − y ^ i ) 2 ∑ ( y i − y ˉ ) 2 1 - \frac{\sum (y_i - \hat{y}_i)^2}{\sum (y_i - \bar{y})^2} 1−∑(yi−yˉ)2∑(yi−y^i)2 | 衡量模型解释力(越接近1越好) |
| 均方误差(MSE) | MSE = 1 n ∑ ( y i − y ^ i ) 2 \text{MSE} = \frac{1}{n} \sum (y_i - \hat{y}_i)^2 MSE=n1∑(yi−y^i)2 | 误差的绝对值衡量 |
R²分数
计算评估指标:
R
2
R²
R2分数:
ss_res = np.sum((y - y_predict) ** 2):残差平方和。
ss_tot = np.sum((y - np.mean(y)) ** 2):总平方和。
r_squared =
1
−
s
s
_
r
e
s
s
s
_
t
o
t
1- \frac{ss\_res}{ ss\_tot}
1−ss_totss_res:计算
R
2
R²
R2分数。
作用:
- 衡量模型解释力,即模型预测值与实际值之间的相关程度。
- 范围通常在0到1之间,越接近1表示模型越好。
参考值:
0.9·以上: 极好,模型拟合效果非常理想。0.7到0.9: 很好,模型有很强的解释能力。0.5到0.7: 较好,模型有一定的解释能力。- 0.3到0.5: 一般,模型解释能力较弱。
- 0.1到0.3: 差,模型几乎没有解释能力。
- 0以下: 不常见,表示模型预测值比平均值更差。
# 计算R²分数
ss_res = np.sum((y - y_predict) ** 2)
ss_tot = np.sum((y - np.mean(y)) ** 2)
r_squared = 1 - ss_res / ss_tot
print("R² 分数:", r_squared)
MSE:
# 计算均方误差(MSE)
mse = np.mean((y - y_predict) ** 2)
print("均方误差(MSE):", mse)

2. 过拟合与欠拟合
- 过拟合:模型过于复杂,过度适应训练数据噪声。
- 欠拟合:模型过于简单,无法捕捉数据趋势。
- 解决方法:
- 过拟合:增加数据量、正则化(如L1/L2)、简化模型。
- 欠拟合:增加特征、使用更复杂模型。
扩展内容
1. 多元线性回归
- 公式:
y = β 0 + β 1 x 1 + β 2 x 2 + ⋯ + β n x n + ϵ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \dots + \beta_n x_n + \epsilon y=β0+β1x1+β2x2+⋯+βnxn+ϵ - 代码示例:
# 假设X包含多个特征 X = np.array([[1, 2], [2, 3], [3, 4]]) y = np.array([5, 7, 9]) beta = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y)
2. 正则化方法
- L2正则化(Ridge Regression):
Loss = MSE + α ∑ β j 2 \text{Loss} = \text{MSE} + \alpha \sum \beta_j^2 Loss=MSE+α∑βj2 - L1正则化(Lasso Regression):
Loss = MSE + α ∑ ∣ β j ∣ \text{Loss} = \text{MSE} + \alpha \sum |\beta_j| Loss=MSE+α∑∣βj∣
三、后续练习题
-
手动实现梯度下降:
- 使用生成的数据,手动编写梯度下降代码,调整学习率(如0.01、0.1、1.0),观察收敛速度和结果。
-
特征工程:
- 将数据中的非线性关系(如二次项)加入模型,比较R²分数变化。
-
交叉验证:
- 使用K折交叉验证评估模型性能,选择最佳正则化参数。
四、下一阶段学习内容
核心内容
- 多元线性回归:处理多个自变量。
- 正则化方法:Lasso、Ridge、Elastic Net。
- 评估指标:调整R²、AIC/BIC。
进阶内容
- 多项式回归:处理非线性关系。
- 逻辑回归:分类问题的线性模型。
- 深度学习基础:线性回归作为神经网络的简单形式。
推荐资源
| 资源类型 | 推荐内容 |
|---|---|
| 书籍 | 《统计学习方法》李航,《Hands-On Machine Learning with Scikit-Learn》 |
| 在线课程 | Coursera《Machine Learning》吴恩达,《Linear Regression》Udemy课程 |
| 工具库 | Scikit-learn(Python)、statsmodels(Python)、R语言线性回归包 |
术语表
| 术语 | 解释 |
|---|---|
| 因变量(y) | 需要预测的变量,如房价。 |
| 自变量(x) | 影响因变量的变量,如房屋面积。 |
| 截距(β₀) | 当所有自变量为0时,因变量的预测值。 |
| 梯度下降 | 通过迭代优化参数,最小化损失函数的算法。 |
| 过拟合 | 模型过于复杂,过度拟合训练数据,泛化能力差。 |
| R²分数 | 衡量模型解释因变量变异性的指标,范围[0,1]。 |
重要问题解答
Q1:为什么梯度下降需要学习率?
- A:学习率控制每次迭代参数更新的步长。过大的学习率可能导致无法收敛,过小则收敛速度过慢。
Q2:线性回归的假设条件不满足怎么办?
- A:
- 非线性关系:尝试
多项式回归或非线性模型。 - 异方差性:使用加权最小二乘法或对数据进行变换。
多重共线性:删除冗余特征或使用正则化方法。
- 非线性关系:尝试
Q3:如何选择线性回归与分类模型(如逻辑回归)?
- A:
- 线性回归:因变量为连续值(如房价、温度)。
- 逻辑回归:因变量为离散类别(如是否患病、垃圾邮件分类)。
Q4:为什么最小二乘法和梯度下降都能求解线性回归?
- A:
最小二乘法通过解析解直接求得最优参数,而梯度下降通过迭代逼近最优解,适用于大规模数据或非凸问题。
Q5:如何避免过拟合?
- A:
- 增加数据量。
- 使用正则化(如Lasso/Ridge)。
- 简化模型复杂度(减少特征数量)。


















 2525
2525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











