



低电压低功耗高速双尾电流动态锁存比较器的分析与设计
摘要
超高速、面积高效且功耗优化的模数转换器的迫切需求,正推动人们探索和采用动态再生比较器,以最小化功耗和面积,并最大化速度。本文对多种基于动态锁存的比较器的延迟进行了详细分析,并推导出相应的解析表达式。借助这些解析表达式,设计者可以深入了解影响动态比较器延迟的各种参数。基于这些分析结果,可以探索各种权衡方案。结合文献研究和本文的分析,提出了一种新型基于动态锁存的比较器。在所提出的比较器中,基本的双尾动态锁存型比较器和共享电荷逻辑均经过修改,以在降低的电源电压下实现低功耗和高速性能。通过改进双尾锁存比较器结构并引入共享电荷逻辑,再生延迟得以减小,同时功耗也得到降低。在90纳米CMOS技术下的仿真结果验证了上述改进效果。仿真采用90纳米工艺,在1伏特电源电压和1吉赫兹频率下进行,结果显示延迟为50.9皮秒,功耗为31.80微瓦。
关键词 双尾电流比较器 动态锁存比较器 模数转换器(ADC) 共享电荷比较器 低功耗比较器
1 引言
如今,大多数设备正变得便携且由电池供电,这些设备将ADC用作重要的电路模块之一。ADC结构的基本组件是比较器。大多数高速ADC(例如闪速ADC)需要低电压、低功耗和高速的比较器,并在芯片上占用更小的面积。在超深亚微米CMOS技术中,器件的阈值电压并未像工艺那样按相同比例缩小,这使得在低电源电压[1—3]下设计比较器更加困难和具有挑战性。
为了补偿轨电压的降低,设计中使用了更大尺寸的晶体管,但这反过来增加了功耗和芯片面积。为了解决开关和输入范围(共模范围)的问题,自举技术和升压技术是两种基于增强参考、电源电压或时钟的技术。
在文献中,已报道了多种应对低电压设计挑战的技术,例如电流模式设计[4],、使用体驱动晶体管的设计 [5, 6], 、电源升压技术[7, 8]以及使用双栅氧工艺。
在体驱动技术[5],中,输入被施加到晶体管的衬底而非栅极端,从而使器件作为耗尽型器件工作,消除了阈值电压要求。体驱动晶体管的问题在于其跨导较低。与对应技术(即栅极驱动)相比,它在设计和制造工艺中增加了更多复杂度。在[9—11],中,其他技术特别是针对动态锁存比较器的技术是报道了使用共享电荷逻辑来减少延迟和功耗。不仅共享电荷逻辑,还报道了自适应功率控制技术[12]用于降低锁存比较器的功耗。为了应对低电压问题,不仅可以依靠技术进步,还可以开发新的电路架构,而不增加电路的复杂度,以应对深亚微米技术中的此类问题。
有关在低电源电压下提高比较器速度的架构级修改已在[13]中报道。首个双尾电流动态锁存比较器在 [14, 15]中提出。该比较器基于架构修改,其中输入级和锁存级被分离,以便在更低的电源电压下运行比较器。关于动态比较器延迟的广泛分析在[14—17]中给出。通过在传统的双尾电流比较器中添加几个最小尺寸的晶体管,在[14],中提出了新型动态比较器,该比较器无需堆叠多个晶体管即可在低电源电压下工作。在此架构中,比较器的速度显著提高,同时功耗降低。
本文针对不同比较器架构,对动态比较器的延迟进行了详细研究。此外,介绍了传统比较器的复位方案。基于复位阶段中共享电荷的概念,提出了一种新型动态比较器,该比较器无需堆叠过多晶体管或使用升压电压,可在低电源电压下工作。通过在传统双尾动态比较器中增加共享电荷晶体管和尾电流晶体管,显著降低了锁存延迟以及总延迟时间。与传统单尾电流和双尾电流动态锁存比较器相比,该改进还实现了显著的功耗节省,并改善了功耗延迟积(PDP)。
本文其余部分组织如下:第2节描述了传统单尾电流动态比较器和传统双尾电流动态比较器的解析表达式,讨论了每种结构及其优缺点。第3节讨论了共享电荷逻辑的概念以及所提出的双尾电流比较器架构。第4节给出了仿真结果,第5节为结论。
2 动态锁存时钟比较器
基于强正反馈的时钟控制动态锁存器比较器因其快速决策能力,成为许多高速模数转换器(ADC)中的有力候选方案。相关分析已在文中给出。
文献中研究了各种性能参数,如反冲噪声[18],、随机决策错误[19],、失调[20—22]以及噪声[23]。本节对两种常用拓扑结构的延迟进行了综合分析,即传统单尾动态锁存比较器(STDLC)和传统双尾动态锁存比较器。通过对这些拓扑结构的研究,基于其分析结果提出了一种新型比较器拓扑结构。
2.1 标准单尾电流动态锁存比较器(STDLC)
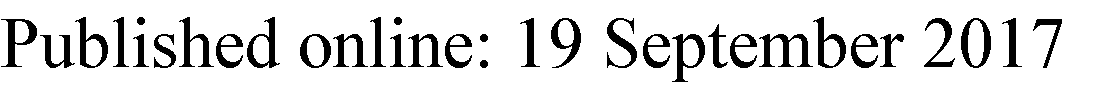
图1示出了具有高输入阻抗、轨到轨输出摆幅、无静态功耗且广泛应用于模数转换器中的传统单尾电流动态锁存比较器的拓扑结构图[1, 9, 14, 16, 24]。该比较器的操作分为两个阶段,称为复位阶段和再生阶段。
在复位阶段,时钟为低电平,晶体管Mtail处于关断状态。在此阶段,晶体管(M7和M8),即复位晶体管,导通并将两个输出端Outn和Outp拉至Vdd。此状态被定义为评估阶段的初始条件。复位晶体管用于在复位阶段为输出端提供有效的逻辑电平。
当时钟CLK切换到Vdd时,晶体管Mtail导通,而晶体管M7和M8关断,电路进入再生(比较)阶段。输出端Outp和Outn开始以不同的速率放电,此前它们已被预充电至电源电压
在之前的复位阶段期间,放电速率取决于相应的输入电压,即INN和INP。假设VINP高于VINN(VINP[V INN),在这种情况下,Outp端的放电速度比Outn端更快。此时,由晶体管M2的漏极电流放电的Outp端会先于Outn端下降至Vdd‐|Vthp|电平。对应的p型 MOS晶体管(在此情况下为晶体管M5)导通,并由交叉耦合反相器引发再生过程。这使得Outn充电至Vdd,而Outp将完全放电至地。如果假设情况相反,则结果将与上述场景相反。

图 2显示了电路的瞬态行为。比较器的延迟分为两个阶段,即t0和tlatch,其中t0是负载电容CL放电的时间段,直到第一个p型MOS晶体管导通为止。根据之前的假设(即VINP[VINN),晶体管M2导致输出端 Outp更快地放电。基于此,延迟由以下方程给出:
$$
t0 ¼ \frac{CL Vthp }{I2} \ffi \frac{2 CL Vthp }{Itail}
\tag{1}
$$
在公式(1)中,I2等于Itail/2和DIin的和,可表示为 Itail/2 ? gm1,2/DVin。对于较小的输入差分电压(DVin),漏极电流I2可近似为常数,且为尾电流的一半。第二项即tlatch是两个交叉耦合反相器的总锁存延迟。假设最终输出是从初始电压差DV0达到电源轨的一半(DV out=Vdd/2)。比较器后接锁存器,该锁存器将此电压增强至满幅电压[24]。用于计算锁存评估时间的方程由公式(2) [3, 14]给出。该延迟以对数方式依赖于再生阶段开始时(即t 2 ttail)的初始
再生阶段开始时的输出电压差(即在 t =t0 时刻)。
$$
tlatch ¼ \frac{CL}{gm_{eff}} \times \ln \left(\frac{DVout}{DV0}\right) \ffi \frac{CL}{gm_{eff}} \times \ln \left(\frac{Vdd/2}{DV0}\right)
\tag{2}
$$
在式(2)中,交叉耦合反相器的有效跨导用gm(eff)表示。利用式(1),初始电压差DV0可由下式(3)计算:
$$
DV0 ¼ |Voutp(t ¼ t0) Voutn(t ¼ t0)| = Vthp \frac{CL}{I1}
\Rightarrow DV0 ¼ 2 Vthp \frac{DIin}{Itail}
\tag{3}
$$
两条支路之间的输入电流差DIin远小于支路电流本身(即I1和I2),可近似为Itail/2。因此,式(3)可重写为:
$$
DV0 ¼ 2 Vthp \frac{\sqrt{b1,2 Itail}}{Itail} DVin ¼ 2 Vthp \sqrt{\frac{b1,2}{Itail}} DVin
\tag{4}
$$
输入晶体管的电流因子用b1,2表示。尾电流Itail是输入共模电压和电源电压的函数。将式(4)中的DV0代入式(2),并结合式(1)中的t0值,总延迟可写为如下形式,如式(5)所示。
$$
ttotal ¼ t0 + tlatch ¼ \frac{2 CL Vthp }{Itail} + \frac{CL}{gm_{eff}} \times \ln \left(\frac{Vdd}{4 Vthp DVin \sqrt{\frac{Itail}{b1,2}}}\right)
\tag{5}
$$
通过仔细分析公式(5)可以研究各种设计参数对总延迟的影响。一般观察结果如下:(1)延迟与差分输入电压(DVin)成反比,且与等效负载电容(CL)成正比;(2)延迟间接依赖于输入共模电压(Vcm)。如果降低输入共模电压(Vcm),会导致尾部(偏置)电流减小,从而增加第一级延迟,即t0 。从公式(4)可以看出,较小的偏置(尾)电流会延缓放电过程,并增大初始差分电压(DV0 ),最终减小t latch 。因此,在较小和较大的尾电流之间存在权衡。仿真结果表明,降低Vcm最终会导致总延迟增加。在[24],中已表明,电源电压的70%是
就产量和速度而言,共模输入电压的最佳值。(3) 输入晶体管的寄生电容不会直接影响输出节点的开关速度。设计中可以采用较大的输入晶体管,以最小化失调的影响,从而提高分辨率。
该结构的优点是零静态功耗、高输入阻抗、全摆幅输出以及对失配和噪声的鲁棒性[13, 14]。然而,该结构的缺点是:(1)有许多晶体管堆叠在一起,且最初只有两个晶体管(M3和M4)参与正反馈,直到其中一个晶体管(M5或M6)导通,因此正常工作和获得适当的延迟时间需要较高的电源电压。在低电源电压下,这种情况变得更糟,且由于跨导降低,延迟变得更大。(2)该结构中只有一个尾电流,该电流同时决定了锁存器和差分放大器的工作电流。为了在锁存级实现快速再生,希望具有较大的尾电流;另一方面,为了使差分级的晶体管工作在弱反型区,以获得更长的积分时间并得到更好的Gm与Id之比,又希望尾电流较小。
2.2 传统双尾电流动态锁存比较器(DTDLC)

图3显示了基于传统双尾电流的动态锁存比较器的原理图[14, 25]。如果将该结构与基于单尾电流的比较器进行比较,该比较器具有两个独立的尾电流,并且堆叠的晶体管数量更少。双尾电流有助于在差分级中优化较小的尾电流以实现更低的失调,同时在锁存级中使用较大的尾电流以实现快速锁存,两者可独立优化 [14]。该比较器的工作原理如下(参见图3)。复位阶段:当时钟 CLK = 0为低电平时,晶体管Mtail1和 Mtail2关断,晶体管M3和M4开始对两个中间节点即 fn和fp预充电至电源电压Vdd。最终,输出节点Outn 和Outp通过中间晶体管MR1和MR2放电至地。
评估阶段:当时钟切换到Vdd时,晶体管Mtail1和 Mtail2导通,晶体管M3和M4关断,节点fp和fn开始以尾电流(尾晶体管Mtail1的电流)和端子fn(fp)处的有效电容负载所定义的速率进行放电,从而在fn和fp之间建立差分电压(DVfn ( p ))。中间级晶体管将该电压传递给交叉耦合反相器,同时,这两个晶体管MR1和MR2通过降低回踢噪声[10]提供保护作用。
该比较器的总延迟也分为两部分,即t 0 和tdela y。
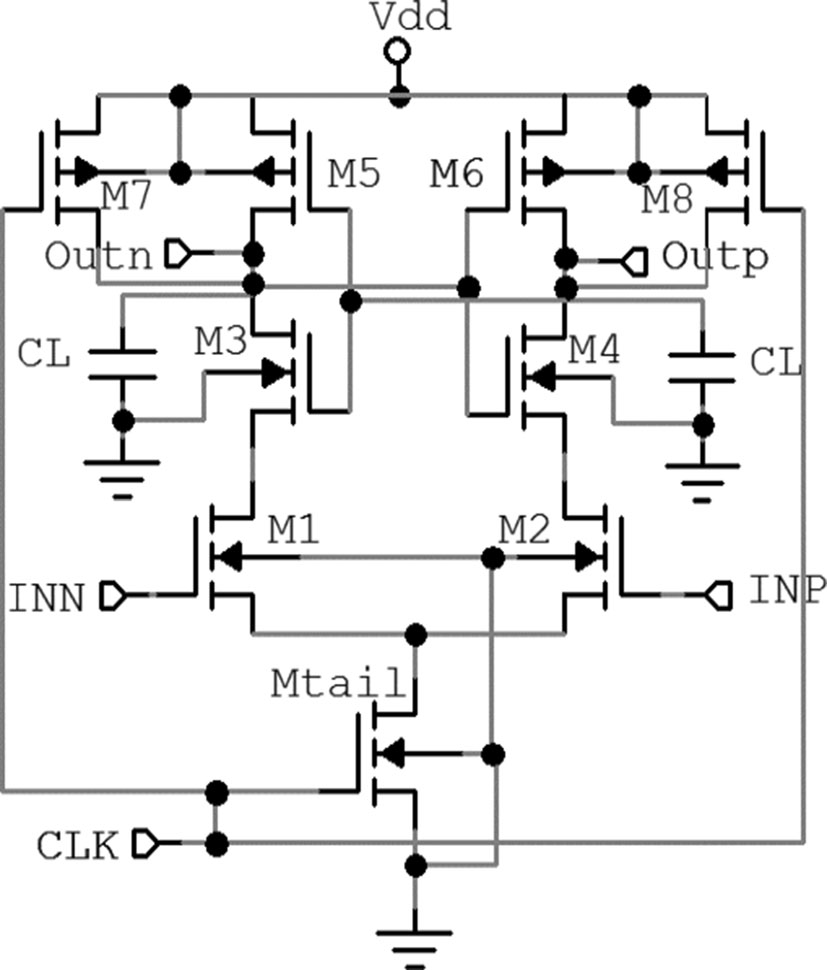
图4显示了电路的瞬态行为。比较器的延迟分为两个阶段,即t 0 和t latch 。延迟t 0 是负载电容通过电荷放电直到第一个nMOS(M9或M10)导通的时间,因此t 0 可由下式得到:
$$
t 0 ¼ \frac{V_{thn} CL}{I_{B1}} \approx \frac{2 V_{thn} CL}{I_{tail2}}
\tag{6}
$$
在公式(6)中,IB1是晶体管M9的漏极电流(假设VINP[VINN),其值约等于Itail2/2。一旦第一个 nMOS晶体管(在此假设下为晶体管M9)导通,对应的输出端(即Outn)便开始向地放电。这使得另一侧的晶体管(即晶体管M8)导通,并开始将该输出端充电至电源电压(Vdd)。再生时间可根据公式(2)求得。现在,锁存器可用的初始差分电压计算如下:
$$
DV0 ¼ |Voutp(t ¼ t0) Voutn(t ¼ t0)| = Vthn \left(1 \frac{IB2}{IB1}\right)
\tag{7}
$$
在此方程中,IB2和 IB1分别是锁存级的左右支路电流。现在,DIlatch= |IB1- IB2| = gmR1,2 DVfn/fp,因此, 式(7)可重写为:
$$
DV0 ¼ Vthn \frac{DIlatch}{IB1} \approx \frac{2 Vthn DIlatch}{Itail2} = \frac{2 Vthn gmR1,2}{Itail2} DVfn=fp
\tag{8}
$$
在公式(8)中,DVfn/fp是第一级的差分电压(在时间t0时fn和fp之间的电压),gmR1,2是传输级的跨导,由晶体管MR1和MR2构成。这两个参数是提升性能以增大DV0并从而缩短再生时间的主要关注点。通过中间状态放大的差分电压DVfn/fp导致锁存器失衡。在t0时刻fn和fp之间的差分电压可表示如下:
$$
DVfn=fp ¼ \frac{t0 gm1,2 DVin}{CL;fnð fpÞ}
\tag{9}
$$
I N1和 IN2是晶体管M1和M2的放电电流。差分电流取决于输入差分电压(即 DIN = gm1,2 DVin)。方程 (9)变为:
$$
DV0 ¼ \left(\frac{2 Vthn}{I_{tail2}}\right)^2 \frac{C_L}{C_{L;fn(fp)}} gmR1,2 gm1,2 DVin
\tag{10}
$$
总延迟可以通过将DV0 代入锁存器再生时间公式(2)中求得,
$$
t_{delay} ¼ \frac{2 Vthn CL}{I_{tail2}} + \frac{C_L}{gm_{eff}} \times \ln \left(\frac{V_{dd} I^2_{tail2} CL;fn(fp)}{8 V^2_{thn} CL gmR1;2 gm1;2 DVin}\right)
\tag{11}
$$
从该分析方程(公式11)可得出以下观察结果: (1)初始差分电压(在时间 t0)强烈依赖于差分输入电压、锁存器尾电流、输出节点与中间节点的电容比、输入级和中间级晶体管的跨导 gm以及在时间 tn时节点 fp和 f0之间的差分电压。如果我们增大DV0,,则延迟减小。(2)最终,一旦判决完成,两个中间晶体管 (即 MR1 和 MR2)均进入截止状态(由于节点 fn和 fp向地放电),不再对提高锁存器的有效跨导(gm)有贡献。在复位阶段,这些节点需要再次充电至 Vdd,意味着更高的功耗。下一节将介绍一种提出的结构,以克服上述缺点。
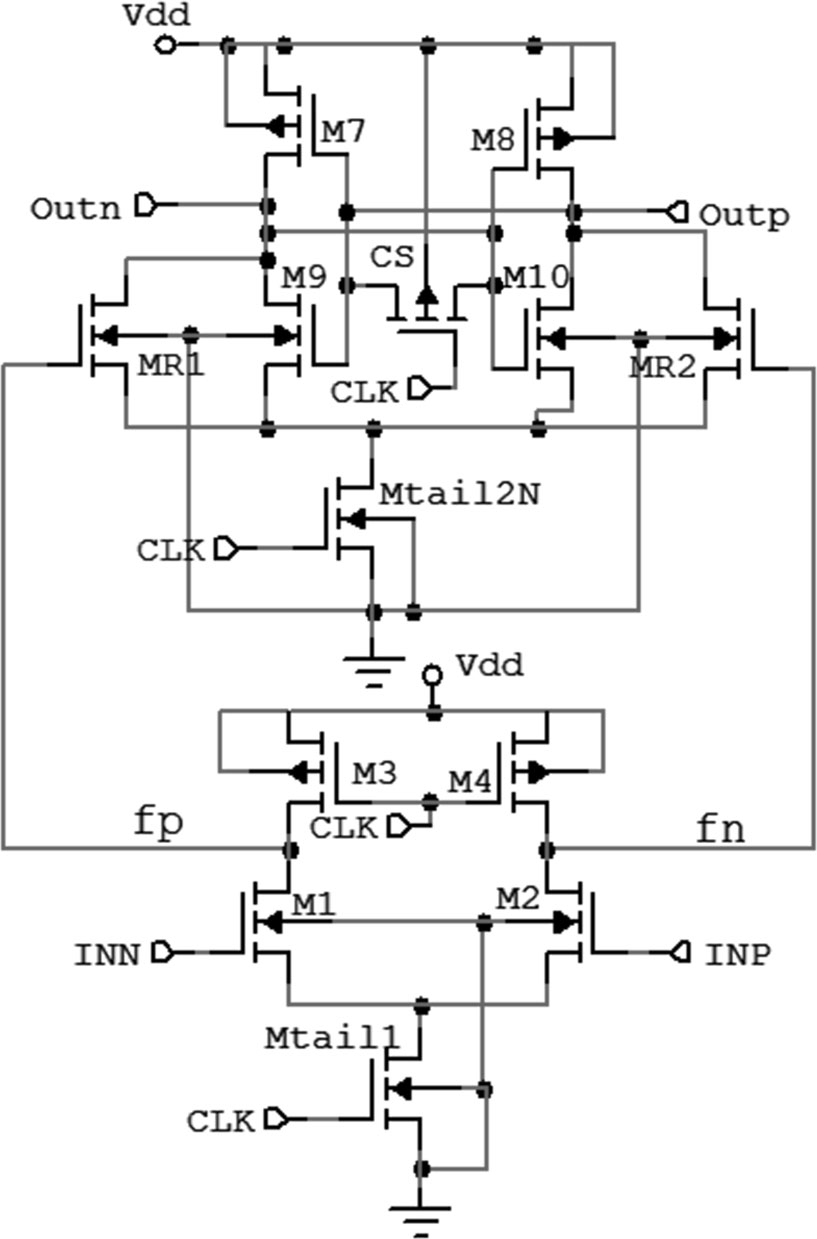
3 提出的共享电荷双尾比较器(PSCDTC)
由于双尾电流动态锁存比较器的性能优于基于单尾电流的动态锁存比较器,所提出的比较器基于双尾电流比较器。具有共享电荷逻辑的所提出比较器的原理图如图5所示。在所有动态锁存比较器中,复位阶段采用两种类型的复位技术,以在评估阶段提供有效的逻辑电平。在这种复位技术中,输出端被充电至电源电压 (Vdd)或放电至地(GND)[1, 14, 16]。在STDLC中,输出端被充电至Vdd,而在DTDLC中,输出端被放电至地。在比较器中,完成评估阶段后,其中一个输出端处于地电位,另一个处于Vdd。在前述的两种架构中,复位阶段期间输出端完全放电至地或充电至Vdd,下一个评估阶段因此必须从地电位或电源电压电平开始,需要更长时间间隔才能达到评估的最终数值,并且还会消耗更多功耗。此外,在下一次连续复位阶段,对一个输出端放电或对另一个输出端充电同样会消耗更多功耗。
所提出的比较器的基本思想是采用新的复位技术 [10, 11]来保留电荷,从而有助于减少延迟和功耗。这种新技术被称为共享电荷逻辑。在此技术中,两个输出端之间使用一个传输晶体管。在复位阶段,传输晶体管在两个输出端之间共享电荷。由于两个负载电容共享电荷,输出不会低于阈值电压,因此在再生阶段可以更快地对输入信号进行比较。这加快了操作速度 [10, 11]。由于该技术,显著

低电压低功耗高速双尾电流动态锁存比较器的分析与设计
3 提出的共享电荷双尾比较器(PSCDTC)(续)
延迟的改善以及功耗的降低,在实现结果中得到验证和支持。
3.1 所提出的比较器的操作
所提出的比较器的操作可以从图6中理解。当时钟处于地电位时,晶体管Mtail1和Mtail2N被关断,从而防止了静态功耗。在此阶段,晶体管M3和M4将端子fn和 fp拉至电源电压(Vdd)。因此,这继而导通晶体管 MR1和MR2。在该复位阶段,晶体管CS将两个输出端 Outn和Outp短接,使其作为共享电荷晶体管工作,并且电荷(在前一个评估阶段之后,其中一个端子处于 Vdd,另一个端子处于地电位)在两个端子Outn和 Outp之间共享。
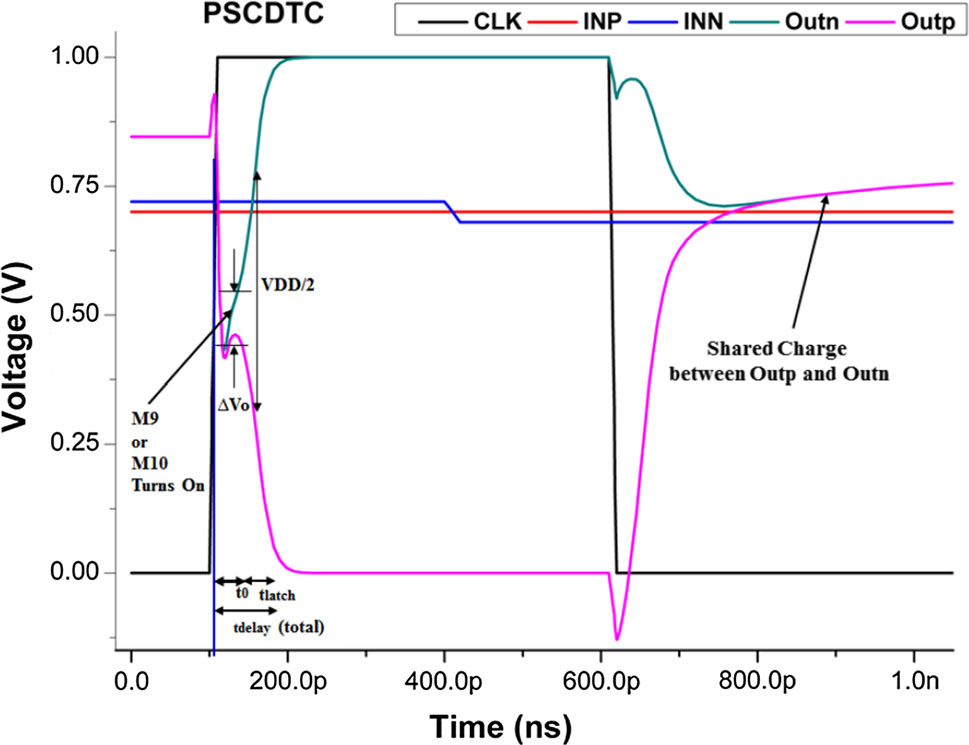
当时钟CLK接近V dd 时,电路进入评估阶段。在此阶段,晶体管Mtail1和Mtail2N导通,而复位晶体管(即M3和M4)关断。现在,fn和fp端子通过晶体管 M1和M2以不同的放电速率开始放电,放电速率由输入电压决定。假设V INN [V INP ,则fp的下降速度比fn快。如果我们假设输入电压的相反情况,则这一现象会有所不同。该架构功能中唯一的区别是,在评估阶段判决并非从电压电平的两个极端点开始,而是两个输出端子都接近于电源电压电平的一半。尽管输出端子的初始条件处于电源电压的一半,但它所需评估时间更短,且功耗更低。延迟分析支持这一理论概念。
3.2 延迟分析
已经推导出延迟的理论表达式,如同之前为两种架构(即STDLC和DTDLC)所进行的推导一样,以展示采用双尾电流动态锁存比较器和共享电荷逻辑的改进结构所带来的影响。分析方法与传统双尾电流动态锁存比较器类似。所提出的比较器在延迟和功耗参数方面相较于STDLC和DTDLC以及文献中提出的两种架构均有提升[16],,这两种架构分别为改进型双尾电流动态锁存比较器(MDTDLC,图5(a)[16])和改进型双尾电流动态锁存比较器‐2(MDTDLC2,图5(b)[16])。
在此,所提出的比较器架构中改进了两个参数,即再生阶段开始时的DV0 和有效跨导,以改善延迟性能。总延迟再次分为两项:t 0 和t latch 。其中t 0 根据以下公式 (12)求得:
$$
t_0 = \frac{C_L \cdot (V_{dd} - 2V_{thp})}{I_{tail2}}
\tag{12}
$$
这里,IB1(或IB2)是M9(或M10)的漏极电流,其值约等于Itail2/2。与之前的DTDLC比较器类似,DV0推导如下:
$$
DV0 = \frac{2 \cdot (V_{dd} - V_{thp}) \cdot g_{mR1,2} \cdot DV_{fn(fp)}}{I_{tail2}}
\tag{13}
$$
现在,DVfn/fp可以如下求得,将此结果以及公式(12)代入公式(13)
$$
DV_{fn/fp} = \frac{g_{m1,2} \cdot DV_{in}}{C_{L;fn(fp)}} \cdot \frac{C_L \cdot (V_{dd} - 2V_{thp})}{I_{tail2}}
\tag{14}
$$
代入DVfn/fp到公式(13)中,得到初始电压差值DV0如下:
$$
DV0 = \frac{2 \cdot (V_{dd} - V_{thp}) \cdot (V_{dd} - 2V_{thp})}{I^2_{tail2}} \cdot \frac{g_{mR1,2} \cdot g_{m1,2} \cdot C_L}{C_{L;fn(fp)}} \cdot DV_{in}
\tag{15}
$$
结合式(12)和(14)得到ttotal,
$$
t_{total} = \frac{(V_{dd} - 2V_{thp}) \cdot C_L}{I_{tail2}} + \frac{C_L}{g_{m(eff)}} \cdot \ln \left( \frac{V_{dd} \cdot I^2_{tail2} \cdot C_{L;fn(fp)}}{4 \cdot (V_{dd} - V_{thp}) \cdot (V_{dd} - 2V_{thp}) \cdot g_{mR1,2} \cdot g_{m1,2} \cdot C_L \cdot DV_{in}} \right)
\tag{16}
$$
公式(16)是所提出的比较器总延迟的解析方程。
4 仿真结果
为了将所提出的比较器与STDLC、DTDLC、MDTDLC(图5(a) [16])和MDTDLC2(图5(b)[16])进行比较,所有电路均在90纳米CMOS技术下使用 SPECTRE仿真器(Cadence)进行了仿真,电源电压 Vdd= 1为V,输入共模电压Vcm= 20为mV,时钟 CLK频率为= 1吉赫兹。对比较器进行了优化,并调整了晶体管尺寸,以在0.7 V的输入共模电压下获得 7.7 mV的相等失调标准差。表1总结了所提出比较器的各个参数结果(布局前仿真),而表2列出了前述四种架构(参考架构)与所提出比较器在延迟、功耗和能效积等性能参数方面的对比。表3显示了所提出比较器相对于参考比较器架构在这些参数上的百分比提升。
所提出的比较器和参考比较器的延迟和能效积在不同输入差分电压下的布局前仿真结果分别总结于表 4和5中。从表4可以看出,与其它参考比较器相比,所提出的比较器在所有输入差分电压范围内的延迟均为最低。就功耗和能效积而言,从表5中也可看出,其在所有范围内同样保持最低。
通常,在双尾电流结构中,与传统动态结构相比,比较器的延迟受输入共模电压变化的影响较小,因此具有更宽的
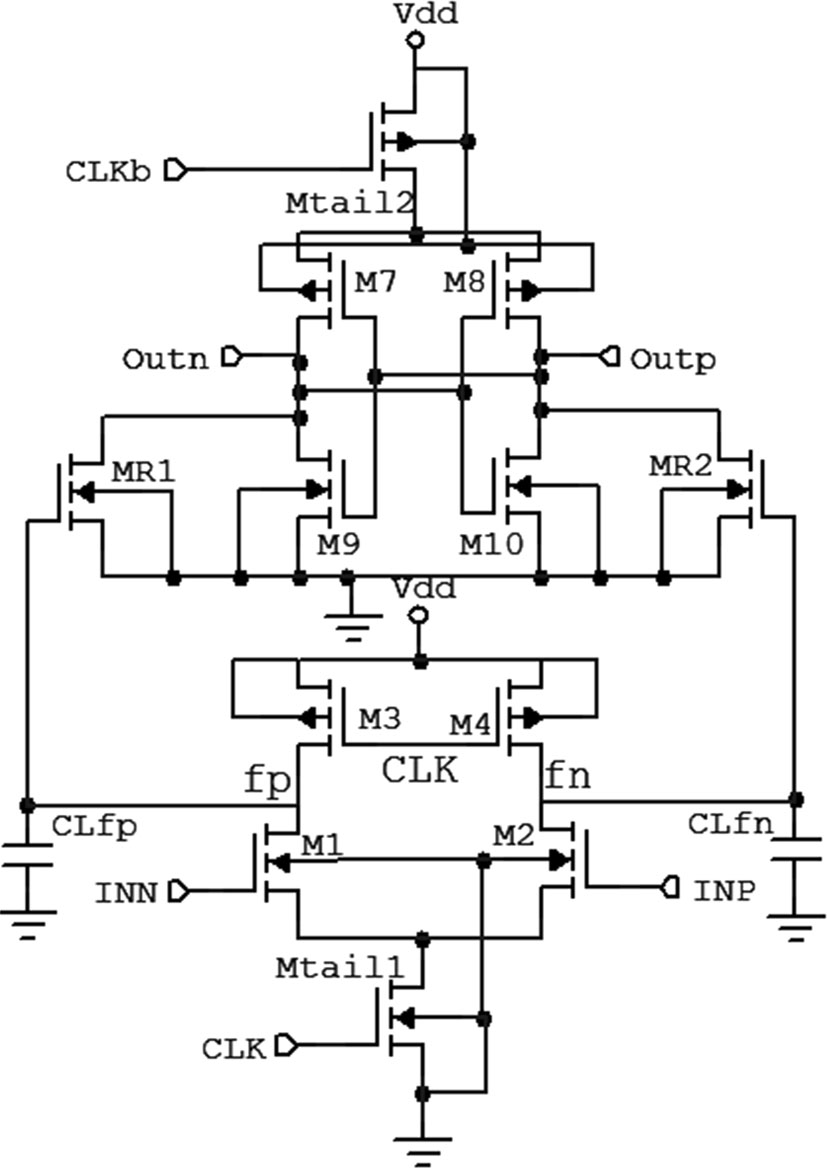
表1 所提出的比较器性能总结(布局前)
| 参数 | 数值 |
|---|---|
| 工艺 | 90 纳米 |
| 电源电压(伏特) | 1 |
| 功耗(微瓦) | 31.80 |
| 工作频率 | 1 吉赫兹 |
| 延迟(皮秒) | 50.9 |
| 功耗延迟积(PDP)(飞焦) | 1.62 |
| 失调电压(毫伏) | 7.7 |
| 输入共模范围 (ICMR)(毫伏) | 100–700 |
表2 比较器性能总结
| 比较器拓扑结构 | 晶体管数量 | 延迟(皮秒) | 功耗(微瓦) | PDP(飞焦) |
|---|---|---|---|---|
| STDLC | 9 | 77.7 | 26.89 | 2.09 |
| DTDLC | 14 | 66.4 | 52.40 | 3.48 |
| MDTDLC | 16 | 54.5 | 147.70 | 8.05 |
| 多斜率动态充电2 | 18 | 56.7 | 134.60 | 7.63 |
| PSCDTC | 13 | 50.9 | 31.80 | 1.62 |
V diff = 20 mV,V cm = 0.7 V,V dd = 1 V,时钟 = 1 GHz
表3 所提出的比较器相对于其他参考比较器在延迟、功耗和能效积方面的百分比(%)提升
| 拓扑结构 | 参数 | 延迟 | 功耗 | PDP |
|---|---|---|---|---|
| STDLC | 52.65 | -14.99 | 29.78 | |
| DTDLC | 30.45 | 64.78 | 80.23 | |
| MDTDLC | 7.07 | 366.96 | 399.99 | |
| 多斜率动态充电 2 | 11.36 | 323.27 | 371.34 |
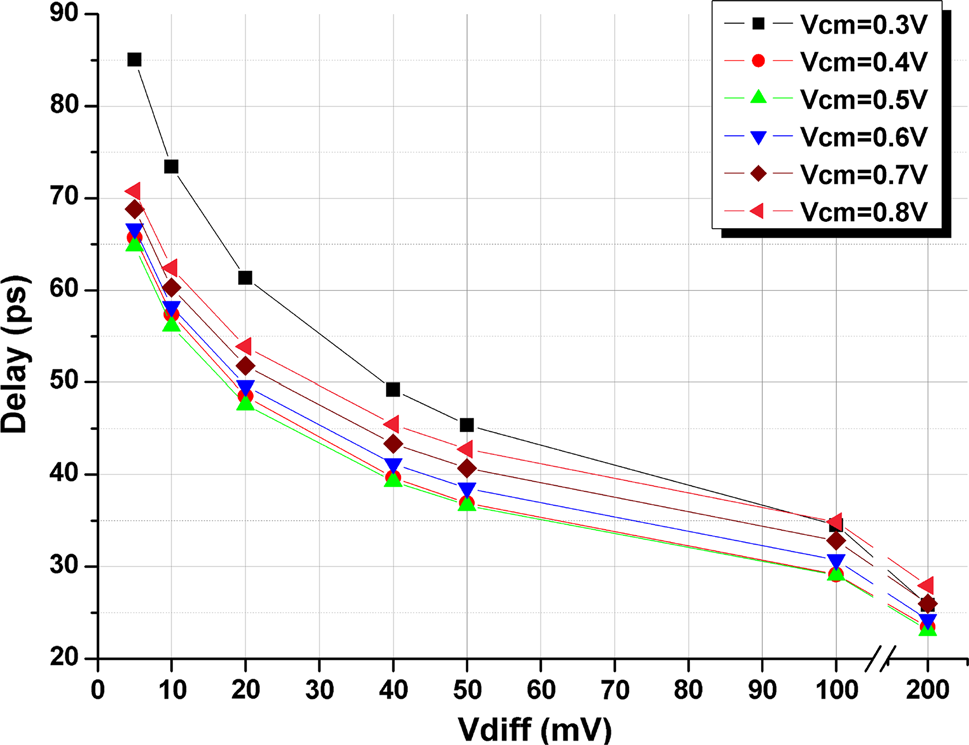
共模范围。针对所提出的比较器,在1伏特电源电压和 1吉赫兹时钟频率下,对不同共模电压电平下的参数随输入差分电压的变化进行了仿真。
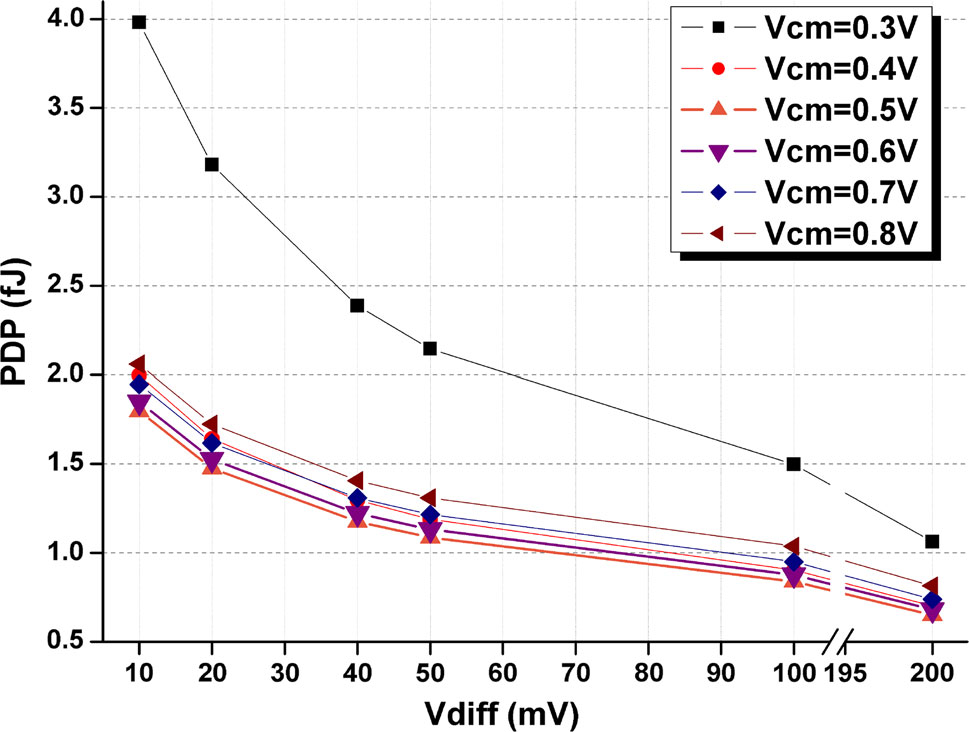
在不同电源电压下,差分输入电压对能效积的影响已通过仿真,并将结果展示于图9中。为了验证所提出的比较器的有效性,对STDLC、DTDLC、MDTDLC(图5(a) [16])以及PSCDTC(提出的架构)进行了布局前和布局后仿真。在布局过程中特别注意避免影响
表4 所提出的比较器在不同输入共模电压(Vcm)下,延迟(皮秒)随输入电压差(Vdiff)变化的总结
| Vdiff(mV) | 比较器拓扑,延迟(皮秒) | |||
|---|---|---|---|---|
| STDLC | DTDLC | MDTDLC | PSCDTC | |
| 5 | 105.6 | 84.0 | 71.4 | 67.5 |
| 10 | 93.4 | 75.7 | 81.0 | 59.2 |
| 20 | 77.7 | 66.4 | 71.7 | 50.9 |
| 40 | 69.0 | 58.1 | 63.6 | 42.7 |
| 50 | 65.0 | 55.6 | 61.3 | 40.1 |
| 100 | 53.2 | 48.4 | 53.7 | 32.3 |
| 200 | 43.5 | 42.2 | 46.8 | 25.6 |
Vcm= 0.7 V,Vdd= 1 V,时钟 = 1 GHz
表5 所提出的比较器在不同输入共模电压(Vcm)下,能效积 PDP(飞焦)随输入电压差(Vdiff)的变化总结
| Vdiff(mV) | 比较器拓扑,PDP(飞焦) | |||
|---|---|---|---|---|
| STDLC | DTDLC | MDTDLC | PSCDLC | |
| 5 | 3.3 | 4.6 | 10.7 | 2.3 |
| 10 | 2.8 | 4.8 | 11.7 | 1.9 |
| 20 | 2.2 | 4.1 | 10.2 | 1.6 |
| 40 | 1.8 | 3.5 | 8.9 | 1.3 |
| 50 | 1.7 | 3.4 | 8.5 | 1.2 |
| 100 | 1.3 | 2.8 | 7.4 | 0.9 |
| 200 | 1.0 | 2.3 | 6.0 | 0.7 |
V cm = 0.7 V,V dd = 1 V,时钟 = 1吉赫兹
比较器的延迟和功耗。图10显示了所提出的比较器的原理布局图。表6给出了版图前后仿真结果的对比。可以看出,所提出的比较器的近似面积需求总体上相当或最小。
由于输入差分电压和共模电压是重要参数,因此在布局前和布局后对不同输入电压和各种输入共模电压下的所提出比较器进行了仿真。图11和12分别显示了该仿真的延迟和能效积结果。
通过广泛认可的性能指标(FoM)对不同先进比较器架构的性能进行比较 [28]。因此,在本研究中,为了衡量设计的性能,采用如下公式(17)计算性能指标(FoM):
$$
FoM = \frac{P_d}{2^n \cdot f_s}
\tag{17}
$$
其中 Pd 为功耗,n 为位数(分辨率,其与偏移电压直接相关,并按 0.5 LSB 分辨率计算),fs 为比较器的采样频率(时钟频率)。表7总结了所提出的动态比较器的布局后性能。
随着工艺的缩小以及制造复杂度的增加,所有比较器均在不同工艺角(FF、FS、NN、SF和SS)下进行了布局前和布局后仿真。图13和 14分别展示了工艺角变化(版图前后)对所提出的比较器与参考比较器在(a)延迟和(b)能效积方面影响的对比。结果表明,所提出比较器的性能参数在所有工艺角下变化不大。
表6 布局前与后处理布局仿真结果比较
| 结果 | 比较器拓扑结构 | 预处理/后处理 | 延迟(皮秒) | 功耗(微瓦) | PDP(飞焦) | 布局面积 |
|---|---|---|---|---|---|---|
| STDLC | Pre | 77.7 | 26.89 | 2.09 | – | |
| Post | 84.4 | 28.30 | 2.39 | 7.23 × 7.575 mm² (54.77 mm²) | ||
| DTDLC | Pre | 66.4 | 43.70 | 2.90 | – | |
| Post | 72.8 | 52.40 | 3.81 | 7.84 × 7.15 μm² (56.77 μm²) | ||
| MDTDLC | Pre | 54.5 | 147.70 | 8.05 | – | |
| Post | 72.7 | 154.10 | 11.20 | 8.99 × 9.295 μm² (83.56 μm²) | ||
| PSCDTC | Pre | 50.9 | 31.63 | 1.61 | – | |
| Post | 51.8 | 32.62 | 1.69 | 7.2 × 8.1 μm² (58.32 μm²) |
V cm = 0.7 V, V dd = 1 V, 时钟 = 1 GHz, V diff = 20mV, 预处理 (布局前), 后处理 (布局后)
 时输入差分电压对延迟的影响(布局前和布局后))
时输入差分电压对延迟的影响(布局前和布局后))
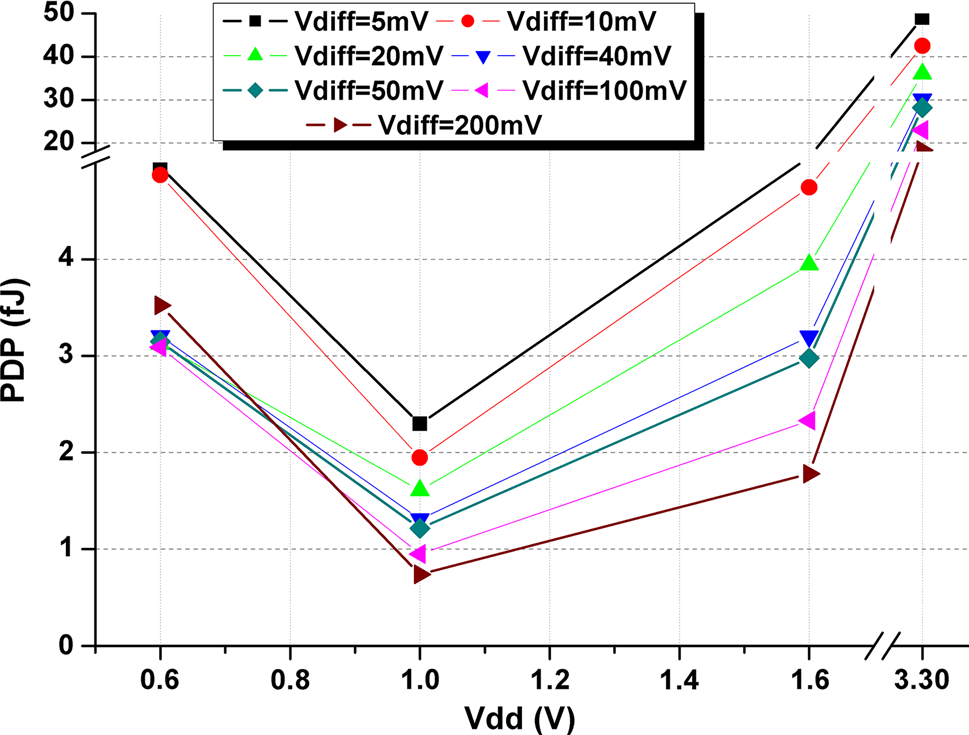 时输入差分电压对能效积的影响(布局前和布局后))
时输入差分电压对能效积的影响(布局前和布局后))
表7 所提比较器性能总结
| Item | 数值 |
|---|---|
| 技术(纳米) | 90 纳米 |
| 电源电压(伏特) | 1 V |
| 时钟频率 | 1 吉赫兹 |
| 晶体管数量 | 13 |
| 延迟(皮秒) | 51.76 |
| 功耗(微瓦) | 32.62 |
| PDP(飞焦) | 1.69 |
| 估计面积 | 7.2 × 8.1 μm² (58.32 μm²) |
| 优值(fJ/转换) | 0.5 |
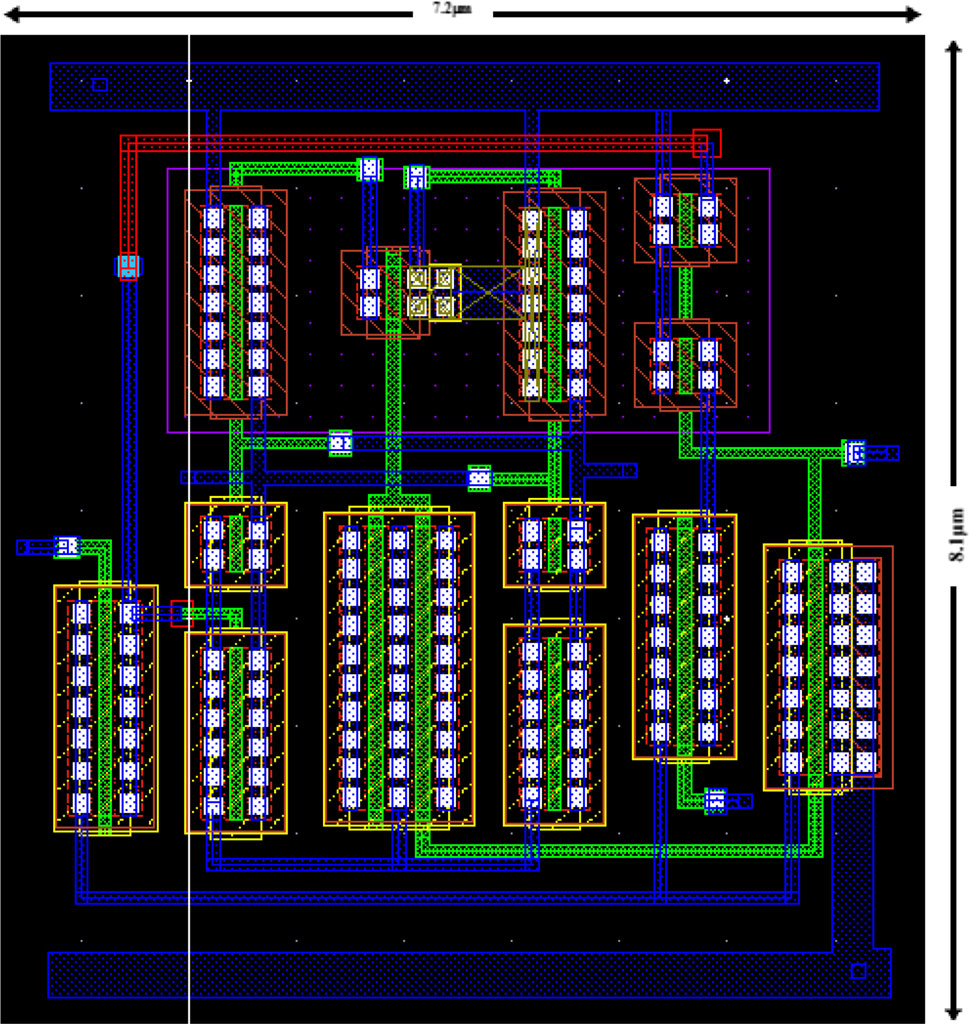
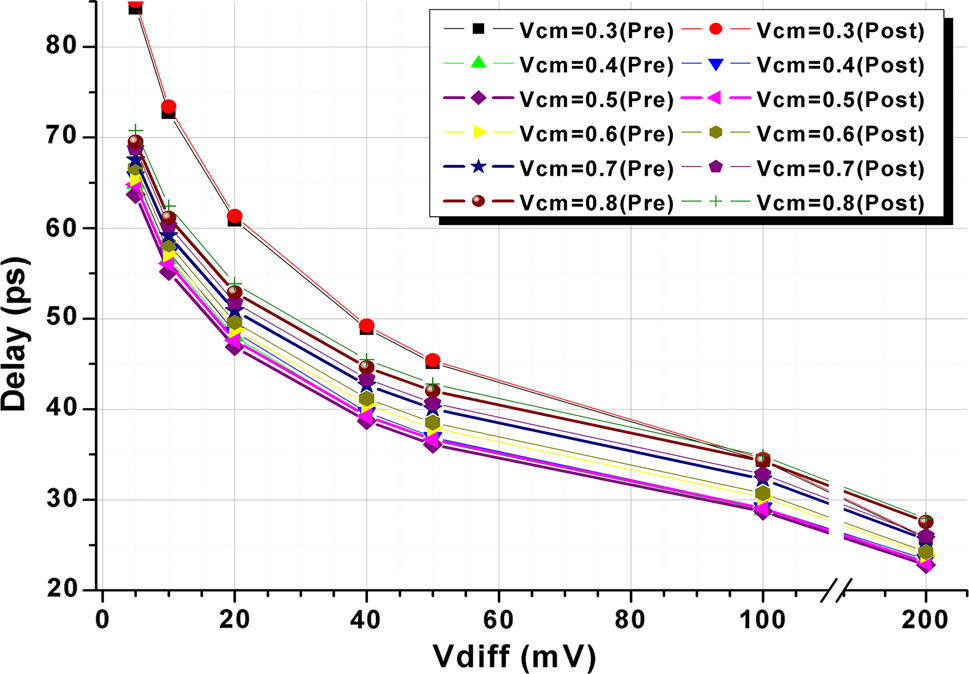
表8 性能评估
| 比较器特性 | [13] | [14] | [26] | [27] | 本研究(PSCDTC) |
|---|---|---|---|---|---|
| Year | 2009 | 2007 | 2013 | 2015 | – |
| 工艺(纳米) | 65 | 90 | 180 | 65 | 90 |
| 电源电压(伏特) | 1.2/0.65 | 1.2 | 0.5 | 0.6/0.9 | 1 |
| 时钟频率(赫兹) | 5G/0.6G | 1G/2G | 5M | 1.3G/3.3G | 1G |
| 晶体管数量 | 13 | 12 | 9 | 26 | 13 |
| 延迟(秒) | 104p/650p | 20p | 16.4n | – | 51.76p |
| 功率(瓦) | 2.88m/128l | 113l/225l | 20.2n | 64升/472升 | 32.62升 |
| PDP(飞焦) | 299/83.2 | 2.3 | 0.33 | 49.2/143 | 1.69 |
| 估计面积 (μm × μm 或 μm²) | 28.4 × 49.1 | 11 × 7.5 | – | 265 | 7.2 × 8.1 |
| 优值(fJ/转换) | 2.91 | 0.75 | – | 1.25/0.94 | 0.5 |
5 结论
本文对传统的动态锁存时钟比较器(即单尾和双尾电流动态锁存比较器)的判决延迟进行了详细分析。基于对这两种比较器的分析,并结合共享电荷逻辑的概念,提出了一种动态锁存比较器,以提高传统比较器的性能参数。仿真在90纳米CMOS技术下进行,结果证实延迟、功耗和PDP等参数得到了显著改善。与单尾电流动态锁存比较器、双尾电流动态锁存比较器、参考文献[16][(a)和(b)]中的比较器相比,所提出的比较器在PDP上的百分比提升分别为30%、80%、399% 和371%。同时还进行了参数分析,确认所提出比较器的性能参数不随工艺偏差而变化。为了支持分析结果,进行了布局前与布局后仿真以及工艺角变化仿真。结果表明,就延迟、PDP和面积而言,所提出的比较器提供了最佳架构。


















 4997
4997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









