




 本文介绍了字节序的概念,包括大端和小端的存储方式,并通过示例展示了如何测试计算机硬件的字节序。在Java中,字节码文件采用大端存储,但JVM的实现可能依赖于底层硬件的小端存储,因此在读取字节码时需要处理字节序问题。此外,文章提及了字节码文件的魔数校验过程中的字节序处理。
本文介绍了字节序的概念,包括大端和小端的存储方式,并通过示例展示了如何测试计算机硬件的字节序。在Java中,字节码文件采用大端存储,但JVM的实现可能依赖于底层硬件的小端存储,因此在读取字节码时需要处理字节序问题。此外,文章提及了字节码文件的魔数校验过程中的字节序处理。
目录
前面说到,像C/C++这类语言编写的程序,它们被编译后,直接转换成了对应平台上的可被CPU直接运行的机器指令,转换之后,原本语言中的数据结构,例如结构体信息都被替换掉了,换成了各个数据在内存中的地址和偏移量,操作系统并不知道原来的数据的类型,例如一段C程序被编译成汇编语言后,结构体信息被拆成了一条条对内存操作的指令,一个个变量都变成了首地址,原本的C代码结构不复存在。Java则不同,我们知道Java语言因为跨平台性的原因,程序在转变成机器可执行的指令之前,需要先翻译成中间语言-字节码文件,字节码有它特定的结构,会将Java中的类型结构信息存储起来,待JVM加载字节码文件时,会保存所有的元数据,元数据也就是原始的类型信息,上篇日志中opp-klass模型里的instanceKlass,它保存了Java类的所有信息,例如里面的方法和变量,也正因为了有了这种机制,JVM才支持“反射”,运行Java程序在运行期间能够动态获取实例对象的类型,方法等信息。
字节序
Java语言实现跨平台性,执行前先被编译成统一字节码文件,.class文件与平台无关,只与JVM有关,之后在不同的操作系统环境(Linux,Windows之类)下由不同的JVM来解释执行.class文件,虽然同一Java程序生成的字节码文件相同,但数据在不同平台上的存储方式是不同的。我们知道,字节数据在计算机中存储,或者在网络中收发,是要按照一定的顺序的,这种字节输入输出和存储的顺序,即字节序,在不同的硬件环境中有所不同。拿网络中收发数据包来举例,在传输层发送的数据包如果太大,就会被拆分成多个包,每一个小的数据包都有序号,接收方接收到每一个包都要按照顺序组装成一个完整的包,这样即使按顺序先发出去的1号包没有被先接收,而是先接收到2号包,接收方也会等待,待1号包接收后先将其递交给上层,如果不严格按照顺序收发,存储,那么通信双方发送的数据就无法正确译码。
大端和小端
前面说到不同的操作平台上,数据存储在内存和磁盘,或者寄存器上的格式是不同的,具体表现在存储顺序不同,通常分为两种方式,大端Big-Endian和小端Little-Endian方式,大端方式即将数据中高位的字节存放在内存中的低地址处,数据中低位的字节存放在内存中的高地址处,小端方式则相反,高位字节存放在高地址,低位字节存放在低地址。上面举例的网络中收发数据包,因为使用TCP/IP协议的缘故,字节数据使用大端的方式。
举个例子看大端和小端的存储方式,假设有一个十六进制数据0x12345678,占4个字节,要存储到内存地址0x004060处,使用大端的方式,即数据的高位字节存放到内存地址的低地址端,低位字节放到高地址端,那么存放的对应关系如下:
| 内存地址 | 0x004060 | 0x004061 | 0x004062 | 0x004063 |
| 数据值 | 12 | 34 | 56 | 78 |
可以看到, 数据字节增长方向和内存地址增长方向是相同的,这种方式比较方便我们程序员阅读,而如果使用小端方式存储,它的对应关系是这样:
| 内存地址 | 0x004060 | 0x004061 | 0x004062 | 0x004063 |
| 数据值 | 78 | 56 | 34 | 12 |
相比大端来说不易于程序员阅读。
产生大端小端存储方式的原因是寄存器的宽度,计算机内存存储单元为1个字节,现在的CPU普遍都是32位或64位,意味着其可以一次传输4字节或8字节的数据,,大多数寄存器的宽度也不止一个字节,所以寄存器可以一次读出多个连续内存存储单元的值,也能一次往多个连续存储单元写入数据。我们知道,数据不能直接在内存之间传输,必须通过寄存器中转,例如我们平时写的代码int a = b;它就是先把内存中b的数据读取到寄存器里,再把寄存器里的数据放到a的内存位置。假设我们现在有一个2字节的十六进制数据0x0205,十进制表示517,数据的高字节为02,低字节为05,将它放到寄存器里,如果寄存器采用大端方式存储,即02存放到低地址位,05存放到高地址为,那么数据在寄存器中的值就是0x0205,这个没什么问题,但如果寄存器采用小端方式存储,那么0x0205存储到寄存器后,值就变为0x0502,其对应的十进制就变成了1282。
大端小端测试
我们可以用个简单的测试程序来看看自己的硬件CPU是大端还是小端存储:
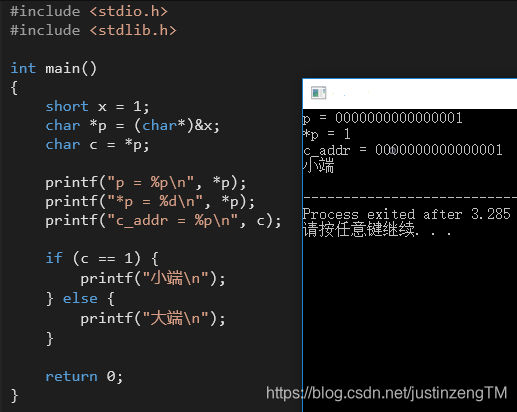
例子很简单,通过char c = *p拿到变量x的地址,如果系统采用的是小端存储方式,那么地址的低位会被存放在高地址处,x的首地址就是0x1,否则x的首地址就是0。从输出结果可以看到,我这台计算机采用的是小端方式存储。
写入测试
上面的测试程序是我们向操作系统申请空间,接下来用另一个例子,我们往内存中写入数据,看看计算机是不是也会以小端方式帮我们存储:
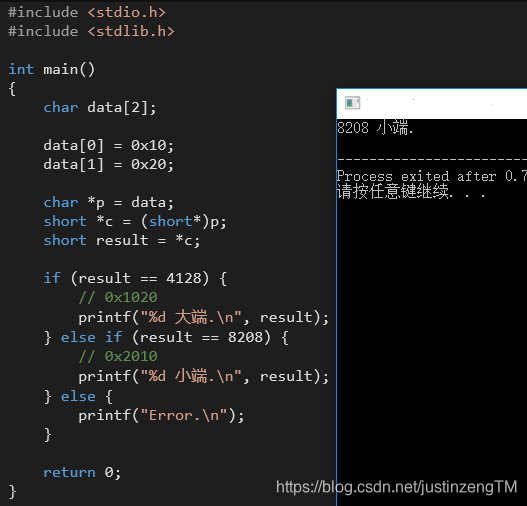
上面这个例子中,我们向一个数组里写入两个字节的数据,0x10和0x20,然后通过char *p = data拿到data数组的首地址,强制类型转换short*指针,最后转换成short类型,如果你的CPU使用的是大端方式存储,那么写入数组的数据从左到右,也就是从低地址位到高地址位的排列顺序是0x1020,十进制表示为4128。如果采用的是小端方式,那么高字节位数据存放在高地址处,最后存储的数据变成0x2010,对应十进制8208。
字节码文件的大小端
上面两个例子的运行结果,都表现出在我的计算机上使用的是小端方式存储,但在Java程序编译得到的字节码文件里,使用的全部都是大端方式,例如JVM在加载字节码文件时,首先会检查最前面4个字节的魔数,它是一个固定值0xCAFEBABE,它的写入顺序就是0xCA、0XFE、0xBA、0xBE。数据写入没有问题,因为它是由Java语言完成,使用大端方式,但是读取时就有地方要注意了,JVM使用C和C++编写,它们采用大端还是小端是取决于当前的硬件平台,当其读取.class字节码文件时,魔数在C语言中可以用int型表示,如果当前环境采用了小端方式存储,那么魔数的读取就会得到0xBE、0xBA、0xFE、0xCA,此时读到的魔数就和上面的Java程序相反了,会导致JVM校验魔数失败,停止加载.class字节码文件。如果是使用Java编写的编译器,就不需要对数据字节序进行处理,但JVM是C和C++编写的,如果运行在了采用小端方式存储的平台上,那就要对字节序进行反转处理了,对字节序进行反转处理。
以前我写网络编程的时候也才踩过这类坑,服务器连不上,后来发现要将地址逆序。



















 1126
1126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









