




在当今数据爆炸的时代,存储技术的性能往往决定着整个计算系统的效率。正如城市交通网络中,道路宽度、车辆速度和交通管理系统共同决定了通行效率一样,在计算机存储领域,SSD(固态硬盘)、PCIe(高速串行计算机扩展总线标准)和 NVMe(非易失性内存主机控制器接口规范)分别扮演着停车场、高速公路和交通信号灯的角色,三者协同工作构筑了现代计算的数据流通枢纽。本文将从专业角度深入剖析这三项技术的架构设计、演进历程与创新实践,带领读者全面理解现代高性能存储技术的原理、挑战与未来发展方向。
存储技术的范式转移
存储系统是计算机架构中发展最为迅猛的领域之一。传统机械硬盘(HDD)基于旋转磁介质和物理磁头,其性能瓶颈日益凸显。与此相反,基于闪存(NAND Flash)的固态硬盘(SSD)以其高性能、低功耗、强抗冲击等优势,正迅速取代HDD成为主流存储介质。然而,存储介质的变革仅仅是开始,接口协议和系统架构的革新同样至关重要。
PCIe总线作为CPU与外围设备通信的“主干道”,为高速存储设备提供了充足的带宽。而NVMe协议则是专为闪存特性设计的先进接口规范,彻底释放了PCIe总线的潜力。这三者共同构成了现代高性能存储系统的核心技术栈,推动着从消费级设备到企业级数据中心的全面变革。
深入了解这些技术的内在原理与发展脉络,对于架构师、系统设计师和性能优化工程师至关重要。只有深入掌握存储栈各层级的工作机制,才能在设计系统时做出合理的架构决策,充分发挥硬件性能,应对日益增长的数据处理需求。
SSD核心技术剖析
固态硬盘是一种基于闪存芯片的存储设备,其内部架构远比传统机械硬盘复杂。要理解SSD的创新设计,首先需要了解其核心组成部分及工作原理。
闪存物理特性与存储机制
闪存是一种非易失性存储介质,即使断电也能保留数据。它采用浮栅MOSFET作为基本存储单元,通过浮栅中捕获的电荷量来表示数据。根据每个存储单元存储的比特数,闪存主要分为SLC(单层单元)、MLC(多层单元)、TLC(三层单元)和QLC(四层单元),它们的密度和可靠性逐次递增,但寿命和性能也逐次降低。
闪存具有三大基本特性,这些特性深刻影响了SSD的架构设计:
-
写前擦除:闪存无法直接覆盖写入,必须在写入前先执行擦除操作,而擦除操作的最小单位(块)远大于写入的最小单位(页)。
-
有限寿命:每个闪存块只能承受有限次数的擦写循环,超过这一次数后,存储单元的可靠性将急剧下降。
-
读干扰:读取某一页的数据可能会对同一块中其他页的数据造成干扰,需要定期进行数据刷新。
为了应对这些挑战,SSD中引入了专门的闪存转换层(FTL),负责将主机的逻辑地址映射到闪存的物理地址,并实施垃圾回收、磨损均衡等一系列复杂的管理算法。
FTL核心算法与创新设计
FTL是SSD固件的核心组件,其设计质量直接决定了SSD的性能、寿命和可靠性。创新的FTL算法需要在有限的控制器资源下,实现高效的地址映射、垃圾回收和磨损均衡。
地址映射管理
地址映射是FTL最基本的功能,负责维护逻辑块地址(LBA)到物理块地址(PBA)的转换关系。根据映射粒度,主要分为页级映射、块级映射和混合映射三种策略。页级映射灵活性强但内存开销大,块级映射内存开销小但灵活性差。
近年来,研究者提出了多种创新映射方案。例如PBFTL(Page-to-Block Mapping FTL)机制为每个更新的页面分配专用更新块,每个更新块最多包含一个有效页面。在进行垃圾回收时,PBFTL要么仅迁移单个页面,要么仅擦除整个块,显著减少了垃圾回收对用户请求造成的阻塞时间,使读写延迟平均降低15%。
// FTL映射表查询的简化代码示例
struct ftl_mapping_table {
uint32_t logical_page; // 逻辑页号
uint32_t physical_block; // 物理块号
uint32_t physical_page; // 物理页号
bool valid; // 映射是否有效
int wear_count; // 磨损计数
};
// 查找逻辑地址对应的物理地址
struct physical_addr ftl_lookup(struct ftl_mapping_table *table,
uint32_t logical_addr) {
struct physical_addr phys_addr = {0};
uint32_t page_index = logical_addr / PAGE_SIZE;
// 检查映射是否存在且有效
if (table[page_index].valid) {
phys_addr.block = table[page_index].physical_block;
phys_addr.page = table[page_index].physical_page;
// 更新访问统计信息,用于磨损均衡
update_access_stats(table, page_index);
} else {
// 触发按需分配机制
phys_addr = allocate_new_physical_block(table, logical_addr);
}
return phys_addr;
}
垃圾回收机制
由于闪存的写前擦除特性,当块中含有无效数据时,需要启动垃圾回收过程,将有效数据迁移到新块,然后擦除旧块以供重用。垃圾回收会引发写放大问题——即实际写入闪存的数据量大于主机请求的数据量,这不仅消耗带宽,还会缩短闪存寿命。
创新性的垃圾回收算法致力于降低写放大。例如,基于热度分离的策略将高频更新数据(热数据)和低频更新数据(冷数据)分离存放,减少垃圾回收时需要迁移的有效数据量。研究表明,通过智能的热点数据识别机制,可以将SSD寿命延长6倍以上,缓存命中率提高超过10%。
磨损均衡策略
为确保所有闪存块相对均匀地消耗,延长SSD整体寿命,FTL必须实施磨损均衡策略。磨损均衡分为动态均衡(将新数据写入磨损较少的块)和静态均衡(定期迁移冷数据以平衡磨损)两种。
先进的磨损均衡算法不仅考虑擦除次数,还会结合错误率趋势、数据保留期等因素做出综合决策。例如,当某一块的错误率开始上升时,即使其擦除次数尚未达到阈值,也可能被提前标记为坏块,停止使用。
表:不同闪存类型的特性对比
| 闪存类型 | 每个单元的比特数 | 理论擦写次数 | 读取延迟 | 写入延迟 | 主要应用场景 |
|---|---|---|---|---|---|
| SLC | 1 | 50,000-100,000 | 极低 | 极低 | 企业级关键应用 |
| MLC | 2 | 3,000-10,000 | 低 | 低 | 企业级、高端消费级 |
| TLC | 3 | 1,000-3,000 | 中等 | 中等 | 主流消费级 |
| QLC | 4 | 100-1,000 | 高 | 高 | 大容量存储 |
3D NAND与未来存储介质
随着平面NAND技术逼近物理极限,3D NAND技术应运而生。3D NAND通过垂直堆叠存储单元的方式大幅提高存储密度,而不必缩小制程节点。自2012年三星推出首款3D NAND以来,堆叠层数已从24层增加到目前的290层以上,并向400层以上迈进。
在3D NAND领域,长江存储的Xtacking架构创新性地将存储单元阵列和外围电路分别制造在不同的晶圆上,然后通过金属垂直互联通道(VC)将二者键合,实现了更高的存储密度和更灵活的工艺选择。
展望未来,新型存储介质如相变存储器(PCM)、自旋转移矩磁存储器(STT-MRAM)和电阻式随机存储器(ReRAM)正在崛起。这些介质有望填补DRAM与NAND之间的性能鸿沟,构建更加层次化的存储体系。特别是英特尔与美光联合开发的3D XPoint技术,虽然已在市场上淡出,但其设计理念仍对后续技术发展具有重要参考价值。
PCIe总线技术深度解析
PCIe总线是现代计算系统中不可或缺的高速串行互联标准,为CPU与各种高速外设提供了高带宽、低延迟的通信通道。理解PCIe协议栈的各个层级对于设计高性能存储系统至关重要。
PCIe总线架构与拓扑
PCIe采用点对点串行连接架构,每个设备都有自己的专用链路,避免了传统PCI总线中共享总线架构带来的带宽竞争和扩展限制。PCIe拓扑结构包含根复合体(Root Complex)、端点(Endpoint)、交换机(Switch)和PCIe-PCI桥等基本组件。
-
根复合体:通常集成在CPU中,是PCIe拓扑的根节点,负责将CPU和内存与PCIe设备连接起来。
-
端点:如SSD、网卡等终端设备,实现PCIe协议定义的事务层、数据链路层和物理层功能。
-
交换机:提供多端口连接,实现端口间的数据路由和负载均衡。
PCIe链路由多个通道(Lane)组成,每个通道包含两对差分信号线(一发一收)。常见的通道配置有x1、x2、x4、x8和x16,通道数越多,总带宽越高。
物理层设计与信号完整性
PCIe物理层负责处理数据包的串行化与反串行化、加扰与解扰、编码与解码等任务。PCIe从1.0到6.0的发展过程中,数据速率从2.5 GT/s提升到了64 GT/s,每一代性能几乎翻倍。
为确保高速信号传输的完整性,PCIe物理层采用了多项创新技术:
-
8b/10b编码(PCIe 1.0-3.0)与128b/130b编码(PCIe 4.0+):通过添加额外比特来平衡直流成分,提供足够的信号跳变用于时钟恢复。
-
接收器均衡:使用连续时间线性均衡器(CTLE)和判决反馈均衡器(DFE)补偿信道损耗,减少码间干扰。
-
时钟数据恢复(CDR):从数据流中提取时钟信号,避免使用单独的时钟线。
以下图表展示了PCIe物理层发送路径的关键组件及其数据流:

事务层与数据包格式
PCIe事务层定义了事务层数据包(TLP)的格式,用于在设备间传输读写请求和完成消息。TLP包含头部、数据载荷(可选)和循环冗余校验(ECRC)等字段。
根据事务类型,TLP可分为:
-
存储器读写请求:用于CPU与设备间或设备与设备间的数据传输。
-
配置读写请求:用于在系统初始化时发现和配置PCIe设备。
-
消息信号中断(MSI):允许设备向CPU发送中断请求,而无需专用的中断线。
// PCIe TLP头部结构示例(存储器读请求)
struct tlp_header {
// 通用头部字段
uint8_t fmt_type; // 格式和类型字段
uint8_t tc; // 流量类别
uint8_t attr; // 属性字段
uint16_t length; // 数据载荷长度
uint16_t requester_id; // 请求者ID
uint8_t tag; // 事务标签
uint8_t last_be; // 最后字节使能
uint8_t first_be; // 首字节使能
// 地址相关字段
uint64_t address; // 目标地址
};
// 构建存储器读请求TLP
void build_mem_read_tlp(struct tlp_header *header, uint64_t addr,
uint16_t length, uint8_t tag) {
header->fmt_type = 0x00; // 无数据3DW头部的存储器读
header->tc = 0; // 默认流量类别
header->attr = 0; // 默认属性
header->length = length; // 请求的数据长度
header->requester_id = get_requester_id();
header->tag = tag; // 唯一事务标识
header->address = addr; // 目标地址
// 计算并填充ECRC
header->ecrc = calculate_ecrc(header);
}
PCIe复位与电源管理
PCIe定义了多种复位机制,包括传统复位、功能级复位(FLR)和热复位,用于在不同场景下重新初始化设备状态。电源管理方面,PCIe支持主动状态电源管理(ASPM)和运行时电源管理(RPMP)等技术,在无活跃事务时自动进入低功耗状态,显著降低系统能耗。
在存储系统中,合理的PCIe电源管理策略能在性能与功耗间取得平衡。例如,在轻负载时段让SSD进入低功耗状态,而在检测到I/O请求时快速恢复到全功率状态。
NVMe协议革命性设计
NVMe协议是专为基于PCIe的固态存储设计的先进接口规范,它从底层重新思考了存储协议应如何适应现代非易失性存储介质的特性,彻底释放了SSD的性能潜力。
从AHCI到NVMe的范式转移
在NVMe出现之前,大多数SSD使用为机械硬盘设计的AHCI(高级主机控制器接口)协议,通过SATA或SAS接口与系统连接。AHCI存在以下根本性限制:
-
单一提交队列:AHCI只支持一个命令队列,队列深度最多32条命令,无法充分利用SSD的并行性。
-
高开销:每次I/O操作需要四次内存映射I/O(MMIO)寄存器访问,产生大量不必要的CPU开销。
-
缺乏并行性:无法有效支持多核处理器同时提交I/O请求。
NVMe针对这些问题进行了彻底重新设计,主要特性包括:
-
多队列支持:支持最多64K个I/O队列,每个队列深度可达64K条命令。
-
低软件开销:每个I/O操作只需一次MMIO寄存器写入,显著降低CPU利用率。
-
优化中断处理:支持多队列中断亲和性和中断聚合,减少中断开销。
-
增强的QoS:支持流量控制和端到端数据保护,确保服务质量。
NVMe队列机制与命令处理
NVMe的核心创新是其高效的队列机制。它使用提交队列(SQ)和完成队列(CQ)来管理主机与控制器之间的命令传递。主机将命令放入SQ,控制器处理完成后将完成状态放入CQ,并通过中断通知主机。
门铃寄存器是NVMe降低软件开销的关键设计。主机通过一次MMIO写入操作更新控制器的SQ尾指针或CQ头指针,无需像AHCI那样频繁访问多个寄存器。
// NVMe命令提交简化示例
struct nvme_sq_entry {
uint32_t dword0; // 命令DWORD 0
uint32_t namespace_id; // 命名空间标识符
uint32_t dword2;
uint32_t dword3;
uint64_t metadata; // 元数据指针
uint64_t prp1; // 数据指针1
uint64_t prp2; // 数据指针2
uint32_t dword10; // 命令特定字段
uint32_t dword11;
uint32_t dword12;
uint32_t dword13;
uint32_t dword14;
uint32_t dword15;
};
// 提交读取命令到NVMe队列
int nvme_submit_read(struct nvme_device *dev, uint64_t lba,
uint32_t block_count, void *buffer) {
struct nvme_sq_entry *cmd = get_free_sq_entry(dev->sq);
// 填充命令字段
cmd->dword0 = 0x02; // 读取命令OPC
cmd->namespace_id = 1; // 命名空间ID
cmd->prp1 = (uint64_t)buffer; // 数据缓冲区地址
cmd->dword10 = lba & 0xFFFFFFFF; // 起始LBA低32位
cmd->dword11 = (lba >> 32) & 0xFFFFFFFF; // 起始LBA高32位
cmd->dword12 = block_count - 1; // 块数量(0-based)
// 更新门铃寄存器,通知控制器有新命令
memory_barrier();
dev->doorbell = dev->sq_tail;
return 0;
}
以下序列图展示了NVMe命令的完整处理流程:
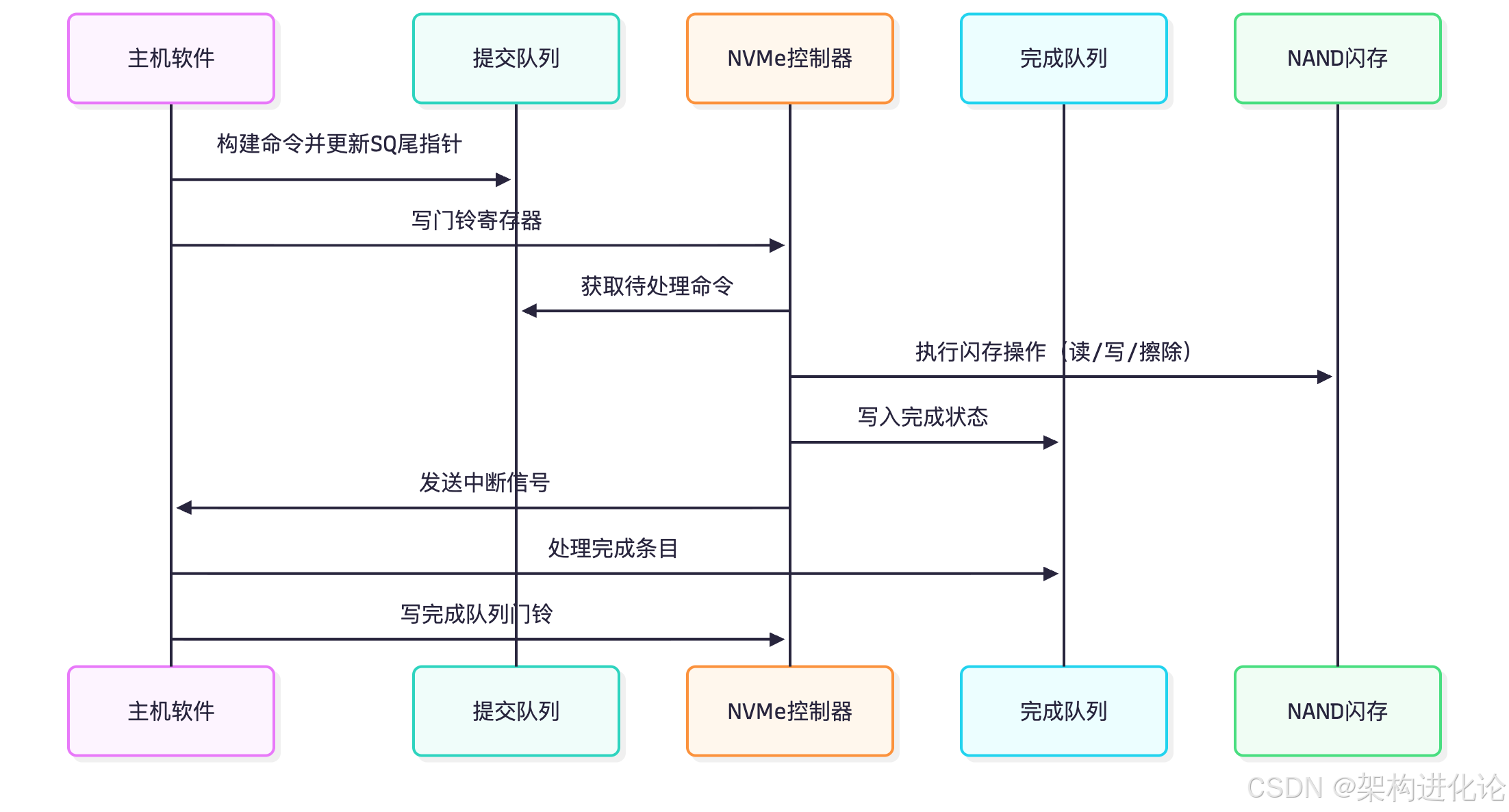
NVMe over Fabrics与扩展性
为应对分布式存储和云计算环境的需求,NVMe over Fabrics(NVMe-oF)协议将NVMe命令集扩展到网络结构上,支持通过RDMA、光纤通道和TCP等传输介质远程访问NVMe设备。
NVMe-oF允许在数据中心内构建解耦的存储架构,计算节点可以通过网络访问共享的NVMe存储池,实现更高的资源利用率和更灵活的资源调度。研究表明,在优化的网络条件下,NVMe-oF可以提供接近本地NVMe设备的性能。
性能优化与QoS保障
NVMe协议内含多项性能优化机制。多路径I/O和命名空间共享允许多个主机或应用程序共享访问同一NVMe设备,同时保持数据隔离。端到端数据保护通过元数据校验确保数据在传输过程中的完整性。
为了保障服务质量(QoS),NVMe 1.2引入了仲裁机制,支持多种仲裁策略(如加权轮询、严格优先级),确保高优先级任务获得必要的I/O资源。后续版本进一步增强了延迟监控和预测性性能管理功能,使系统能够主动识别和应对潜在的性能瓶颈。
创新架构设计与实践
将SSD、PCIe和NVMe技术有机结合,可以构建出多种高性能、高可靠的存储解决方案。本节将探讨几种创新架构设计及其在实际系统中的应用。
异构存储系统设计
现代数据中心通常采用异构存储架构,将不同类型的存储介质组合成统一的存储池,在性能、容量和成本间取得平衡。典型的层次化存储系统包括DRAM、非易失内存(NVM)、SSD和HDD等多个层级。
研究表明,NVM与SSD在I/O模式偏好方面存在很好的互补性。基于这一发现,研究者提出了UHS(超高速混合存储)系统,在NVM和SSD之上构建统一的块存储地址空间,并提供静态地址映射接口,为上层应用提供显式的数据亲和性分配策略。
UHS系统的创新点包括:
-
NVM缓冲区:使用NVM吸收针对SSD区域的小写请求,减少写入放大,延长SSD寿命。
-
条带化缓存空间:通过哈希索引降低缓存查询开销,提高并发访问性能。
-
解耦的I/O机制:分离用户线程与访问NVM的I/O线程,克服NVM内部并行度限制。
实验结果表明,UHS在多种工作负载下,相较于传统分层存储系统,最高可提升3.5倍至6倍的吞吐率。
硬件加速与定制化控制器
随着存储性能要求的不断提高,软件实现的NVMe控制器已成为瓶颈。近年来,硬件加速的NVMe控制器成为研究热点,通过FPGA或ASIC实现全硬件化的命令处理和数据传输。
全硬件NVMe控制器的关键优势包括:
-
低延迟:硬件逻辑直接处理NVMe命令,无需软件干预,大幅降低I/O延迟。
-
高吞吐:通过并行处理多个队列和命令,充分发挥PCIe带宽潜力。
-
低CPU占用:将CPU从繁重的I/O处理任务中解放出来,专注于应用逻辑。
一项研究显示,硬件实现的NVMe控制器在250MHz时钟频率、单个I/O队列情况下,读速度可达1.72GB/s,写速度可达1.83GB/s。
// 硬件NVMe控制器的简化DMA设计
struct dma_engine {
uint32_t control_status; // 控制状态寄存器
uint64_t src_addr; // 源地址
uint64_t dst_addr; // 目标地址
uint32_t transfer_size; // 传输大小
uint32_t config; // 配置寄存器
};
// DMA传输启动函数
void start_dma_transfer(struct dma_engine *dma, uint64_t src,
uint64_t dst, uint32_t size) {
// 配置DMA引擎参数
dma->src_addr = src;
dma->dst_addr = dst;
dma->transfer_size = size;
// 设置传输属性(内存到设备,块传输模式)
dma->config = DMA_DIR_MEM_TO_DEV | DMA_MODE_BLOCK;
// 启动DMA传输
dma->control_status = DMA_START;
// 等待传输完成或采用中断方式
while (!(dma->control_status & DMA_COMPLETE)) {
// 可在此添加超时检测
}
}
存储安全与可靠性增强
随着数据价值的不断提升,存储安全性和可靠性成为系统架构的关键考量。创新设计需要在保证性能的同时,提供强大的数据保护和容错机制。
加密存储是保护数据机密性的基本手段。现代SSD控制器通常集成硬件加密引擎,支持AES、国密算法等加密标准,实现对用户数据的实时加密解密。加密可以在多个层级实施——设备级加密透明保护整个设备,命名空间级加密提供更细粒度的数据保护。
安全启动和固件验证机制确保只有受信任的固件能在SSD上运行,防止恶意代码植入。安全擦除功能则允许用户快速、彻底地销毁设备上的所有数据,防止数据泄露。
在可靠性方面,LDPC(低密度奇偶校验)纠错技术已成为3D NAND的标配错误校正方案。与传统的BCH码相比,LDPC具有更强的纠错能力和更低的开销,能够应对随着制程缩小而日益严重的读干扰和电荷泄漏问题。
可扩展存储架构与分布式系统
面对海量数据存储需求,可扩展的存储架构至关重要。软件定义存储(SDS)和计算存储是两种前景广阔的创新架构。
软件定义存储将存储控制平面与数据平面分离,通过集中式的控制平面管理分布式的存储资源,实现敏捷供应和全局优化。例如,百度提出的软件定义闪存架构通过在主机端实现FTL功能,优化了数据中心内闪存资源的利用率。
计算存储则将部分计算任务下推到存储设备执行,减少数据在存储与计算单元间的传输。带有计算功能的固态硬盘能够直接在数据存储位置进行处理,特别适用于大数据分析和机器学习等数据密集型应用。
以下图表展示了一个集成多种创新技术的现代存储系统架构:
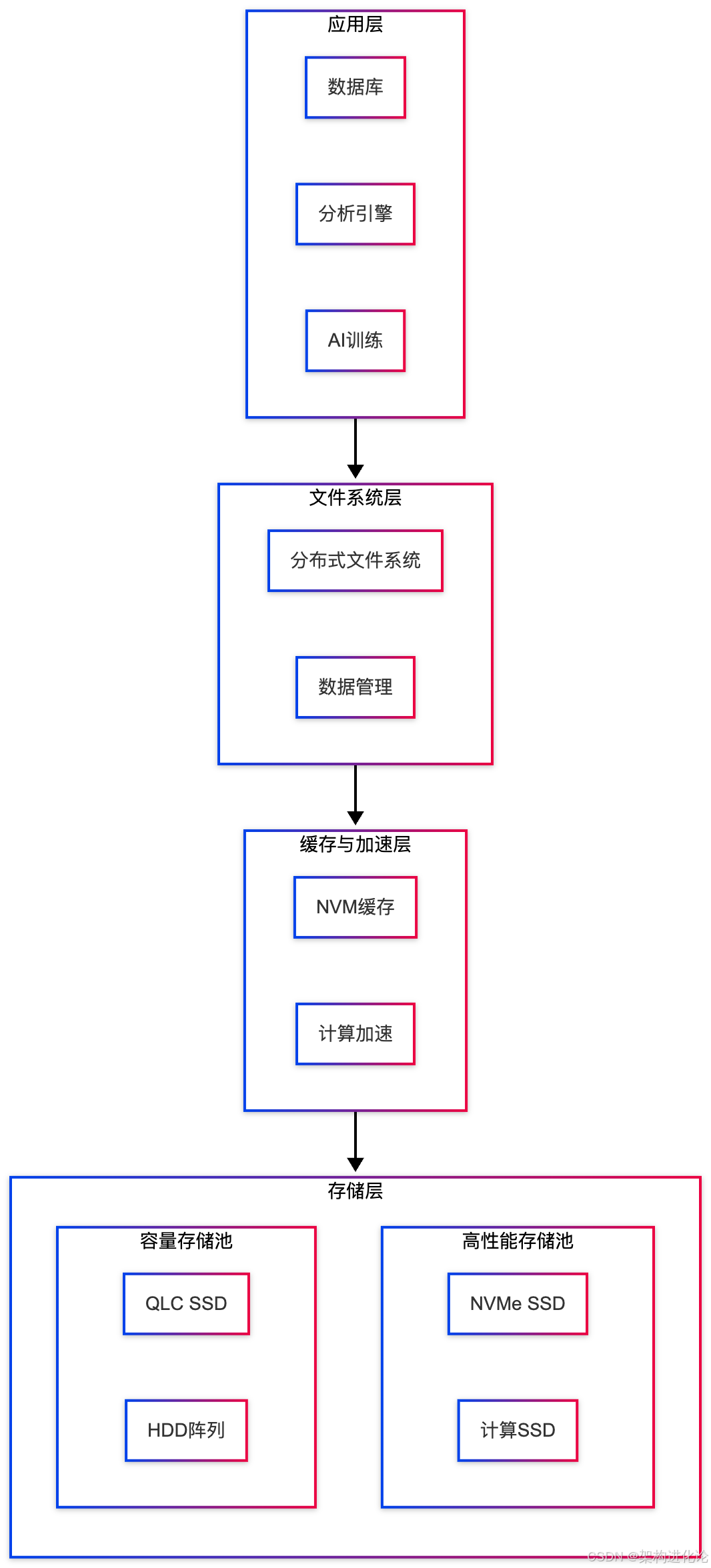
未来趋势与挑战
存储技术的发展永无止境。展望未来,多项新兴技术有望进一步推动存储架构的革新:
-
CXL(Compute Express Link):新兴互联标准,支持CPU与设备间更高效的内存语义通信,有望实现内存池化和异构计算深度融合。
-
SCM(存储级内存):如Optane PMem等产品,填补了DRAM与NAND之间的性能鸿沟,支持字节级寻址和持久化内存编程模型。
-
量子存储与生物存储:仍处于实验室阶段但潜力巨大的技术,可能彻底改变未来的数据存储方式。
同时,存储系统也面临诸多挑战:功耗问题随着存储密度提升日益凸显;可靠性保障在制程持续缩小的情况下越来越困难;安全威胁随着数据价值提高而不断增加;系统复杂度使得设计、调试和优化变得更加困难。
应对这些挑战需要算法、架构、电路和材料等多个层面的协同创新。例如,通过机器学习方法预测工作负载特征,实施更智能的数据放置和缓存策略;利用硅光互联技术突破电气接口的带宽限制;采用近似存储概念在特定应用中放松数据一致性要求以换取能效提升。
结语
SSD、PCIe和NVMe技术的协同发展彻底改变了计算机存储的面貌。从基于闪存的固态硬盘,到高速串行互联的PCIe总线,再到专为闪存设计的NVMe协议,这一技术栈的每一层都在持续演进,共同推动着存储性能的不断提升。
回顾这些技术的发展历程,我们可以清晰地看到一条从通用到专用、从软件到硬件、从单一到融合的创新路径。SSD通过复杂的FTL算法克服了闪存的物理限制;PCIe通过点对点串行架构提供了可扩展的高带宽互联;NVMe则通过多队列、低开销设计充分释放了底层硬件的性能潜力。
面向未来,随着人工智能、物联网、5G等技术的普及,数据生成和处理的需求将继续快速增长。存储系统将不再仅仅是数据的被动保管者,而是积极参与到计算过程中,成为智能数据处理的有机组成部分。存储与计算的深度融合、异构存储资源的统一管理、跨层优化的系统设计将成为未来创新的主要方向。
对于架构师和系统设计师而言,深入理解SSD、PCIe和NVMe的技术原理与设计权衡,把握存储技术的最新发展动态,将有助于构建更高效、更可靠、更适应未来需求的存储基础设施,在数据的洪流中乘风破浪,赋能数字经济的持续发展。



















 648
648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











