




数据库并发控制的演进之路
在当今互联网应用中,数据库系统面临着前所未有的并发访问压力。想象一下,在一个大型电商平台的秒杀活动中,数万用户同时查询商品库存并尝试下单,这种高并发场景下的数据一致性保障成为了系统架构设计的核心挑战。
多版本并发控制(MVCC,Multi-Version Concurrency Control)正是应对这一挑战的利器。与传统的锁机制不同,MVCC通过维护数据的多个版本,实现了读写操作的非阻塞并发执行,从根本上提升了数据库系统的并发处理能力。(扩展阅读:MySQL数据库高可用架构演进与设计实战、读写分离架构:数据访问层的演进与实践)
传统并发控制机制的困境
在深入探讨MVCC之前,让我们先回顾一下数据库并发控制技术的发展历程。早期的数据库系统主要采用两种并发控制机制:
基于锁的并发控制:
-
共享锁(S锁):用于读操作,允许多个事务同时读取同一数据
-
排他锁(X锁):用于写操作,只允许一个事务修改数据
存在问题:
-
读写冲突:读操作会阻塞写操作,写操作也会阻塞读操作
-
死锁风险:多个事务相互等待对方释放锁资源
-
并发度低:锁的粒度难以平衡性能与一致性
// 传统基于锁的并发访问示例
public class LockBasedInventory {
private int stock = 100;
private final Object lock = new Object();
// 读取库存 - 需要获取共享锁
public int getStock() {
synchronized(lock) {
return stock;
}
}
// 减少库存 - 需要获取排他锁
public boolean reduceStock(int quantity) {
synchronized(lock) {
if (stock >= quantity) {
stock -= quantity;
return true;
}
return false;
}
}
}如上代码所示,基于锁的机制虽然保证了数据一致性,但在高并发场景下性能瓶颈明显。当多个线程同时访问时,读取操作会阻塞写入操作,严重影响系统吞吐量。
MVCC核心架构解析
MVCC的基本原理
MVCC的核心思想十分优雅:为每个数据项维护多个版本,每个事务在特定时间点只能看到与其开始时间相一致的数据版本。这种设计使得读写操作可以并发执行而不会相互阻塞。
让我们通过一个例子来理解MVCC:想象一家图书馆的书籍管理。
传统锁机制:当有人借阅某本书时,这本书就会被锁定,其他人无法查阅,直到归还为止。
MVCC机制:图书馆为热门书籍准备了多个副本(版本)。读者可以同时查阅不同副本,而管理员可以在后台更新书籍内容。新读者看到的是最新版本,而正在阅读的读者继续使用他们开始阅读时的版本。
MVCC的系统架构
MVCC的实现需要数据库系统在多个层面进行协同设计,以下是其核心架构组件:
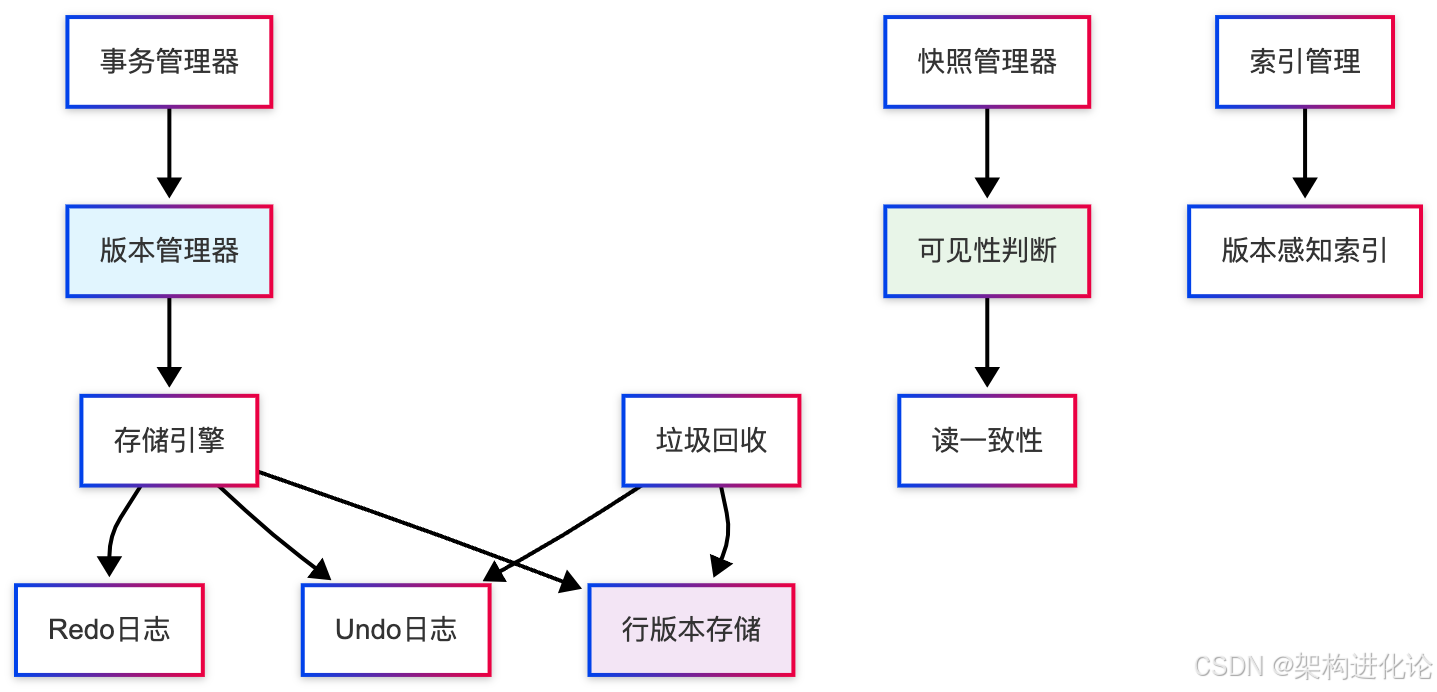
版本存储机制
MVCC的核心是版本管理,不同的数据库系统采用了不同的版本存储策略:
1. 追加式版本存储
-
新版本数据直接追加到表空间或特定版本区域
-
PostgreSQL采用此方式,每个新版本都是完整的行数据
2. 回滚段存储
-
只存储变更前的数据映像到回滚段
-
MySQL InnoDB采用此方式,通过Undo日志维护版本链(扩展阅读:MySQL事务日志深度解析:Undo Log与Redo Log的协同设计奥秘、数据库日志系统解析:从数据持久化到实时同步的架构演进)
-- MVCC版本链示例
-- 假设我们有一个简单的用户表
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50),
balance DECIMAL(10,2),
created_version BIGINT, -- 创建版本号
expired_version BIGINT -- 过期版本号
);
-- 版本链的形成过程
-- 初始版本:事务T1插入数据
INSERT INTO users VALUES (1, '张三', 1000.00, 1, NULL);
-- 更新版本:事务T2修改数据
-- 首先标记旧版本过期,然后插入新版本
UPDATE users SET expired_version = 2 WHERE id = 1 AND expired_version IS NULL;
INSERT INTO users VALUES (1, '张三', 800.00, 2, NULL);事务标识与版本可见性
每个事务在开始时都会被分配一个唯一的事务ID(XID),这个ID用于确定数据版本的可见性。MVCC通过比较事务ID和数据版本的创建/过期信息来判断某个版本对当前事务是否可见。
/**
* MVCC版本可见性判断逻辑
*/
public class MVCCVisibility {
/**
* 判断数据版本对当前事务是否可见
* @param versionCreateXid 版本创建时的事务ID
* @param versionExpireXid 版本过期时的事务ID
* @param currentXid 当前事务ID
* @param activeTransactions 活跃事务集合
* @return 是否可见
*/
public static boolean isVersionVisible(long versionCreateXid,
Long versionExpireXid,
long currentXid,
Set<Long> activeTransactions) {
// 情况1:版本由当前事务创建且未过期
if (versionCreateXid == currentXid && versionExpireXid == null) {
return true;
}
// 情况2:版本由已提交事务创建,且在当前事务开始前提交
if (versionCreateXid < currentXid &&
!activeTransactions.contains(versionCreateXid) &&
(versionExpireXid == null ||
versionExpireXid > currentXid ||
activeTransactions.contains(versionExpireXid))) {
return true;
}
// 情况3:版本由未来事务创建或已由当前事务过期
return false;
}
/**
* 模拟事务读取数据的过程
*/
public void readConsistentData() {
// 当前事务ID
long currentTransactionId = 1001;
// 活跃事务列表(尚未提交的事务)
Set<Long> activeTransactions = Set.of(1002L, 1003L);
// 数据版本链示例
List<DataVersion> versionChain = Arrays.asList(
new DataVersion("Value A", 999, 1000), // 由事务999创建,被事务1000过期
new DataVersion("Value B", 1000, 1002), // 由事务1000创建,被事务1002过期
new DataVersion("Value C", 1002, null) // 由事务1002创建,尚未过期
);
// 遍历版本链找到对当前事务可见的版本
for (DataVersion version : versionChain) {
if (isVersionVisible(version.createXid, version.expireXid,
currentTransactionId, activeTransactions)) {
System.out.println("可见版本: " + version.value);
break;
}
}
}
}
class DataVersion {
String value;
long createXid;
Long expireXid; // 使用Long以支持null值
public DataVersion(String value, long createXid, Long expireXid) {
this.value = value;
this.createXid = createXid;
this.expireXid = expireXid;
}
}MVCC的读写操作流程
读操作(SELECT)流程
在读操作中,MVCC通过快照隔离确保读取一致性:
public class MVCCReadOperation {
/**
* MVCC读操作实现
*/
public Object readWithConsistency(String key, long transactionId) {
// 1. 获取当前事务的快照信息
TransactionSnapshot snapshot = getTransactionSnapshot(transactionId);
// 2. 遍历数据的版本链
List<DataVersion> versionChain = getVersionChain(key);
// 3. 根据可见性规则找到合适的版本
for (DataVersion version : versionChain) {
if (isVisibleToSnapshot(version, snapshot)) {
return version.getValue();
}
}
// 4. 没有找到可见版本(数据已被删除或不可见)
return null;
}
private boolean isVisibleToSnapshot(DataVersion version, TransactionSnapshot snapshot) {
// 简化版的可见性判断
// 规则1:版本创建事务必须已提交且在快照之前
boolean createdCommitted = version.getCreateXid() < snapshot.getSnapshotId()
&& !snapshot.getActiveTransactions().contains(version.getCreateXid());
// 规则2:版本未被过期,或过期事务尚未提交
boolean notExpired = version.getExpireXid() == null
|| version.getExpireXid() > snapshot.getSnapshotId()
|| snapshot.getActiveTransactions().contains(version.getExpireXid());
return createdCommitted && notExpired;
}
}写操作(INSERT/UPDATE/DELETE)流程
写操作需要创建新版本并维护版本链:
public class MVCCWriteOperation {
/**
* MVCC更新操作实现
*/
public void updateWithMVCC(String key, Object newValue, long transactionId) {
// 1. 获取当前数据的版本链
List<DataVersion> versionChain = getVersionChain(key);
// 2. 找到当前事务可见的版本(即要更新的版本)
DataVersion currentVersion = findVisibleVersion(versionChain, transactionId);
if (currentVersion == null) {
throw new RuntimeException("数据不存在或不可见");
}
// 3. 创建新版本,设置创建事务为当前事务
DataVersion newVersion = new DataVersion(newValue, transactionId, null);
// 4. 将旧版本标记为过期(由当前事务过期)
currentVersion.setExpireXid(transactionId);
// 5. 将新版本添加到版本链
versionChain.add(0, newVersion); // 新版本添加到链首
// 6. 写入存储
saveVersionChain(key, versionChain);
}
}MVCC在主流数据库中的实现差异
PostgreSQL的MVCC实现
PostgreSQL采用经典的MVCC实现方式,具有以下特点:
版本存储:直接将新版本的行数据插入表中,通过xmin和xmax系统列管理版本可见性。
清理机制:使用VACUUM进程清理不可见的旧版本,防止存储空间无限增长。
-- PostgreSQL中的MVCC系统列
SELECT xmin, xmax, * FROM users WHERE id = 1;
-- xmin: 创建该版本的事务ID
-- xmax: 删除/过期该版本的事务ID(0表示未删除)MySQL InnoDB的MVCC实现
InnoDB的MVCC实现基于回滚段(Undo Log):
版本存储:在聚簇索引中存储最新版本,旧版本存储在回滚段中。
读取视图:通过Read View机制判断版本可见性。
// InnoDB Read View简化结构(基于MySQL源码)
class ReadView {
private:
trx_id_t m_low_limit_id; // 高水位:大于等于此值的事务不可见
trx_id_t m_up_limit_id; // 低水位:小于此值的事务可见
ids_t m_ids; // 创建Read View时的活跃事务列表
trx_id_t m_creator_trx_id; // 创建该Read View的事务ID
public:
/**
* 判断事务是否对当前Read View可见
*/
bool changes_visible(trx_id_t id) const {
if (id < m_up_limit_id || id == m_creator_trx_id) {
return true;
}
if (id >= m_low_limit_id) {
return false;
}
// 检查是否在活跃事务列表中
return !m_ids.contains(id);
}
};Oracle数据库的MVCC实现
Oracle采用基于回滚段的MVCC实现,具有成熟的工业级特性:
多版本读一致性:确保查询看到的是查询开始时的数据状态。
闪回查询:支持查询历史某个时间点的数据状态。
-- Oracle中的闪回查询示例
-- 查询5分钟前的数据状态
SELECT * FROM employees
AS OF TIMESTAMP (SYSTIMESTAMP - INTERVAL '5' MINUTE)
WHERE employee_id = 100;MVCC的挑战与优化策略
版本膨胀问题
MVCC最大的挑战之一是版本膨胀:随着更新操作的进行,版本链会不断增长,导致存储空间增加和查询性能下降。
解决方案:
/**
* MVCC版本垃圾回收机制
*/
public class MVCGCarbageCollector {
/**
* 清理不可见的旧版本
*/
public void purgeOldVersions(long oldestActiveTransaction) {
// 遍历所有数据的版本链
for (String key : getAllKeys()) {
List<DataVersion> versionChain = getVersionChain(key);
List<DataVersion> purgedChain = new ArrayList<>();
for (DataVersion version : versionChain) {
// 保留仍然可能被活跃事务访问的版本
if (isVersionPotentiallyVisible(version, oldestActiveTransaction)) {
purgedChain.add(version);
} else {
// 回收存储空间
reclaimStorage(version);
}
}
// 更新版本链
if (purgedChain.size() != versionChain.size()) {
saveVersionChain(key, purgedChain);
}
}
}
private boolean isVersionPotentiallyVisible(DataVersion version, long oldestActiveTransaction) {
// 如果版本由仍然活跃的事务创建或过期,则可能需要保留
return version.getCreateXid() >= oldestActiveTransaction
|| (version.getExpireXid() != null && version.getExpireXid() >= oldestActiveTransaction);
}
}索引维护的挑战
在MVCC环境中,索引需要能够正确处理多版本数据:
/**
* MVCC-aware索引实现
*/
public class MVCCIndex {
/**
* 在索引中查找对当前事务可见的版本
*/
public List<Object> indexScan(IndexQuery query, TransactionSnapshot snapshot) {
List<Object> results = new ArrayList<>();
// 遍历索引条目
for (IndexEntry entry : indexLookup(query)) {
// 获取数据版本链
List<DataVersion> versionChain = getVersionChain(entry.getKey());
// 找到可见版本
for (DataVersion version : versionChain) {
if (isVisibleToSnapshot(version, snapshot)) {
results.add(version.getValue());
break;
}
}
}
return results;
}
/**
* 索引清理:移除指向已回收版本的索引条目
*/
public void purgeIndexEntries() {
for (IndexEntry entry : getAllIndexEntries()) {
if (!isVersionChainExists(entry.getKey())) {
removeIndexEntry(entry);
}
}
}
}MVCC的创新设计与未来演进
分布式数据库中的MVCC挑战
在分布式环境中,MVCC面临新的挑战:
全局事务序:需要跨节点协调事务ID分配,保证全局一致性。
跨节点版本可见性:确保分布式事务的读一致性。
/**
* 分布式MVCC事务管理器
*/
public class DistributedMVCCManager {
/**
* 分配全局唯一的事务ID
*/
public GlobalTransactionId beginGlobalTransaction() {
// 使用分布式协调服务(如ZooKeeper)或时间戳协调器
long timestamp = getGlobalTimestamp();
int nodeId = getNodeIdentifier();
return new GlobalTransactionId(timestamp, nodeId);
}
/**
* 分布式快照隔离
*/
public DistributedSnapshot createDistributedSnapshot(GlobalTransactionId transactionId) {
// 获取所有节点的活跃事务信息
Map<Node, List<GlobalTransactionId>> allActiveTransactions =
collectGlobalActiveTransactions();
return new DistributedSnapshot(transactionId, allActiveTransactions);
}
}硬件加速的MVCC优化
利用现代硬件特性优化MVCC性能:
持久内存:使用PMEM存储版本数据,降低版本维护开销。
RDMA:在分布式环境中使用RDMA加速版本同步。
// 使用持久内存的MVCC版本存储
class PersistentVersionStore {
private:
pmem::obj::pool_base pop; // 持久内存池
public:
// 在持久内存中创建新版本
Version* createPersistentVersion(TransactionId txId, const Data& data) {
// 在持久内存中分配空间
return pop.root()->allocateVersion(txId, data);
}
// 保证版本数据的持久化
void persistVersion(Version* version) {
pmem::obj::persist(version);
}
};自适应MVCC机制
根据工作负载特征动态调整MVCC策略:
/**
* 自适应MVCC策略选择器
*/
public class AdaptiveMVCCStrategy {
public enum MVCCStrategy {
OPTIMISTIC_MVCC, // 乐观MVCC,适合读多写少
PESSIMISTIC_MVCC, // 悲观MVCC,适合写多读少
HYBRID_MVCC // 混合策略
}
/**
* 根据工作负载特征选择合适的MVCC策略
*/
public MVCCStrategy selectStrategy(WorkloadCharacteristics workload) {
double readWriteRatio = workload.getReadCount() / (double) workload.getWriteCount();
double conflictProbability = workload.getConflictRate();
if (readWriteRatio > 10.0 && conflictProbability < 0.1) {
return MVCCStrategy.OPTIMISTIC_MVCC;
} else if (readWriteRatio < 1.0 && conflictProbability > 0.3) {
return MVCCStrategy.PESSIMISTIC_MVCC;
} else {
return MVCCStrategy.HYBRID_MVCC;
}
}
}实际应用:构建基于MVCC的高并发系统
电商库存管理案例
让我们通过一个完整的电商库存管理案例,展示MVCC在实际业务中的应用:
/**
* 基于MVCC的库存管理系统
*/
public class MVCCInventorySystem {
private final MVCCDatabase database;
/**
* 库存扣减 - 支持高并发秒杀
*/
public boolean reduceStockWithMVCC(String productId, int quantity, long userId) {
// 开始事务
Transaction tx = database.beginTransaction();
try {
// 使用MVCC读取当前库存
Inventory currentInventory = database.read(Inventory.class, productId, tx);
// 检查库存是否充足
if (currentInventory.getAvailableStock() >= quantity) {
// 创建新版本库存记录
Inventory newInventory = currentInventory.copy();
newInventory.setAvailableStock(currentInventory.getAvailableStock() - quantity);
newInventory.setVersion(currentInventory.getVersion() + 1);
// MVCC写入 - 如果版本已变更则失败(乐观锁)
boolean success = database.write(Inventory.class, productId, newInventory, tx);
if (success) {
// 记录库存变更日志
InventoryLog log = new InventoryLog(productId, quantity, userId, "SALE");
database.insert(log, tx);
tx.commit();
return true;
} else {
// 版本冲突,库存已被其他事务修改
tx.rollback();
return false;
}
} else {
// 库存不足
tx.rollback();
return false;
}
} catch (Exception e) {
tx.rollback();
throw new RuntimeException("库存扣减失败", e);
}
}
/**
* 库存查询 - 无锁读取,支持高并发
*/
public int queryStock(String productId) {
// 只读事务,使用MVCC快照读取
Transaction tx = database.beginReadOnlyTransaction();
try {
Inventory inventory = database.read(Inventory.class, productId, tx);
return inventory.getAvailableStock();
} finally {
tx.close(); // 只读事务无需提交
}
}
}
/**
* 库存实体 - 支持MVCC版本控制
*/
class Inventory {
private String productId;
private int availableStock;
private int reservedStock;
private long version; // MVCC版本号
// 复制方法,用于创建新版本
public Inventory copy() {
Inventory copy = new Inventory();
copy.productId = this.productId;
copy.availableStock = this.availableStock;
copy.reservedStock = this.reservedStock;
copy.version = this.version;
return copy;
}
// getters and setters
}性能对比测试
为了展示MVCC的优势,我们进行了一个简单的性能对比测试:
public class MVCCPerformanceTest {
public static void main(String[] args) throws InterruptedException {
int threadCount = 100;
int operationsPerThread = 1000;
// 测试基于锁的库存系统
testLockBasedSystem(threadCount, operationsPerThread);
// 测试基于MVCC的库存系统
testMVCCBasedSystem(threadCount, operationsPerThread);
}
private static void testLockBasedSystem(int threadCount, int operations) throws InterruptedException {
LockBasedInventory inventory = new LockBasedInventory(10000);
long startTime = System.currentTimeMillis();
// 创建多个线程并发访问
List<Thread> threads = new ArrayList<>();
for (int i = 0; i < threadCount; i++) {
Thread thread = new Thread(() -> {
for (int j = 0; j < operations; j++) {
inventory.reduceStock(1);
}
});
threads.add(thread);
thread.start();
}
// 等待所有线程完成
for (Thread thread : threads) {
thread.join();
}
long endTime = System.currentTimeMillis();
System.out.println("锁机制耗时: " + (endTime - startTime) + "ms");
}
private static void testMVCCBasedSystem(int threadCount, int operations) throws InterruptedException {
MVCCInventorySystem inventory = new MVCCInventorySystem();
long startTime = System.currentTimeMillis();
// 创建多个线程并发访问
List<Thread> threads = new ArrayList<>();
for (int i = 0; i < threadCount; i++) {
Thread thread = new Thread(() -> {
for (int j = 0; j < operations; j++) {
inventory.reduceStockWithMVCC("product1", 1, Thread.currentThread().getId());
}
});
threads.add(thread);
thread.start();
}
// 等待所有线程完成
for (Thread thread : threads) {
thread.join();
}
long endTime = System.currentTimeMillis();
System.out.println("MVCC机制耗时: " + (endTime - startTime) + "ms");
}
}总结与展望
MVCC作为现代数据库系统的核心技术,通过多版本管理优雅地解决了并发控制中的读写冲突问题。从PostgreSQL的追加式版本存储到MySQL InnoDB的回滚段实现,不同的MVCC实现方案各有优劣,但核心思想都是通过维护数据的历史版本来实现非阻塞的并发访问。
MVCC的技术优势
-
高并发性能:读写操作不相互阻塞,大幅提升系统吞吐量
-
一致性读取:事务看到的是一致的快照视图,避免脏读和不可重复读
-
降低死锁概率:减少了对锁的依赖,降低了死锁发生的可能性
-
灵活的隔离级别:支持从读已提交到可序列化的多种隔离级别(扩展阅读:MySQL事务隔离级别:从并发困境到架构革新、多租户数据隔离架构:从基础隔离到智能自治的演进之路)
未来发展趋势
随着硬件技术和新应用场景的出现,MVCC技术仍在持续演进:
异构计算:利用GPU、FPGA等加速版本管理和垃圾回收
云原生架构:在微服务和Serverless环境中的轻量级MVCC实现
AI优化:使用机器学习预测工作负载特征,动态调整MVCC参数
新硬件利用:持久内存、RDMA等新技术为MVCC带来新的优化可能
MVCC的创新设计不仅体现了数据库技术的精妙之处,更为构建高并发、高可用的互联网应用提供了坚实的技术基础。作为架构师,深入理解MVCC的原理和实现,对于设计高性能的数据密集型应用至关重要。
在未来的技术演进中,MVCC将继续在分布式数据库、云原生架构和新硬件环境中发挥核心作用,为构建下一代互联网基础设施提供关键技术支撑。



















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











