




 本文介绍了使用Python进行图片爬取的过程,从百度图片的旧版接口获取裂缝检测相关图片,再到针对特定网址的图片下载。作者通过正则表达式提取图片URL,并使用Session处理会话,解决无Cookies问题,最终成功下载所需图片。过程中遇到了动态加载、网址不完整等问题,通过不断调整和优化实现了完整的爬取流程。
本文介绍了使用Python进行图片爬取的过程,从百度图片的旧版接口获取裂缝检测相关图片,再到针对特定网址的图片下载。作者通过正则表达式提取图片URL,并使用Session处理会话,解决无Cookies问题,最终成功下载所需图片。过程中遇到了动态加载、网址不完整等问题,通过不断调整和优化实现了完整的爬取流程。
”明月如霜,好风如水,清景无限 “
最近,因为毕设的临近。更新的很少,不过文远下一篇资料上也差不多都找好了。前天,有位老哥因为毕设要做裂缝检测,但是没裂缝数据。所以叫文远爬一下。文远当然是选择安排了。
壹
百度搜图图片爬取
这个我就不想多说了,毕竟网上一搜一大把,但是综合起来有个要点就是。用旧版本的百度爬取会方便一些,因为旧版百度有页码,可以翻页。但是新版百度是下拉,因此都是动态加载的。
结果
搜索的关键词是裂缝检测。结果后面有很多的垃圾图片(baidu fw)
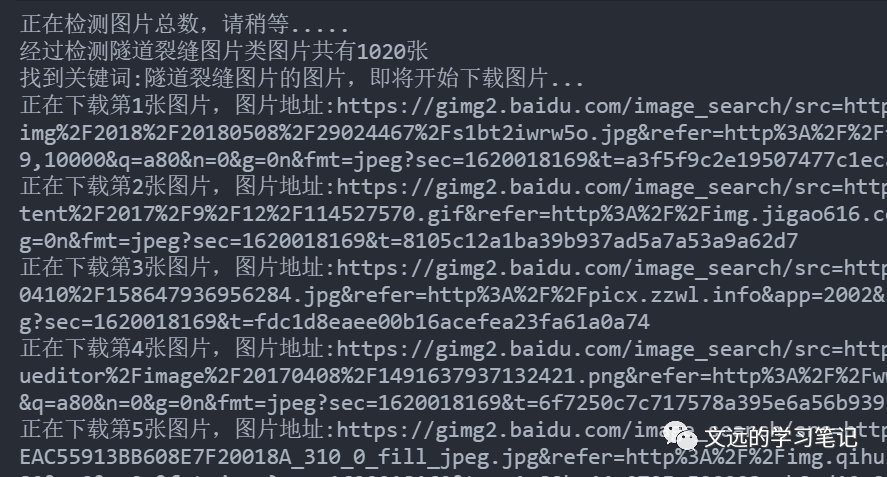

贰
直接上网址,这个好像没有被墙:
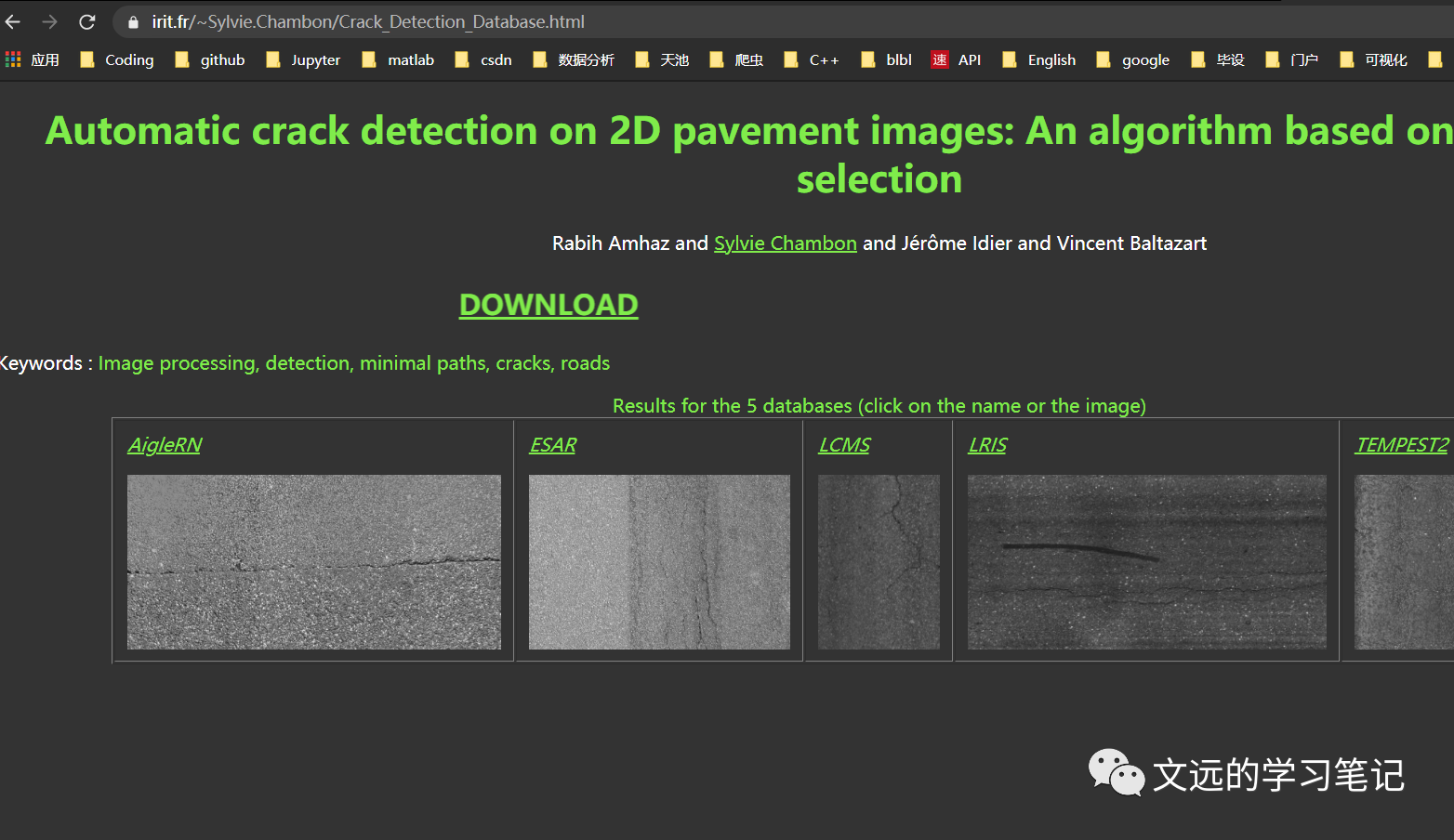
原以为是正常的网站,直接爬:
import requests
# from lxml import etree
import re
import os
url = "https://www.irit.fr/~Sylvie.Chambon/AigleRN_GT.html"
url = 'https://www.irit.fr/~Sylvie.Chambon/AigleRN_noGT.html'
url = 'https://www.irit.fr/~Sylvie.Chambon/ESAR_GT.html'
url = 'https://www.irit.fr/~Sylvie.Chambon/ESAR_GT.html'
url = 'https://www.irit.fr/~Sylvie.Chambon/LCMS_GT.html'
url = 'https://www.irit.fr/~Sylvie.Chambon/LCMS_noGT.html'
url = 'https://www.irit.fr/~Sylvie.Chambon/LRIS_GT.html'
url = 'https://www.irit.fr/~Sylvie.Chambon/LRIS_noGT.html'
url = 'https://www.irit.fr/~Sylvie.Chambon/TEMPEST2_GT.html'
url = 'https://www.irit.fr/~Sylvie.Chambon/TEMPEST2_noGT.html'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36',
}
response = requests.get(url=url,headers= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3457
3457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









