




 本文介绍了一种基于C++的密度聚类算法实现,通过定义核心点、边界点和密度等概念,利用集合运算的方法对数据进行分类。核心点是其周围存在较多其他点的点,边界点则相反,而密度是在一定区域内的点个数。算法通过处理核心点及其周围点来完成分类。
本文介绍了一种基于C++的密度聚类算法实现,通过定义核心点、边界点和密度等概念,利用集合运算的方法对数据进行分类。核心点是其周围存在较多其他点的点,边界点则相反,而密度是在一定区域内的点个数。算法通过处理核心点及其周围点来完成分类。
C++实现密度聚类算法
主要利用集合运算的方法实现
原理简介
参考周华志《机器学习》。下面是一些概念,可能与原文有很大出入。
核心点:
若一个点的周围一定区域(笔者采用的是矩形区域)内存在的其他点较多的,就称为核心点。
边界点与其他:
若一个点的周围一定区域(笔者采用的是矩形区域)内存在的其他点较少。通过直观想象,也可以知道这个点不在中心,那就只能是边界上的点或其他。
一定区域:
在这里我定义为以所观察点为中心的定长定宽的矩形区域。(方便数组操作)
密度:
在一定区域内的点个数(除自己外)
判定密度:
用于判定该点是否为核心点。
分类大致方法:
边界点与其他点:有的在核心点的一定区域内,就会自动随着核心点被分类。有的并不在,那么这种点实际上就是一种噪声,所以会被忽视,不会被分类。综上,边界点与其他点不需要直接操作,躺着就好了。
核心点:将离得近的核心点,以及他们携带的一定区域内的点,归为一类,分类的个数受一定区域与判定密度的影响。
具体实现
输入样本集合。
//以下定义的量均为与样本集合相同的类型
定义核心点集合,获得样本集合中的核心点。
定义当前处理集合,并复制样本集合所有点。
定义上一步处理集合,并复制样本集合所有点。
定义处理列表
当当前处理集合非空时,开始外循环
取出核心点集合中的第一个点(顺序随便,这里取第一个是先行后列的顺序)
将此点加入到处理列表
-----当处理列表非空时,开始内循环
取出处理列表中的第一个点
生成该点的在样本集合中的一定区域的子集
将当前处理集合与处理列表中的这个点去掉,防止重复。
---------------若密度达到判定密度
让处理列表并上(子集与当前处理集合的交)
当前处理集合去掉(子集与当前处理集合的交)
// 这里去掉的,就是一个类的,接下来会拿回来。
---------------结束
-----内循环结束
分类好的样本=上一步处理集合去掉当前处理集合剩下的点,即将删去的同类全部拿回来
//收尾处理
核心点集合去掉分类好的样本
上一步处理集合=当前处理集合
处理列表置空
外循环结束
代码实现
实现效果如下。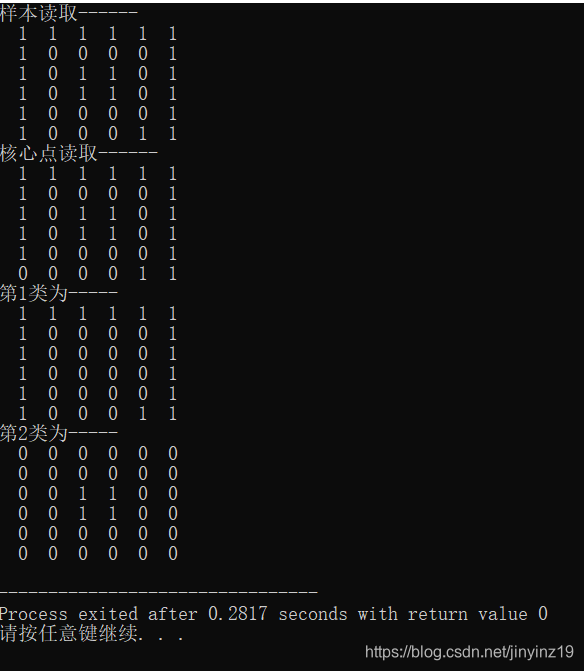
源码附在下面,只有一个cpp,可以直接编译后运行。里面定义了一个bool_set类,封装了集合间的运算。

















 4760
4760





 到【灌水乐园】发言
到【灌水乐园】发言







